# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
不久之前,OpenAI 发布了 o1 系列模型,其强大的推理能力让我们看见了 AI 发展的新可能。近日,OpenAI 著名研究科学家 Noam Brown 一份 5 月的演讲上线网络,或可揭示 o1 背后的研究发展脉络。
在这个题为「关于 AI 规划力量的寓言:从扑克到外交」的演讲中, Brown 介绍了扑克、围棋和外交等游戏领域的研究突破,并尤其强调了搜索/规划算法在这些成就中的关键作用。之后,他也指出了搜索/规划研究在改进机器学习模型方面的潜在未来。
Noam Brown,如果你还不熟悉这个名字:他是 OpenAI 的一位著名研究科学家,主攻方向是推理和自博弈,曾参与创造了首个在双玩家和多玩家无限注德州扑克上击败人类顶级职业玩家的 AI:Libratus 和 Pluribus。其中 Pluribus 曾被 Science 评选为 2019 年十大科学突破之一。此外,他也领导开发了 Cicero 系统,这是首个在自然语言策略外交游戏 Diplomacy 上达到人类水平的 AI。凭借在 AI 领域的卓越贡献,他获得过马文·明斯基奖章(Marvin Minsky Medal)等许多奖项。
视频地址:https://www.youtube.com/watch?v=eaAonE58sLU
机器之心详细梳理了 Noam Brown 的演讲内容,以飨读者:
演讲开篇,Brown 谈到了自己刚开始研究生生涯的时候。那是在 2012 年,他开始研究打扑克的 AI。当时人们已经研究了扑克 AI 多年时间。很多人的感觉就是系统的问题已经解决,剩下的问题就是规模扩展(scaling)了。
下图左下展示了那几年模型参数量的变化情况。

那几年,各个研究扑克 AI 的实验室都会训练更大的新模型来互相竞赛。这就是当时的年度计算机扑克竞赛。
什么意外,每一年的新模型都会变得比之前的模型更强大。
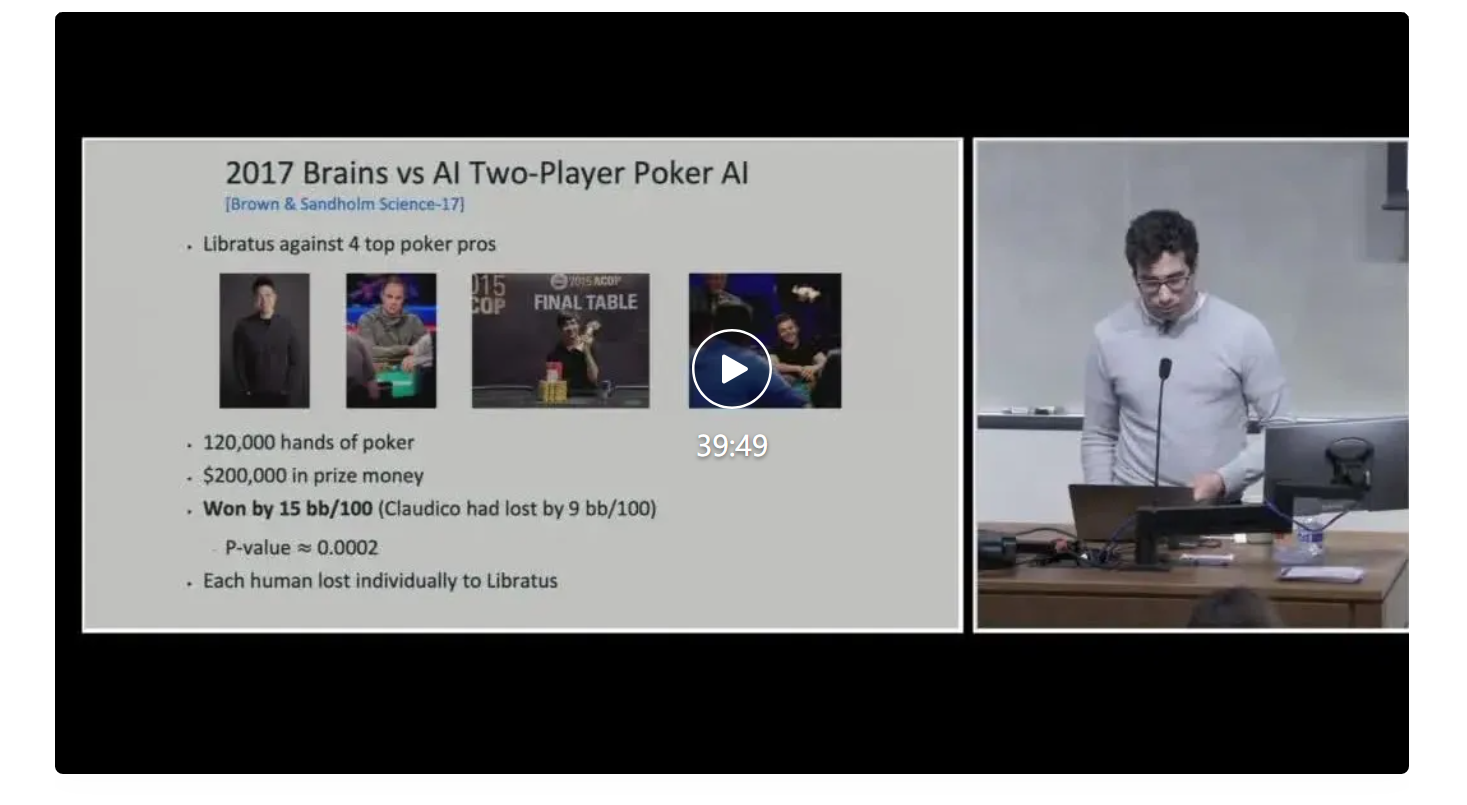
2014 年时,Brown 与其导师一起开发了当前最强大的扑克 AI,取得了竞赛第一名。那时候他们开始尝试在实际的比赛中与专家级人类对抗。于是在 2015 年,他们举办了人脑与 AI 扑克竞赛。

他们让自己的 AI 挑战了 4 位顶尖职业玩家,玩了 8 万手。最终,他们开发的名为 Claudico 的 AI 牌手惨败收场。
在这场比赛中,他注意到一些有趣的现象。他们的 AI 之前已经使用了大约 1 万亿手对局数据进行了训练。在这场比赛之前几个月时间里,这个 AI 一直在数千台 GPU 上不间断地玩扑克。
而到了真正与职业玩家比赛的时候,它会在很快的时间里做出决定,几乎是立即完成。但如果是人类面对同样的任务,则通常会深思熟虑。
Brown 在那时候便想到了,这或许就是 AI 所缺少的东西。这也成了其之后的重要研究方向之一。
2017 年时,他们发布了一篇论文给出了初步的研究结果(这是当年的 NeurIPS 最佳论文)。如下图所示,蓝线是不做任何搜索或规划的结果,橙色则是执行了搜索和规划的结果(越低越好)。X 轴是模型的参数量。所以这算是中等大小的扑克 AI 的扩展律(scaling law):模型越大,表现越好。而从图中可以看到,搜索所带来的受益比模型增大要大得多——同等模型大小下能带来近 7 倍的提升!
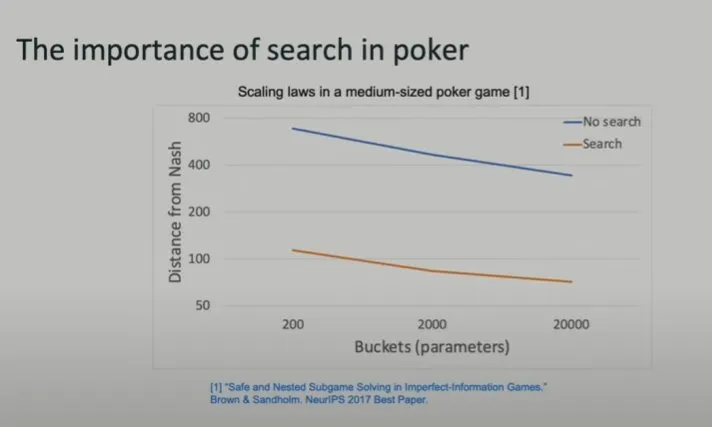
简单来说,这里的搜索就是让模型在行动之前「思考」大约半分钟。
Brown 表示,在研究扑克 AI 的三四年间,他将模型的大小提升了 100 倍,但所带来的提升远不及采用搜索策略。而如果要让蓝线代表的无搜索策略成功扩展到橙色线的水平,还需要将模型继续扩展 10 万倍。换句话说,搜索策略能带来 10 万倍的增益!
这让他不禁感叹:「与添加搜索相比,我在博士学位之前所做的一切都将成为脚注。」
之后,他转变了研究方向,将重点放在了扩展搜索能力方面。
2017 年,他们再次举办人脑与 AI 扑克竞赛。这一次,AI 大胜,并且每位职业玩家都输给了这个名叫 Libratus 的模型。

这一结果同时震惊了扑克和 AI 两个圈子,更何况 AI 的获胜优势还如此之大。对此事件的详细报道可参阅文章《德扑人机大战收官,Libratus 击败世界顶尖扑克选手》。
2019 年,他们开发了一个能玩六人德州扑克的 AI 并与人类职业玩家进行了对抗。
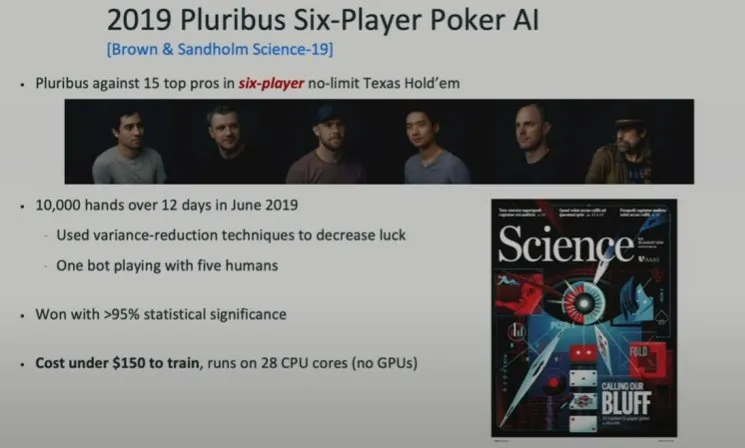
同样,AI 获胜了,并且其训练成本还很低,也没有使用 GPU,参阅《AI攻陷多人德扑再登Science,训练成本150美元,每小时赢1000刀》。
Brown 表示,如此低的成本意味着,如果当时就能发现这种方法,那么 AI 社区在 90 年代应该就能取得这一成就。
但为什么没有出现这样的研究呢?Brown 总结了几点原因和经验教训。(请注意,这里他强调并不会对「搜索」和「规划」这两个概念做明确区分,因为它们存在很大的共同点。)

实际上,这种使用规划和搜索的方法并非扑克 AI 所独有的。许多围棋和象棋 AI 都使用了这些技术。下面这张图来自 AlphaGo Zero 论文。
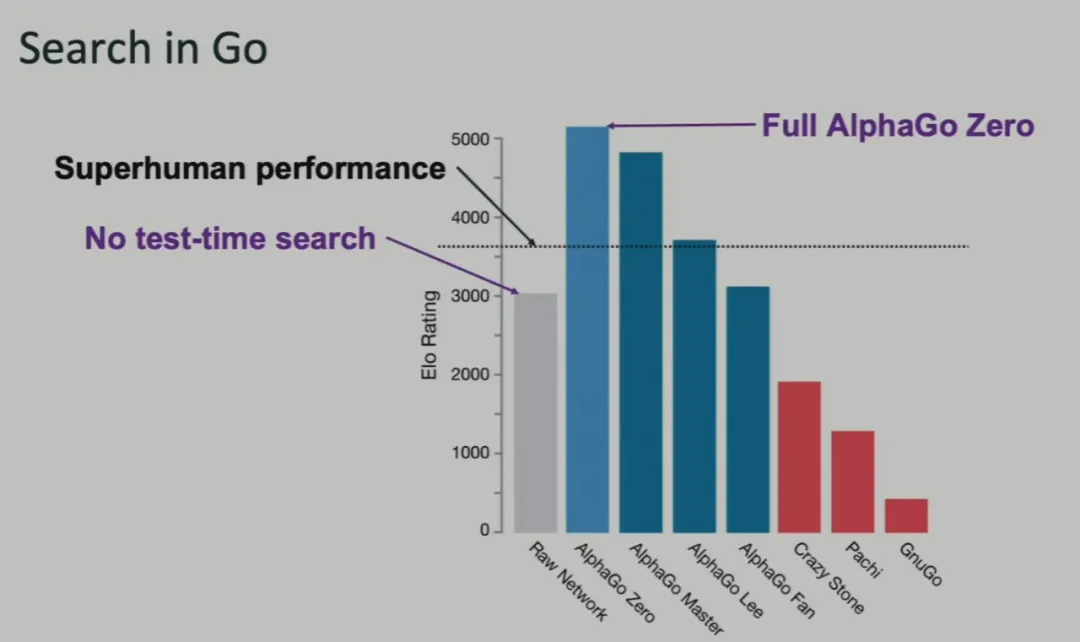
图中的 AlphaGo Lee 是指击败了李世石的版本,而 AlphaGo Zero 仅使用非常少的人类知识就取得了好得多的表现。
AlphaGo Zero 并不是一个原始的神经网络,而是神经网络+蒙特卡洛树搜索(MCTS)的组合系统。实际上,其原始神经网络的 Elo 分数仅有 3000 左右,不及人类。
实际上,从 2016 年到 2024 年,8 年过去了,现在依然没有人训练出超越人类职业棋手的原始神经网络。也许有人会说,就算如此,只要训练出更大的神经网络,最终就能超越人类吧。但就算理论上可以,实际上这个网络需要多大呢?
Brown 根据经验给出了一个大致估计:Elo 分数每增加 120 都需要 2 倍的模型大小和训练量或 2 倍的测试时搜索量。
基于此,如果仅使用原始神经网络,要将 Elo 分数从 3000 提升到 AlphaGo Zero 那样的 5200,则需要将模型扩展大约 10 万倍。当然,Brown 提到 AlphaGo Zero 的 5200 分其实存在争议,考虑争议的话模型的扩展倍数可能在 1000 倍到 1 万倍之间。
不管怎样,模型都需要大幅扩展才行。
另外,这还是假设训练过程中可以使用 MCTS。要是再从训练阶段剔除 MCTS,那么所需的扩展倍数更是天文数字。
那么,具体来说该如何进行规划呢?
合作策略桌游 Hanabi(花火)是一个很好的示例,这是一种不完全信息博弈。

2019 年 2 月,DeepMind 为 Hanabi 提出了一个新基准,并且他们提出了一种可取得 58.6% 胜率的强化学习算法。
六个月后,Noam Brown 当时就职的 FAIR 提出的一种算法就在两玩家场景中取得了 75% 的胜率,达到了超越人类的水平。并且他表示这其中仅使用了一种非常简单的技术。他说:「我们并没有在强化学习方面做什么全新的事情,就只是执行了搜索。」并且这种搜索很简单。
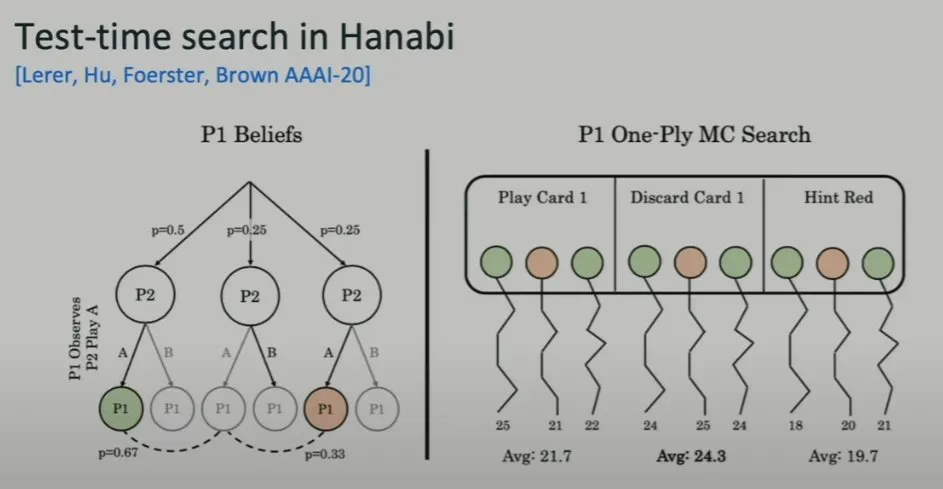
简单来说,就是搜索后续步骤执行不同动作时的情况,然后选择预期结果最好的一个。
实验结果证明这种简单方法确实有效。
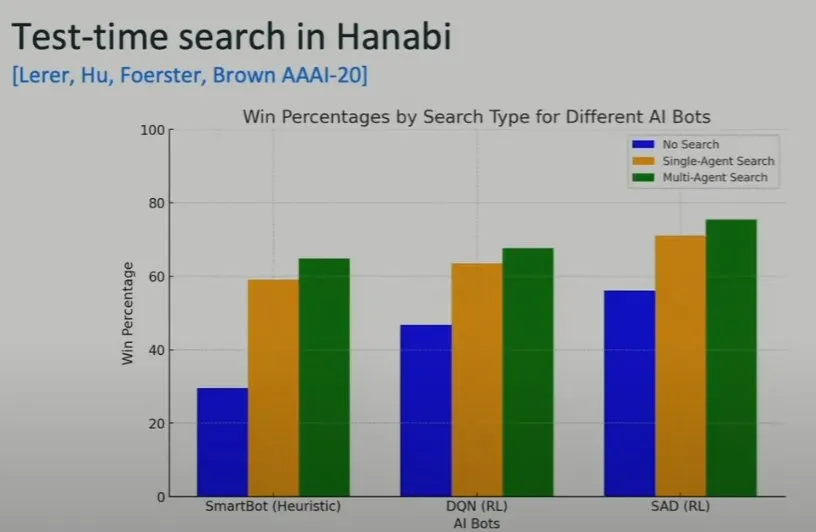
不管是哪种方法,在添加了搜索之后都取得了显著更好的表现。之前表现最差的基于启发式方法的 SmartBot 在添加了搜索之后也超过了未使用搜索的基于强化学习的最佳方法 SAD。
这一巨大提升甚至让 Brown 及其团队一度怀疑实验出 bug 了。要知道 Hanabi 游戏本质上不可能取得 100% 胜率,经过搜索加持的强化学习神经网络的胜率可能趋近于饱和。
同时,多智能体搜索的表现也优于单智能体搜索。这或许就是 Noam Brown 最近正在积极为 OpenAI 网罗多智能体研究者的原因。
Brown 提到他们并不是唯一一个发现这一趋势的团队。目前就职于 Anthropic 的 Andy Jones 也曾在棋盘游戏 Hex 上发现了这一点。
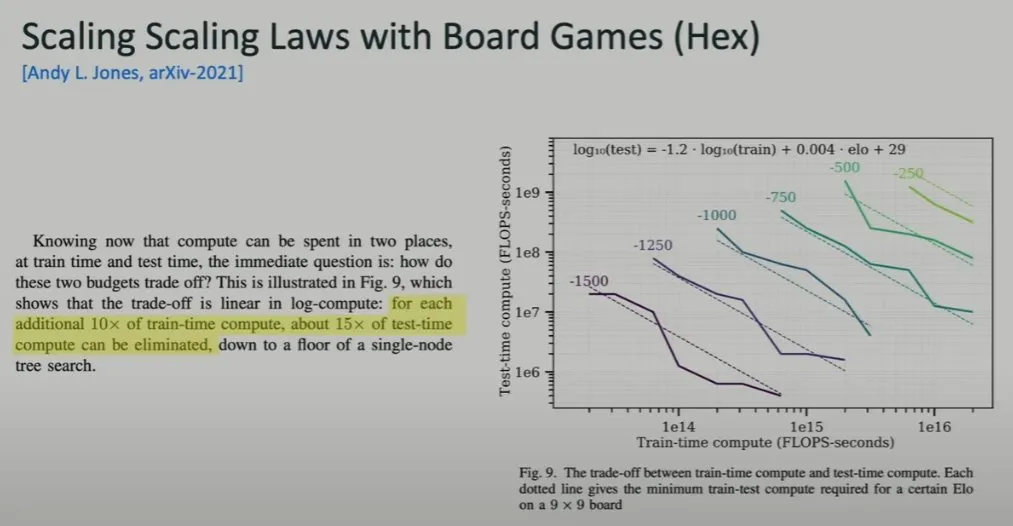
该研究发现,测试时间计算量增加 15 倍的效果相当于训练时间计算量增加 10 倍的效果。考虑到训练时的计算量远高于测试时的计算量。因此让测试时间计算量增加 15 倍要划算得多。
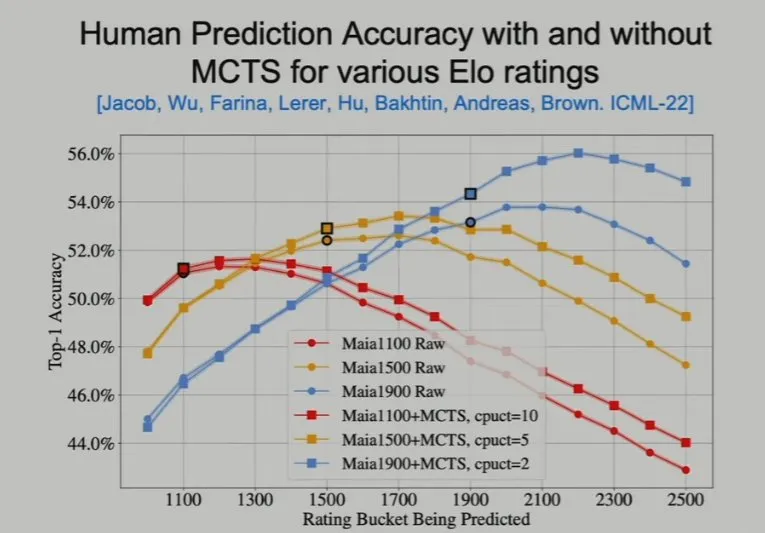
接下来,Brown 介绍了一个在国际象棋比赛上模仿人类专家数据的研究。这个名叫 MAIA 的国际象棋 AI 在 Elo 较高时比目标 Elo 分数低 100-300 分。也就是说,如果使用 2000 分的人类数据来训练它,它自己却只能得到 1700 分。但 MAIA 在有一种情况下能与人类专家持平,也就是快棋赛——这时候人类没有足够的思考时间。因此,这可能表明神经网络难以近似人类的规划能力。

之后,Brown 团队的一篇 ICML 2022 论文研究了在监督模型上添加规划的效果。可以看到不管是围棋还是国际象棋,搜索都大有助益。
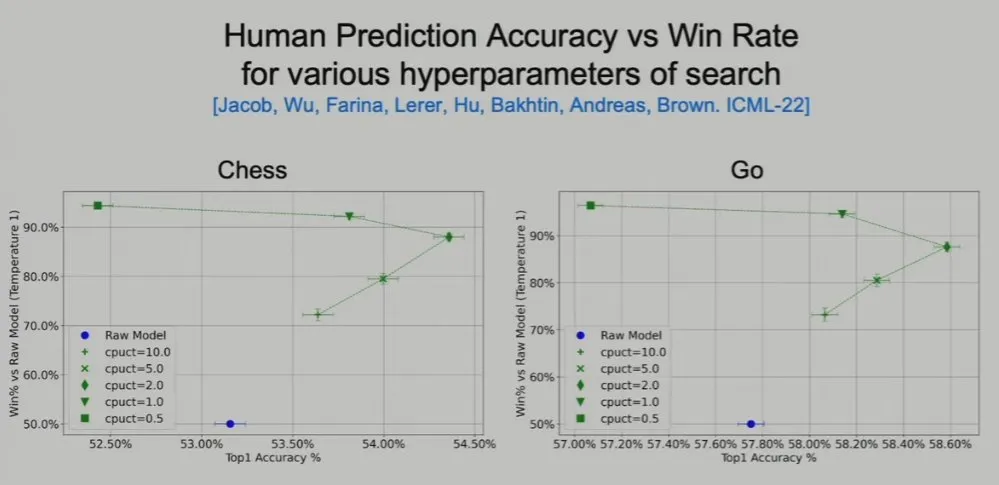
也许很多人都认为,要在某个数据集上最大限度地提高预测准确性,方法就是使用大量数据训练一个超大模型,但这些研究却给出了不一样的见解:在适当的超参数下添加搜索能力,就可以极大提升预测准确度。如下图所示。
接下来,Brown 介绍了他在 FAIR 时开发的一个用于外交游戏 Diplomacy 的 AI 智能体 Cicero,这是首个在外交策略博弈任务上达到人类水平的 AI。参阅机器之心报道《争取盟友、洞察人心,最新的Meta智能体是个谈判高手》。

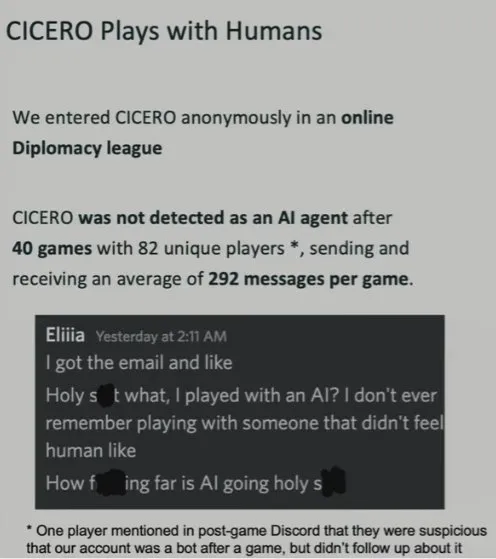
外交是一种非常复杂的自然语言策略博弈。Cicero 以匿名方式参与到了有许多人类玩家参与的游戏中。它玩了 40 局都没有被发现,并且平均每一局要收发 292 条消息。
一些参与游戏的人类玩家在获知 Cicero 是 AI 之后都发出了类似下图的惊叹之语!
Cicero 的表现如下,在参与游戏至少 5 局的玩家中,它取得了第 2 名的成绩。在所有玩家中也名列前 10%。整体优于人类玩家的平均水平。

下面来看看 Cicero 的工作方式。它的输入包括游戏棋盘和对话历史,其条件动作模型需要基于此预测所有玩家在当前回合会做什么,然后将这些动作输入到一个规划引擎中。
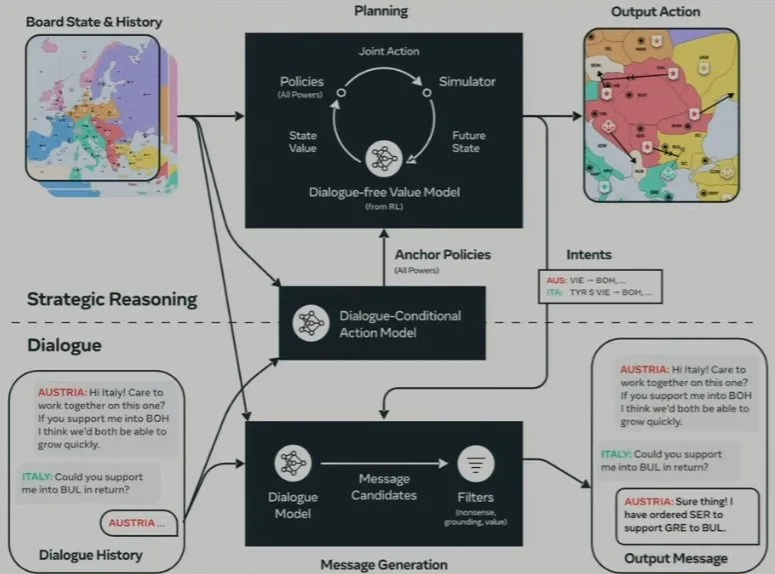
Brown 表示规划引擎是Cicero 的一大创新,现今的许多语言模型都还不具备这一点。
这个规划引擎会迭代式地预测所有玩家的动作以及所有玩家可能预测的Cicero 的动作。
最终,这会得到一个输出动作,还会得到一些意图——用于调节对话模型。也就是说,在执行了规划,搞清楚了我们应该在本回合中采取哪些行动以及我们认为其他玩家在本回合中会采取哪些行动之后,将这些规划输入对话模型,使对话模型以此为条件输出消息。
Brown 也提到这个过程非常耗时,通常每一次都需要至少 10 秒才能生成一个消息(他们使用了几十台 GPU)。但这种时间成本是值得的,能大幅提升性能。
规划为什么能带来如此巨大的性能提升?Brown 提到了「生成器-验证器差距」现象。简单来说,在许多领域,生成一个好解决方案的难度通常大于验证一个解决方案的难度。举个例子,玩数独游戏肯定比验证已经填入的数值更难。

但在另一些领域,情况却并非如此。比如对于信息检索任务,如果问不丹的首都是哪里,模型可以一口气生成几十个候选项,但我们还要费一番功夫去验证它。图像生成也是如此:生成图像很简单,但要验证生成的图像是否满足要求会更困难。
因此,当存在「生成器-验证器差距」且具有比较好的验证器时,我们可以将更多计算放在生成上,然后验证结果。
之后,Noam Brown 开始讨论语言模型。有趣的是他在此时强调:「我只能谈论已发表的研究。」这似乎在暗示他参与了或至少知道一些未发表的相关研究——或许就是 OpenAI ο1 及未来模型用到的技术。
他认为人们依然低估了这些技术所能带来的增益。
有一种名为 Consensus(共识)的算法是这样执行验证的:让 LLM 生成多个解,然后选择出现次数最多的那个。

方法很简单,但仅凭此方法,Minerva 模型在 MATH 数据集上的表现就从 33.6% 提升到了 50.3%。这里 Minerva 对每个问题采样 1000 次。
但这种方法也有缺点,那就是只适合答案只有数值等简单结果的问题。对于证明题之类的任务,就没办法了,因为这些任务很难每次都有一样的结果,难以达成共识。
另一种方法是 Best of N。这需要用到一个奖励模型来为生成的 N 个答案打分,然后返回最佳结果。这种方法的表现依赖于奖励模型的质量。如果奖励模型质量不行,就可能出现在错误上过拟合的问题。
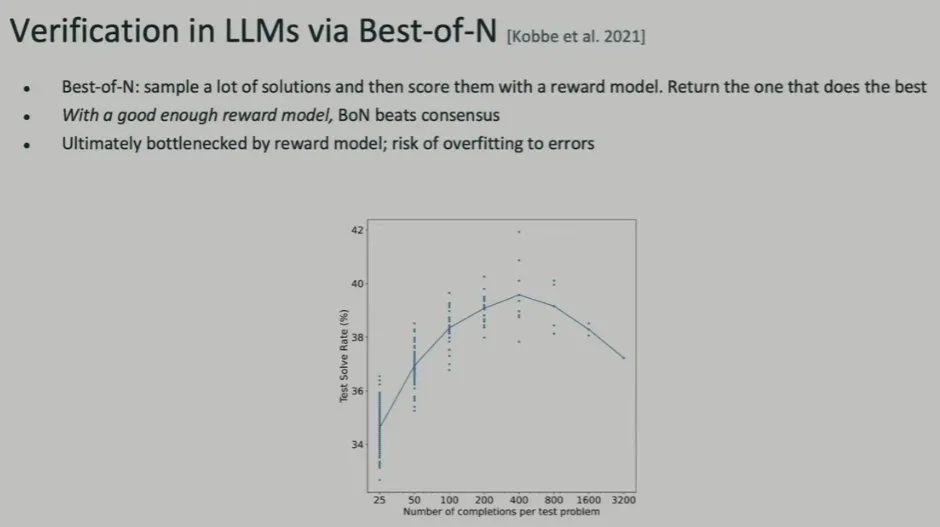
我们还可以做到更好。接下来Brown 介绍了那篇著名的论文《Let's Verify Step By Step》。机器之心也曾报道过这项研究,参阅《OpenAI要为GPT-4解决数学问题了:奖励模型指错,解题水平达到新高度》。

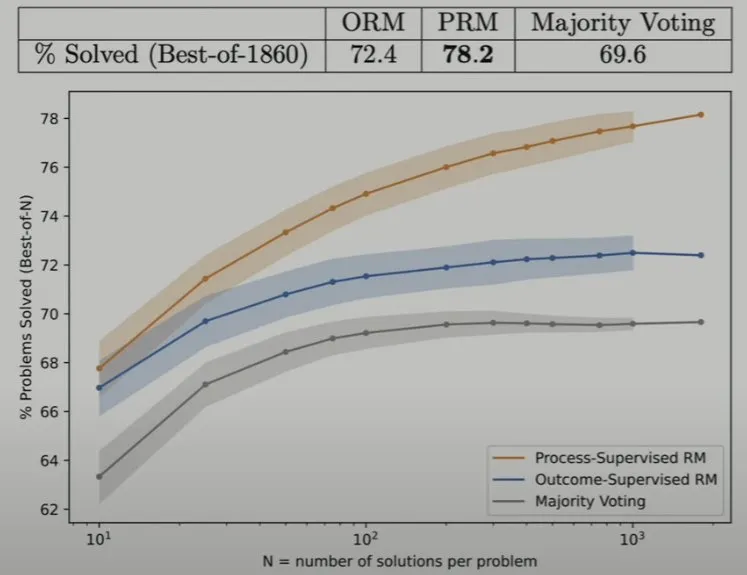
这篇论文发布于大概一年前,其中提出了「过程奖励模型」这一思路。简单来说,就是不再只是验证最终解答,而是验证每一步求解过程。只要过程中存在任何不正确的步骤,就判定最终结果是错误的,即便最终结果看起来是正确的。

这种方法的表现如何呢?如下图所示,橙色线是过程奖励模型的表现,可以看到,其显著优于Best of N 和结果导向的奖励模型,并且其优势会随着求解数量 N 的提升而提升。
Brown 举了一个非常有趣的例子。让LLM 解决这个数学问题:化简 tan100° + 4sin100°。
原始 GPT-4 模型正确解答这个数学问题的可能性仅有千分之一,而逐步验证法可将其提升一大截。

接着,Brown 话锋一转,分享了当今的 AI 图景。请注意,由于这次演讲发生于 2024 年 5 月 23 日,因此其中并没有最新的模型。但他谈到的发展趋势依然很有价值。
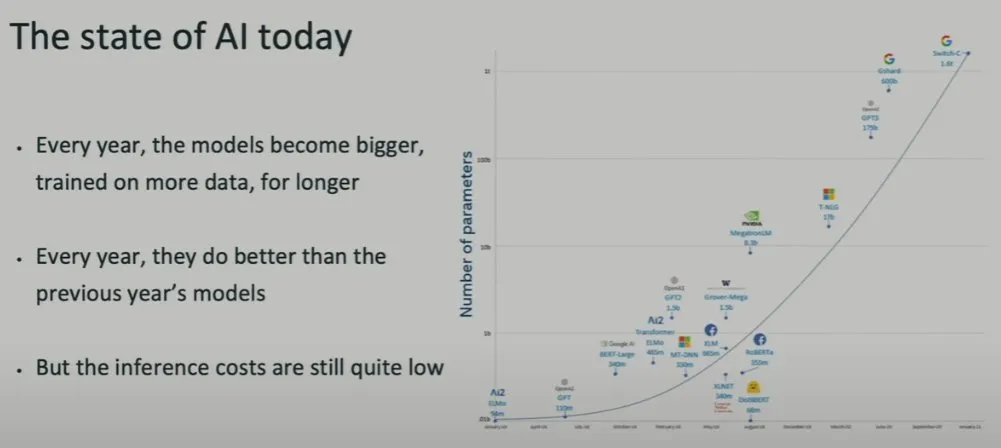
他说,在他研究生阶段研究扑克 AI 时,人们自认为找到了实现超人级扑克 AI 的方法:使用已有的算法,每一年都提升其计算和数据规模即可,然后就能击败前一年的模型。
他认为当今的 AI 领域也非常相似:有一种有效的技术,然后用更大的模型在更多的数据上训练更长时间,让其不断变得更好。与此同时,推理成本依然很低。Brown 表示未来不一定还是如此。
(当然,我们知道 o1 的出现已经开始扭转这一趋势,让人们更加注重研究推理时间的计算,即 inference-time compute 或 test-time compute)。
对于编程辅助和翻译这样的任务,我们可能并不愿意等待很长时间,但对于另一些重要问题,我们甘心等待几个小时乃至很多天,比如解决黎曼猜想或发现救命药物,又或者生成一部优质的小说。
他介绍了自己的「下一个目标」:通用性。

他也给学术界的研究者提了一点建议:

最后,Brown 提到了 Richard Sutton 那篇著名的文章《苦涩的教训》。

他引用了这两句:「70 年的人工智能研究史告诉我们,利用计算能力的一般方法最终是最有效的方法。……搜索和学习似乎正是两种以这种方式随意扩展的方法。」
文章来源于“机器之心”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
