# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
准确的统计数据、时效性强的信息,一直是大语言模型产生幻觉的重灾区。
知识是现成的,但学是不可能学的。
并非此身惰怠,只因现实太多阻碍。
对于这个问题,谷歌在近日推出了自己筹划已久的大型数据库Data Commons,以及在此基础上诞生的大模型DataGemma。

论文地址:https://docs.datacommons.org/papers/DataGemma-FullPaper.pdf
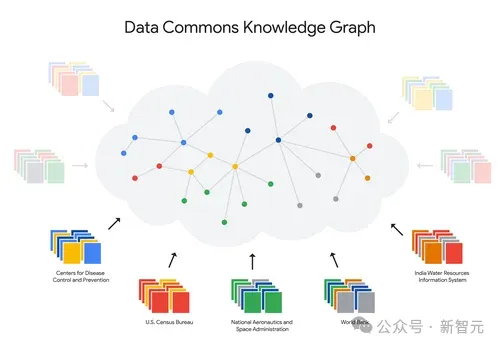
Data Commons是一个庞大的开源公共统计数据存储库,包含来自联合国 (UN)、疾病控制与预防中心 (CDC) 、人口普查局、卫生部、环境机构、经济部门、非政府组织和学术机构等可信来源的大量统计数据。
目前,整个语料库包含超过2500亿个数据点和超过2.5万亿个三元组。
数据有了,模型要怎么处理?
本文提出了一种将LLM桥接到数据的通用架构,并探讨了需要解决的三个问题。
首先,LLM必须学会在适当的时机选择,是使用存储在模型参数中的知识,还是从外部获取信息。
当然了,关于何时查询外部源这件事,需要LLM学到自己的参数里,这可以采用多种机制来实现。
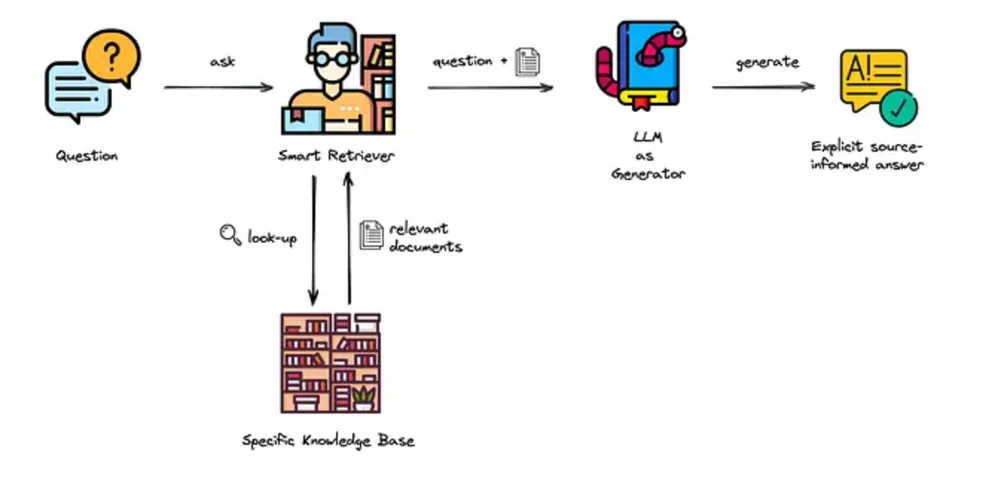
其次,需要决定应该从哪个外部源查询所需的信息,因为可用的信息源可能很多而且是动态的。在本文中,作者直接使用单一外部信息源来包含大量数据源。
最后,一旦明确了需要哪些外部数据,LLM就需要生成一个或多个查询来获取这些数据。
一般来说,不同的来源会产生不同类型的数据,如果LLM还要专门去学习各种API就有点麻烦了。因此,作者开发了用于外部数据和服务的单一通用API。
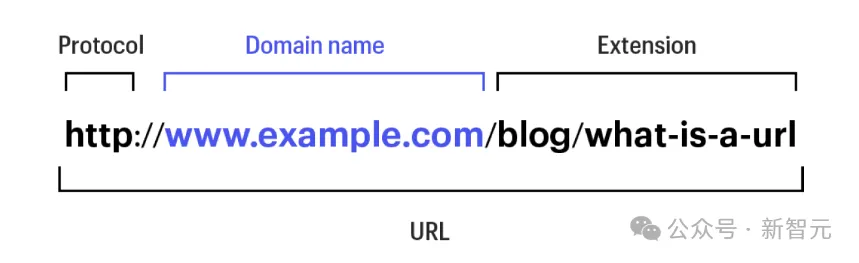
API的灵感来自于Robert McCool在1993年设计的URL参数编码接口,虽然简单,却经受住了时间的考验,是目前在网络上最接近通用API的接口。
作者使用自然语言来表达查询,返回的答案可以用mime-type来增强,以允许非文本答案。
搞定了这些,一个能够充分利用最新最全外部数据的「AI统计学家」(或者叫统计学魔术师)就诞生了。

对于Data Commons这么庞大的数据源,想要被LLM正常使用,需要面对一些现实的挑战:
1. 与统计事实相关的用户查询可能涉及一系列逻辑、算术或比较运算。
比如「世界上排名前5的二氧化碳排放国是哪些国家?」;更复杂一点的比如「加利福尼亚州是世界上最大的经济体吗?」(这里面暗含了所比较的实体——加利福尼亚州与其他国家/地区相比,而不是美国各州);或者「煤发电量高的美国各州,慢性阻塞性肺病发病率也很高吗?」(这涉及到实体和指标之间的比较)。
2. 公共统计数据包含多种模式和格式,通常需要相当多的背景上下文才能正确解释。
之前的工作利用了两种方法来缓解这些问题:使用工具和检索增强生成(RAG)。
前一种方法会调整LLM来生成一种标记语言,能够将自然文本与对外部工具的函数调用穿插在一起。为了对抗幻觉,工具可能会查询数据库或搜索引擎。
而在RAG中,辅助检索系统从大型语料库中识别与用户查询相关的背景知识,然后用这些知识来增强用户的查询。
本文作者以谷歌开源的Gemma和Gemma-2模型为基础,分别利用检索交错生成(RIG)和RAG微调出两个新的版本。
开源模型:https://huggingface.co/collections/google/datagemma-release-66df7636084d2b150a4e6643
Data Commons的数据共享涉及两项创新。
首先,研究人员花了数年时间访问大量公开可用的数据集,追踪数据背后的假设,并使用Schema.org(一种用于编码结构化数据的开放词汇表)对它们进行规范化,最终形成了一个包含所有数据的通用知识图谱。
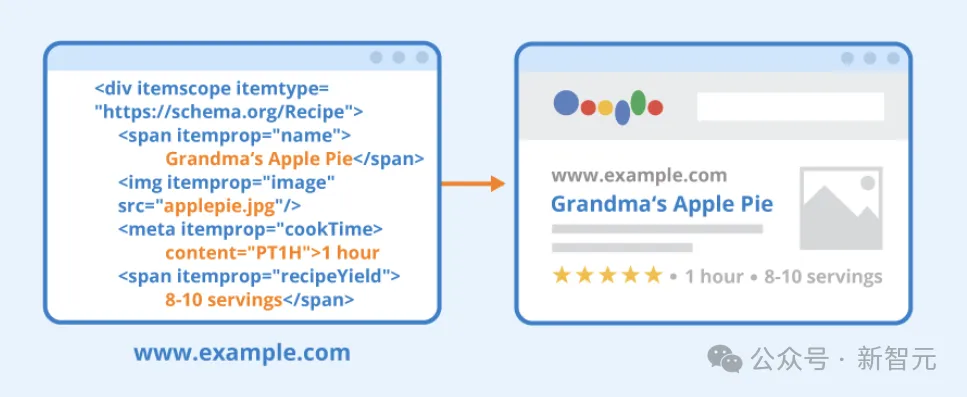
其次,研究人员使用LLM创建一个自然语言界面,允许用户用通用语言提出问题,并通过图表等方式来探索庞大的数据库。
需要明确的是,LLM只是将查询转换为Data Commons中的词汇表,不会与底层数据交互,也不会生成输出,因此不必担心出现幻觉之类的问题。
当前的方法是利用这个自然语言接口,教导LLM何时以及如何与Data Commons的接口进行通信。
对齐方面,作者采用LIMA(一种指令调整和强化学习方法),遵循少即是多的原则,利用数量少但质量很高的一组示例,使最终任务与用户偏好保持一致。
接下来介绍将LLM与Data Commons连接的两种不同方法:
RIG
检索交错生成 (RIG),是一种受使用工具启发的方法,将LLM进行微调以生成自然语言数据共享查询,然后,多模型管道将此查询转换为结构化数据查询,用于从Data Commons数据库检索答案。
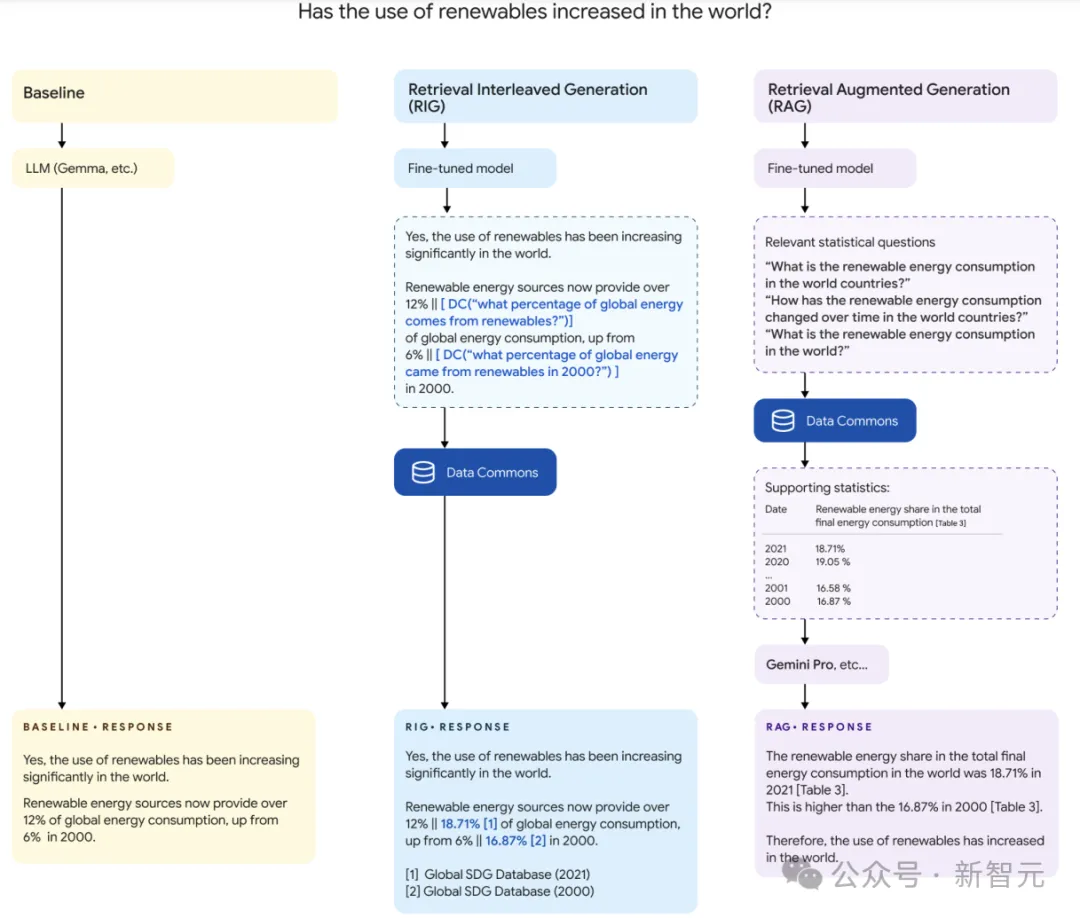
如上图所示,这里扩展了RIG管道的步骤。首先是经过微调以生成自然语言查询的模型;接着是后处理器,将自然语言查询转换为结构化数据查询;最后一个组件是查询机制,从Data Commons检索统计答案并使用LLM生成。
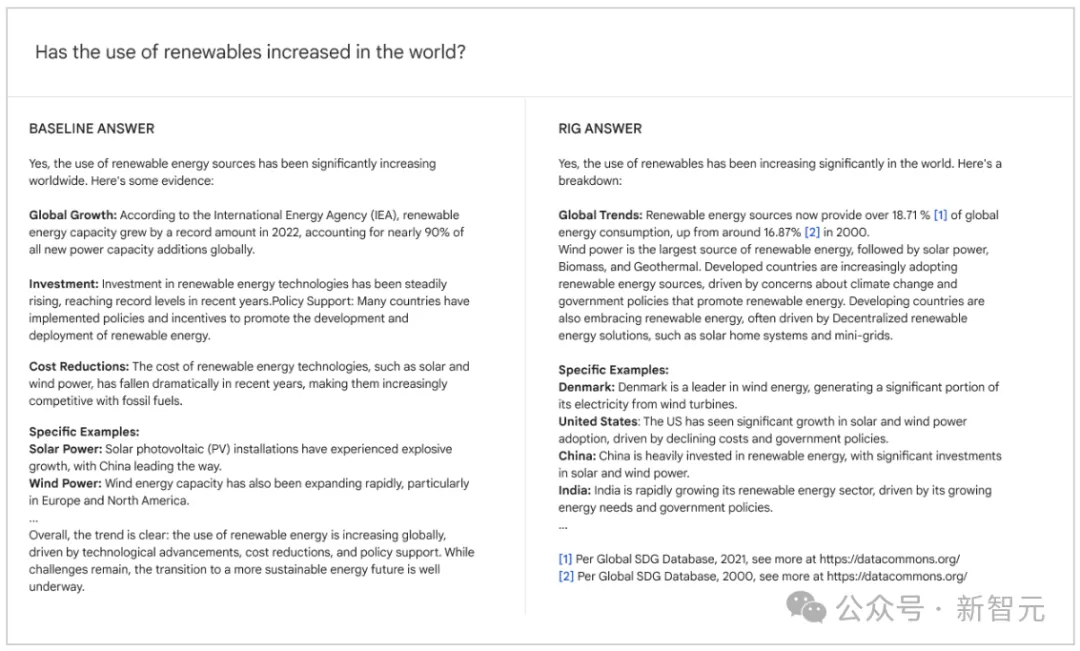
当向LLM提出统计查询时,通常会生成包含数字答案的文本(如下图所示)。这时可以根据数字(LLM-SV)相关的上下文,在Data Commons数据库中匹配最相关的值(DC-SV),作为事实检查机制一起返回给用户。
研究人员选择了大约700个用户查询(对应不同的统计问题)。
对于每个问题,都会从基本模型中选择带有统计数据的答案(约400个),然后将这些响应提供给功能更强大的LLM(Gemini 1.5 Pro),指示它围绕统计数据点引入自然语言数据共享调用。
所使用的提示包含三个示例作为指导,要求注释出统计值和单位,还要指示数据共享调用包括地名、指标和日期等。最后会进行人工审查,并手动重写不符合要求的数据共享调用。
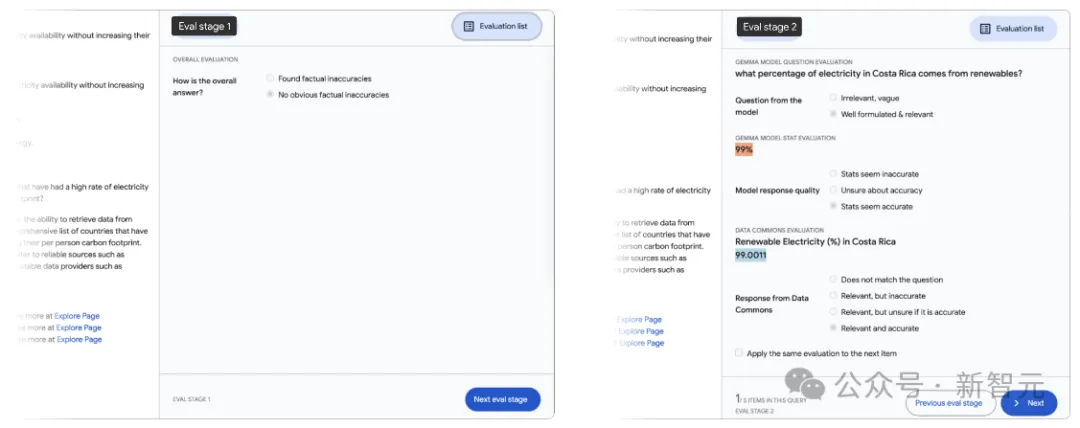
为了评估单个测试查询响应,这里需要子字符串级别的详细反馈。研究人员采用了上图所示的可视化工具。
人工评估人员能够浏览所有查询,并检查每个查询响应中的所有Data Commons调用,首先快速检查是否存在任何明显的事实不准确之处,然后对响应中存在的每项统计数据进行评估。
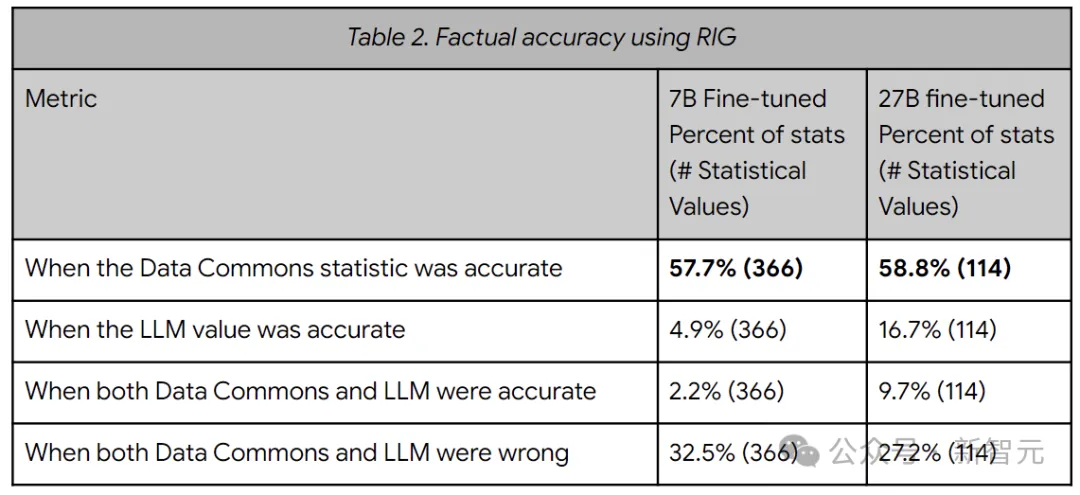
上表显示了RIG方法的事实准确性指标(Data Commons中的统计数据与101个查询中的LLM响应进行比较的情况)。总体而言,RIG方法提高了真实性,从5-17%提高到约58%。
RAG
RAG管道同样包含多个组件。首先,用户查询被传递到一个小型的、经过微调的LLM,它会生成与用户查询相关的自然语言查询;然后,通过Data Commons的自然语言接口来获取相关的表;最后,将原始用户查询和检索到的表交给长上下文LLM(Gemini 1.5 Pro)。
原始用户查询以及结果表可能会相当长。例如,比较查询可能包括来自美国所有50个州或全球194个国家的多个表的多年数据。
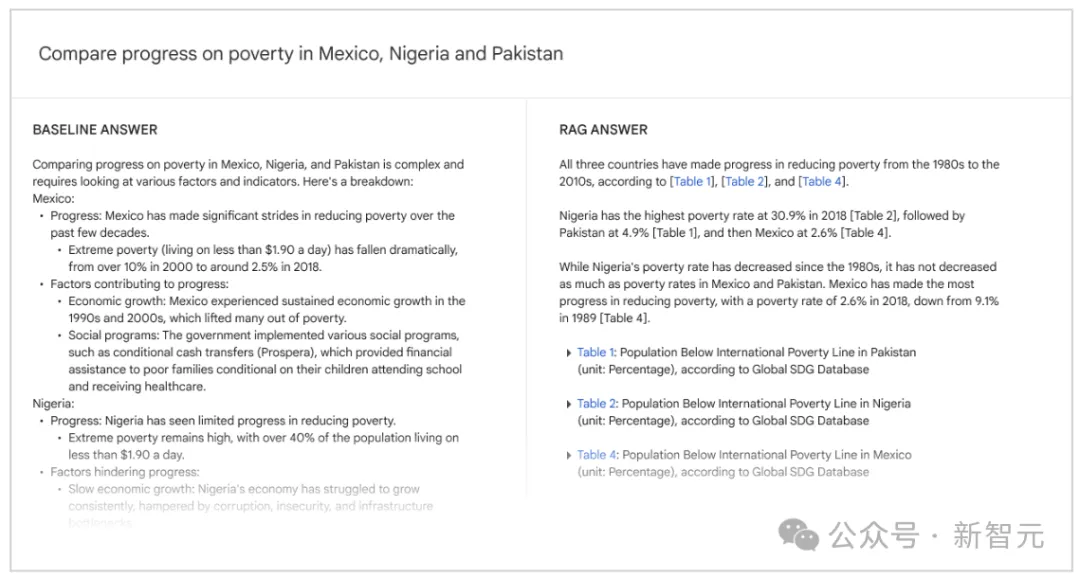
在综合查询集中,平均输入长度为38,000个token,最大输入长度为348,000个token。由于输入量很大,因此必须使用长上下文LLM,用户响应如上图所示。
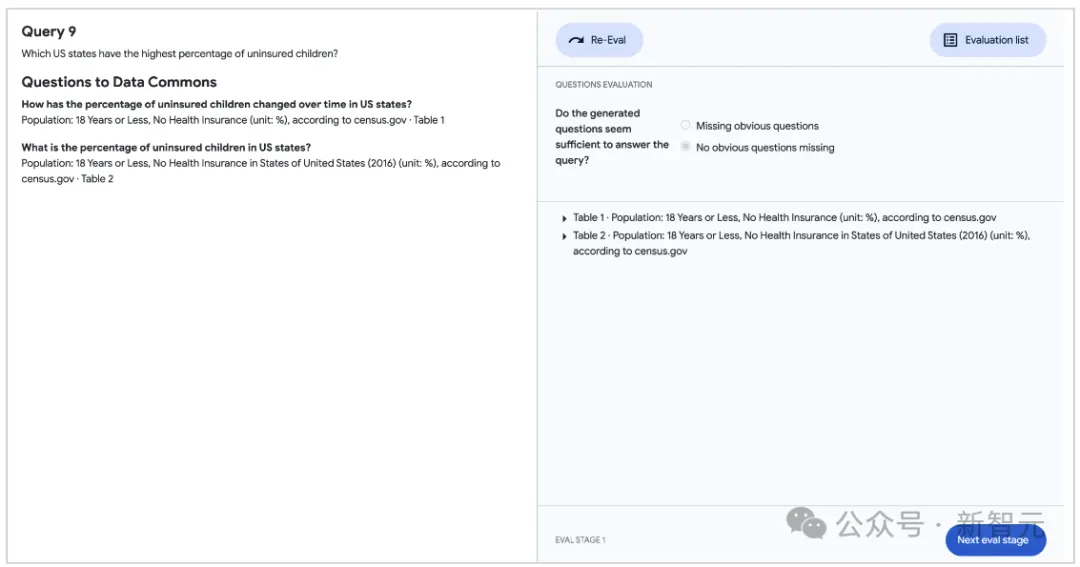
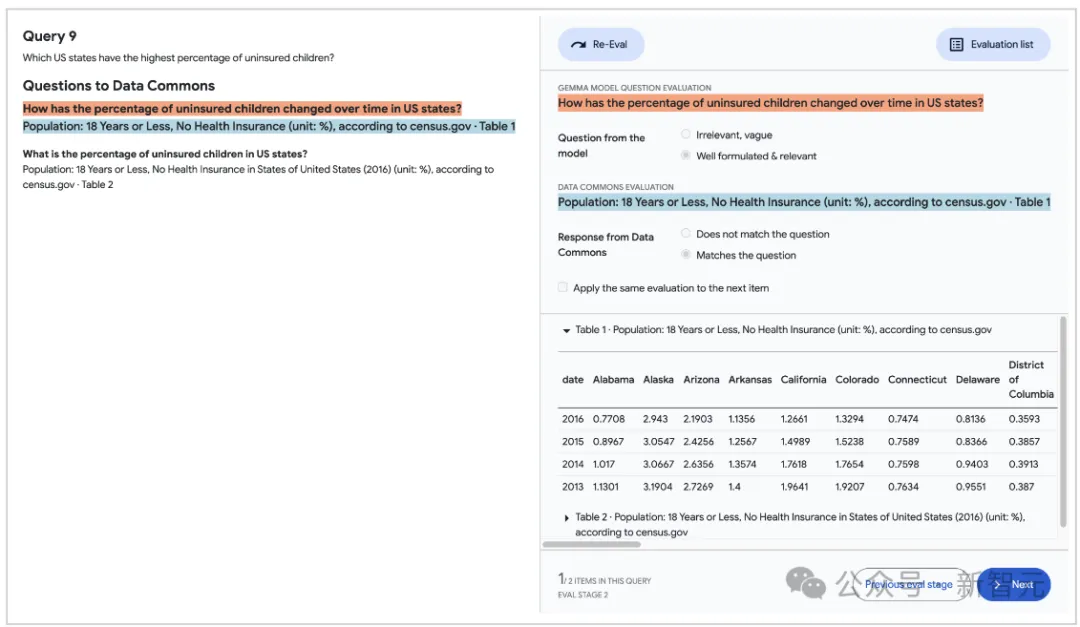
对于RAG方法,人类评估者评估LLM生成的细粒度问题及其相应的数据共享响应的质量。首先验证是否生成了足够且相关的问题来解决用户查询(上图);然后评估每个单独问题的质量及其相应的数据共享响应(下图)。
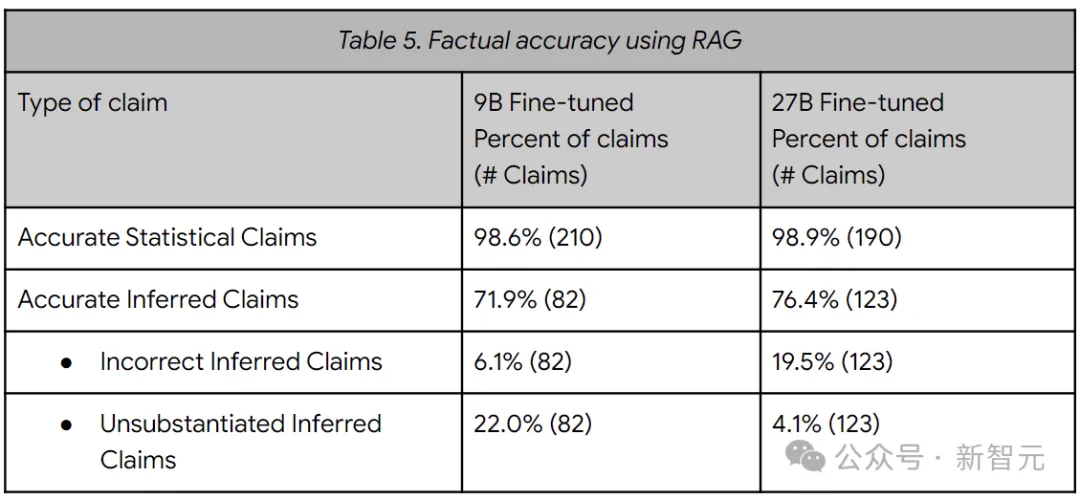
下表的结果表明,LLM在引用数字时通常是准确的 (99%),当根据这些说法进行推论时,准确性会下降,在6-20%的时间内得出错误的推论。
参考资料:
https://venturebeat.com/ai/datagemma-googles-open-ai-models-mitigate-hallucination-on-statistical-queries/
文章来自于微信公众号“新智元”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
