# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
解决跨域小样本物体检测问题,入选ECCV 2024。
最新研究认为目前大多数跨域小样本学习方法均集中于研究分类任务而忽略了目标检测。
来自复旦大学、苏黎世联邦理工学院、INSAIT、东南大学、BOE科技的研究团队,提出了一个用于算法评测的CD-FSOD数据集及用于衡量领域差异的style、ICV、IB数据集指标。
对现有目标检测算法进行了广泛实验评估。
除此之外,团队还提出了一种名为CD-ViTO的新方法,基于优化一个在经典FSOD上达到SOTA的开放域物体检测器而得到。
CD-ViTO在多数情况下优于基准,成为该任务的新SOTA。
目前该项研究已入选ECCV 2024,所有数据集、代码、以及相关资源都已开源。

跨域小样本学习任务(Cross-Domain Few-Shot Learning,CD-FSL)解决的是源域与目标域存在领域差异情况下的小样本学习任务,即集合了小样本学习与跨域两个任务的难点问题:
大多数的现有方法均集中于研究分类问题,即Cross-Domain Few-Shot Classification, 但是同样很重要的物体检测任务(Object Detection,OD)却很少被研究,这促使了研究团队想要探究OD问题在跨域小样本的情况下是否也会遭遇挑战,以及是否会存在跟分类任务表现出不同的特性。
与CD-FSL是FSL在跨域下的分支类似,跨域小样本物体检测(Cross-Domain Few-Shot Object Detection,CD-FSOD)同样也可以堪称是FSOD在跨域下的分支任务。
所以研究团队先从经典的FSOD开始分析。大多数的FSOD方法都可以被粗略地划分为:
然而近期出现了一个名为DE-ViT的开放域方法,通过基于DINOv2构建物体检测器同时在FSOD以及开放域物体检测(OVD)上都达到了SOTA的效果,性能明显高于其他的FSOD方法,因此这引发了团队思考:
现有的FSOD方法,尤其是SOTA的DE-ViT open-set detector能不能在跨域的情况下仍表现优异?
如果不能,什么是难点问题,以及是否有办法能够提升open-set detector的性能?
先用下图来揭示一下问题的答案:
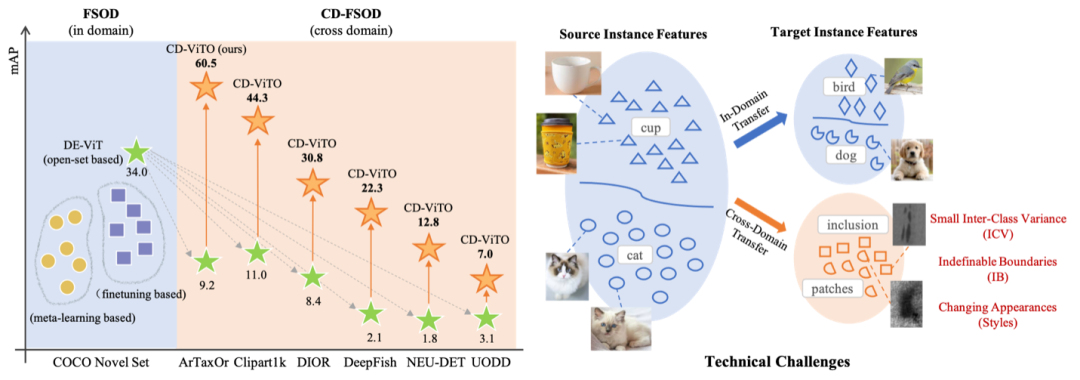
如上左图所示,哪怕是SOTA的open-set detector DE-ViT(绿色星形)在跨域泛化的情况下性能也会出现急剧下降。
而本文研究团队基于DE-ViT搭建的CD-ViTO方法 (橙色星形)能够使原本性能下降的模型得以进一步提升。
而右图,展示了相比于in-domain的小样本物体检测,跨域小样本物体检测通常会面临三个问题:
1)目标域T的类间距离(ICV)通常较少;
2)目标域的图像可能会出现前景与背景边界模糊(Indifinable Boundary,IB);
3)目标域T得图像相较于源域S而言视觉风格(style)发生变化。
ICV、IB、Style也成为了研究人员用于衡量不同数据集在跨域下的特性。
下面首先总结一下CD-ViTO团队在解答两个问题的过程中的主要工作及贡献:
Benchmark, Metrics, and Extensive study
为了回答问题1,即研究现有的物体检测器能不能泛化至跨域小样本物体检测任务中:
研究人员研究了CD-FSOD任务下的三个影响跨域的数据集特性:Style, ICV, IB;提出了一个CD-FSOD算法评测数据集,该数据集包含多样的style,ICV,IB;对现有物体检测器进行了广泛研究,揭示了 CD-FSOD 带来的挑战。
New CD-ViTO Method
为了回答问题2,即进一步提升基础DE-ViT在CD-FSOD下的性能,研究团队提出了一个新的CD-ViTO方法,该方法提出三个新的模块以解决跨域下的small ICV、indefinable boundary以及changing styles问题。
CD-FSOD数据集&Extensive Study
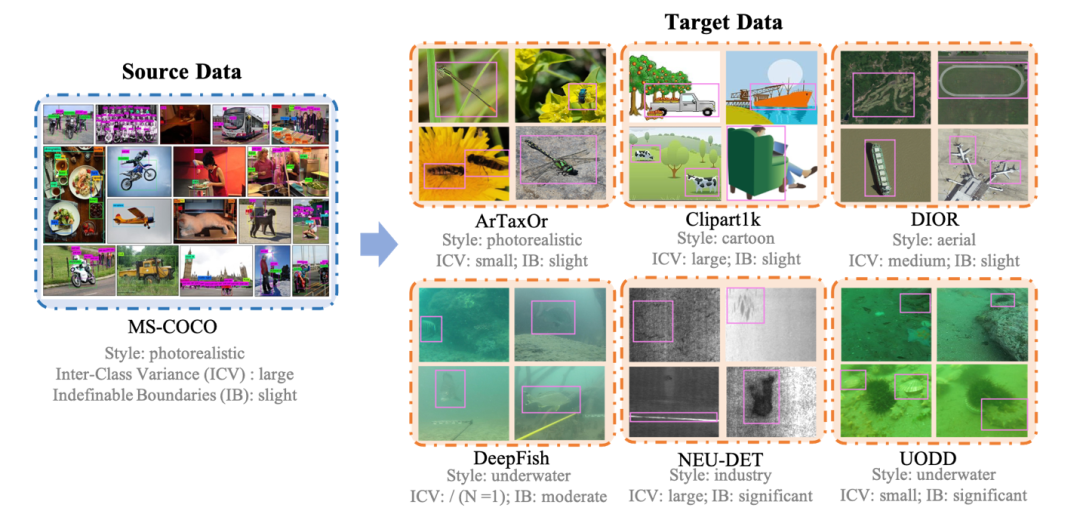
下图为研究团队构建的CD-FSOD数据集,该数据集以MS-COCO作为源域S,以ArTaxOr、Clipart1K,DIOR,DeepFish,NEU-DET,UODD作为六个不同的目标域T;
团队也分析并在图中标注了每个数据集的Style、ICV、IB特征,每个数据与数据之间也展现了不同的数据集特性。
所有的数据集都整理成了统一的格式,并提供1shot、5shot、10shot用于模型测评。
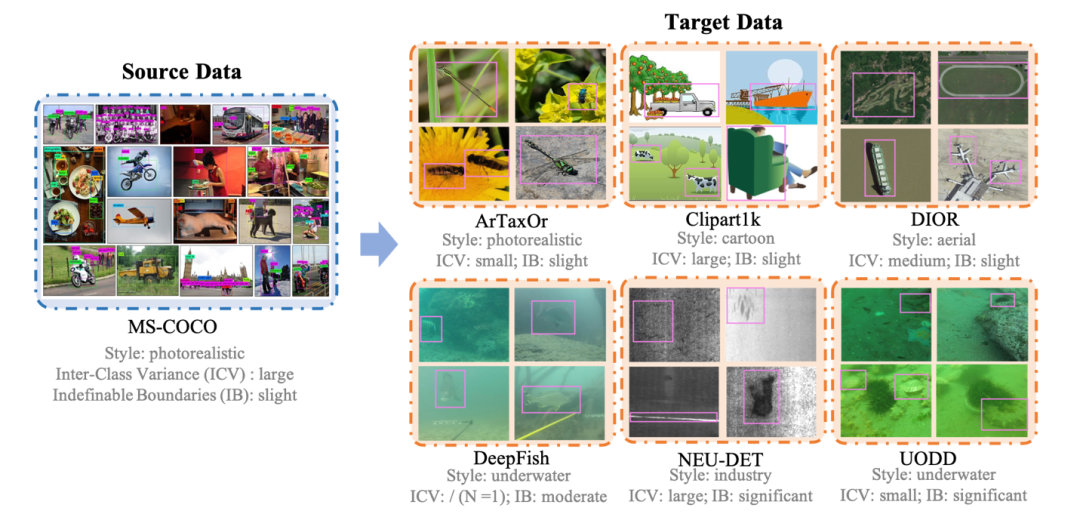
数据集更多的介绍,比如数据类别数,样本数等可以在论文中找到细节。
Extensive Study
团队对现有的四类目标检测器进行了实验,包括:
其中“-FT”表示团队用目标域T的少量样本对方法进行了微调。
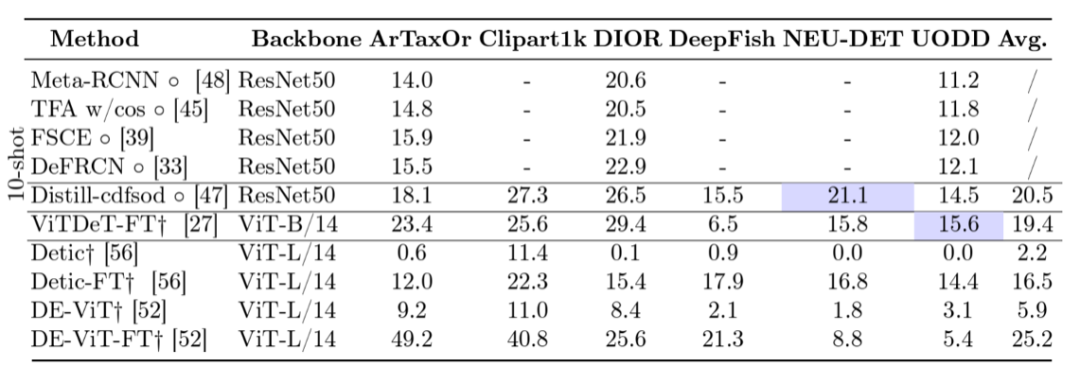
团队结合实验结果对这个任务以及相关方法展开了详细的分析,主要有以下这几点结论:
详细的分析就不在这里展开了,感兴趣的朋友可以看看文章。
本文方法整体框架结构图如下所示:
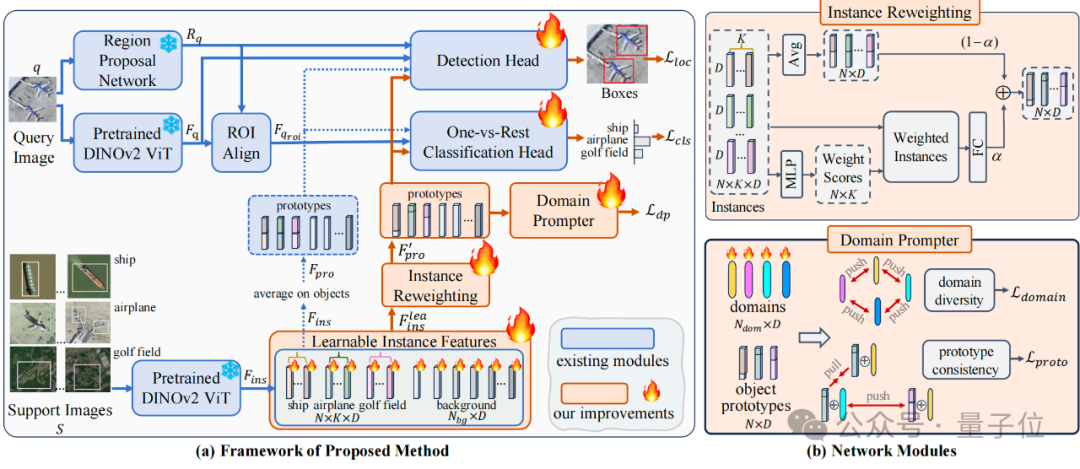
整体来看,本文研究团队的方法是基于DE-ViT搭建的(图中蓝色块), 首先将DE-ViT方法简化为图中所示的几个模块,主要包括Pretrained DINOv2 ViT, RPN,ROI Align, Instance Features, Dection Head,One-vs-Rest Classification Head。
DE-ViT的核心想法是利用DINOv2提取出来的视觉特征对query image boxes与support images中所构建出来的类别prototypes进行比较,从来进行分类和定位。
基于DE-ViT方法,团队提出了三个新的模块(图中黄色块)以及finetune(图中火苗)以搭建CD-ViTO。如前所述,每个模块都各自对应解决CD-FSOD下存在的一个挑战。
Learnable Instance Features
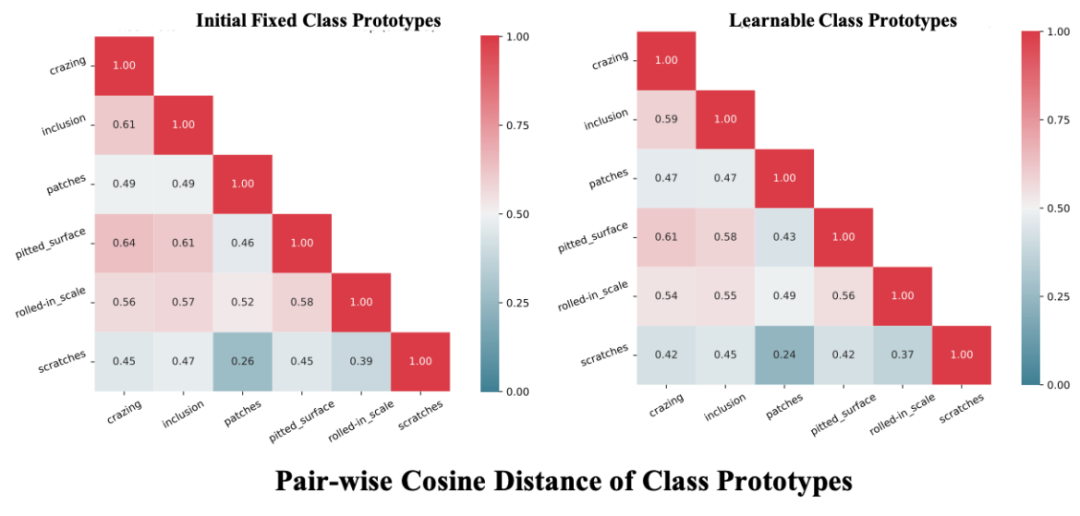
原本的DE-ViT首先利用DINOv2获取instance features,然后简单对同类特征求和的方式得到support的class prototypes。
然而在面对目标域类别之间可能很相似的情况,直接使用这种预训练的模型所提取出的特征会导致难以区分不同类别。
因此团队提出将原本固定的特征设置为可学习参数,并通过结合finetune方法将其显式地映射到目标域类别中,以此增加不同类之间的特征差异程度,缓解ICV问题。
团队对比了使用该模块前后的类间cosine相似性,结果说明他们的模块可以降低类间相似度,从而提升ICV。
Instance Reweighting Module
图像模糊边界的问题本身很难得到解决,这个模块的主要想法是通过学习可调整的权重给不同质量的样本赋不同的权重,使得严重IB的图像被抑制,没有或者轻微IB地图像被鼓励。
模块的设计如框架图右上所示,主要包含一个可学习的MLP。
同样的,团队也对该模块做了可视化分析,他们按照所分配到的权重从高到低给图像排序,得到如下结果。从图中可见,前后景边缘模糊的图像得到的权重要低于边缘清晰的图像。

Domain Prompter
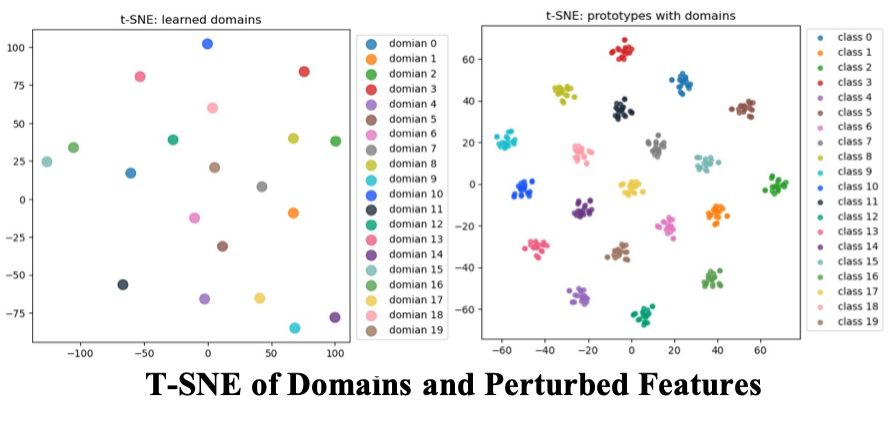
Domain Prompter的设计主要是希望方法能够对不同的domain鲁棒,如框架图右下所示,在原有object prototype的基础上,团队额外引入数量为$N_{dom}$维度为D(等于prototype维度)的虚拟domains变量作为可学习参数。通过学习和利用这些domains,他们希望最终达到:
1) 不同domain之间相互远离,增加多样性 (domain diversity loss)
2) 添加不同domain至同一类别prototype所生成得到的两个变种仍为正样本,添加不同domain至不同类别prototype生成得到的两个变种为负样本 (prototype consistency loss)
两个loss与finetuning所产生的loss叠加使用进行网络的整体训练。
如下T-SNE可视化图说明学习到的domains之间相互远离;叠加不用domains至class prototype不影响语义变化。
作为简单但有效的迁移学习方法,团队也采用了在目标域T上对模型进行微调的思路,论文附录部分有提供不同finetune策略的不同性能表现,团队主方法里采用的是仅微调两个头部。
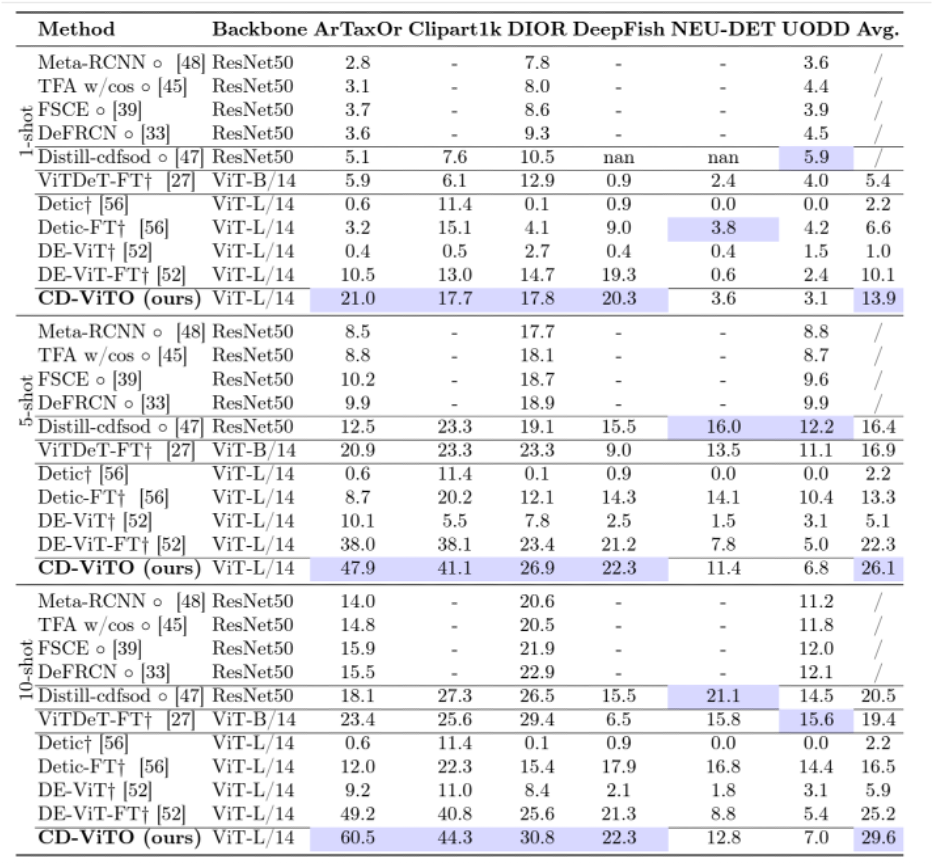
团队在1/5/10shot上与其它方法进行了对比实验。
实验说明经过优化后的CD-ViTO方法在大多数情况下都优于其它的对比方法,达到了对基本DE-ViT的有效提升,构建了这个任务的新SOTA。
文章来源于“量子位”,作者“CD-ViTO团队”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
