# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型在刚发布的时候,以其任务、领域通用性和流畅的文本生成能力成功破圈,不过当时的技术还只能应用在一些比较简单的任务上。
而随着思维链等提示技术出现,尤其OpenAI最新发布的o1模型更是第一个采用强化学习策略的内化思维链技术的,把大模型解决复杂问题和推理能力提高了全新的高度。
虽然o1模型在各种通用语言任务上表现出了惊人的强大能力,但其在医学等专业领域的表现仍然未知。
来自加州大学圣克鲁兹分校、爱丁堡大学和美国国立卫生研究院的华人团队共同发布了一篇报告,对o1在不同医疗场景下进行了全面的探索,考察了模型在理解(understanding)、推理(reasoning)和多语言(multilinguality)方面的能力。

论文链接:https://arxiv.org/pdf/2409.15277
数据链接:https://ucsc-vlaa.github.io/o1_medicine/
该评估涵盖 6 个任务,使用来自 37 个医学数据集的数据,其中包括两个基于《新英格兰医学杂志》(NEJM) 和《柳叶刀》专业医学测验的高难度问答任务。
与MedQA 等标准医学问答基准相比,这些数据集与临床联系得更紧密,可以更有效地应用于真实世界的临床场景中。
对o1模型的分析表明, LLMs推理能力的增强更有利于模型理解各种医疗指令,也能够提升模型在复杂的临床场景进行推理的能力。
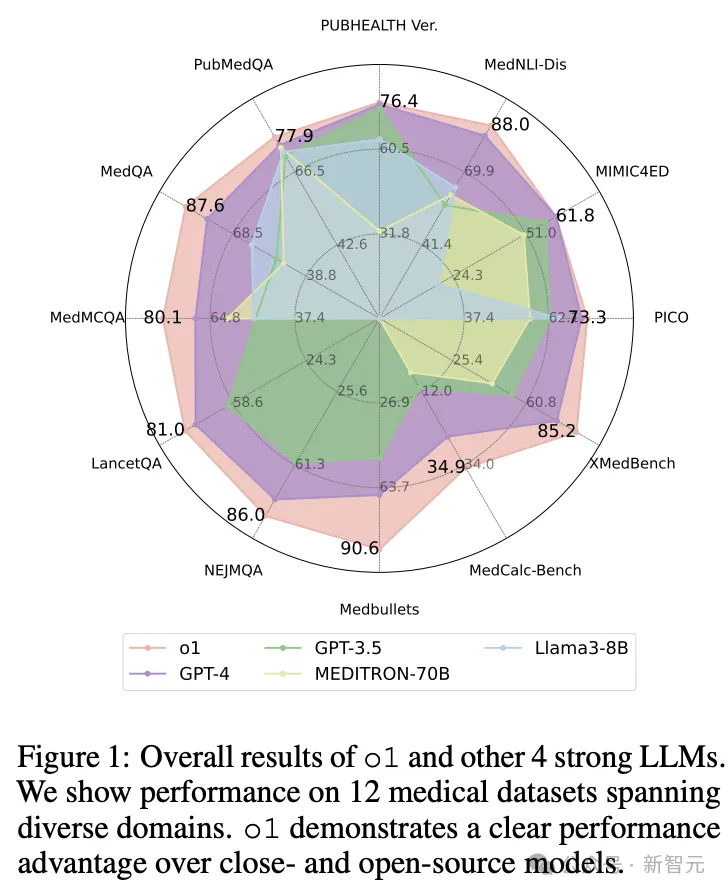
值得注意的是,o1模型在19个数据集和两个复杂问答场景中的准确率平均超过了之前GPT-4 6.2% 和 6.6%
与此同时,研究人员发现模型能力和现有评估协议中存在一些缺陷,包括幻觉、多语言能力不一致以及评估指标不一致。
在提升模型推理能力上,思维链(CoT)提示是一种常用的提示策略,利用模型内部的推理模式来增强解决复杂任务的能力。
o1模型更进一步,将CoT过程嵌入到模型训练中,整合了强化学习,展现了强大的推理性能;不过o1模型尚未经过专业领域数据的评估,其在特定任务上的性能仍然未可知。
现有的医学领域LLM基准测试通常只会评估模型的特定能力,比如知识和推理、安全性和多语言,彼此之间的测验比较孤立,无法对o1这样的高级模型进行全面评估。
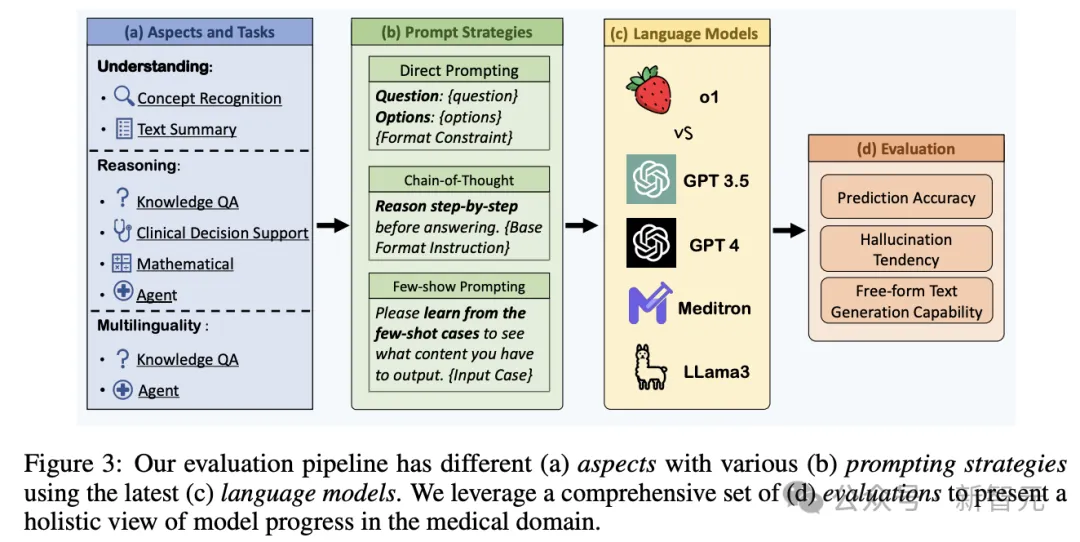
为了确保全面评估,研究人员收集了涵盖上述方面的各种医学任务和数据集,并在流程中探索了三种提示策略,包括:
1. 直接提示,指导大型语言模型直接解决问题
2. 思维链,要求模型在生成最终答案之前逐步思考
3. 少样本提示,为模型提供了几个示例,以便在运行中学习输入输出映射。
最后,使用适当的度量标准来衡量生成的回复与真实答案之间的差异。

研究人员利用35个现有的数据集,并为评估创建了2个额外的具有更高难度的数据集,然后将所有37个数据集分类为3个方面6个任务,以便更清晰地进行评估和分析,能够了解模型在特定领域的表现如何。
理解(understanding),指的是模型利用其内部医学知识来理解医学概念的能力。
例如,在概念识别(concept recognition)任务中,模型需要从文章或诊断报告中提取或详细阐述医学概念;在文本摘要中,模型需要理解复杂文本中的概念以生成简洁的摘要。
推理(reasoning),测试模型进行多步骤逻辑思考以得出结论的能力。
在问答任务中,模型需要遵循提示指令根据问题中提供的医学信息进行推理,从多个选项中选择正确的答案。
除了常见的问答数据集,研究人员还收集了来自《柳叶刀》、《新英格兰医学杂志》(NEJM)和Medbullets的真实世界临床问题,以更好地评估LLMs的临床效用。
在临床建议任务中,模型需要根据患者的信息提供治疗建议或诊断决策。在AI Hospital和AgentClinic数据集中,模型需要充当医疗智能体;在MedCalc-Bench数据集中,模型需要进行数学推理并计算答案。
多语言(Multilinguality),输入指令和输出答案的语言不同。
XMedBench数据集要求LLMs用六种语言回答医学问题,包括中文、阿拉伯语、印地语、西班牙语、中文和英语;在AI Hospital数据集,模型需要使用中文进行问答。
准确率(Accuracy),用于直接衡量模型生成的答案与真实答案完全匹配的百分比。
主要用于真实答案是一个单词或短语的情况,包括多项选择问题数据集、MedCalcBench数据集以及临床建议和概念识别数据集。
F1分数,精确度和召回率的调和平均值,用于模型需要选择多个正确答案的数据集。
BLEU和ROUGE,衡量生成回复与真实答案之间相似性的自然语言处理度量标准,对评估中所有自由形式生成任务使用BLEU-1和ROUGE-1
AlignScore,衡量生成文本事实一致性的度量标准,对所有无指定格式生成任务使用AlignScore来评估模型幻觉的程度。
Mauve,衡量生成文本和人类编写文本分布之间差异的度量标准,用于所有无指定格式生成任务,指标的数值范围为0到100,数值越高表示模型输出的质量越高。
提示策略
对于知识问答任务、智能体任务、医学计算任务和多语言相关任务,使用直接提示评估方法;
对于其他来自MedS-Bench的任务,遵循基准设置中的三样本提示策略。

根据OpenAI的声明,常见的提示技术,如思维链(CoT)和上下文中的示例,对于提升o1性能来说帮助并不大,因为模型已经内置了隐式的CoT。
为了进一步验证这一说法,研究人员在评估中增加了几种高级提示的效果,包括CoT、自我一致(Self Consistency)和Reflex
除了选择GPT-3.5、GPT-4、o1模型进行评估外,研究人员还选择了两个开源模型:一个是用医学中心数据训练的大型语言模型MEDITRON-70B,以及目前最新和最强大的开源大型语言模型Llama3-8B
主要结果
o1在临床理解方面的能力得到了增强
o1模型在发布时,OpenAI主要强调了其在知识和推理能力方面的显著提升,如数学问题求解和代码生成,从实验结果中也可以观察到,这种能力也能够迁移到特定的临床知识理解上。
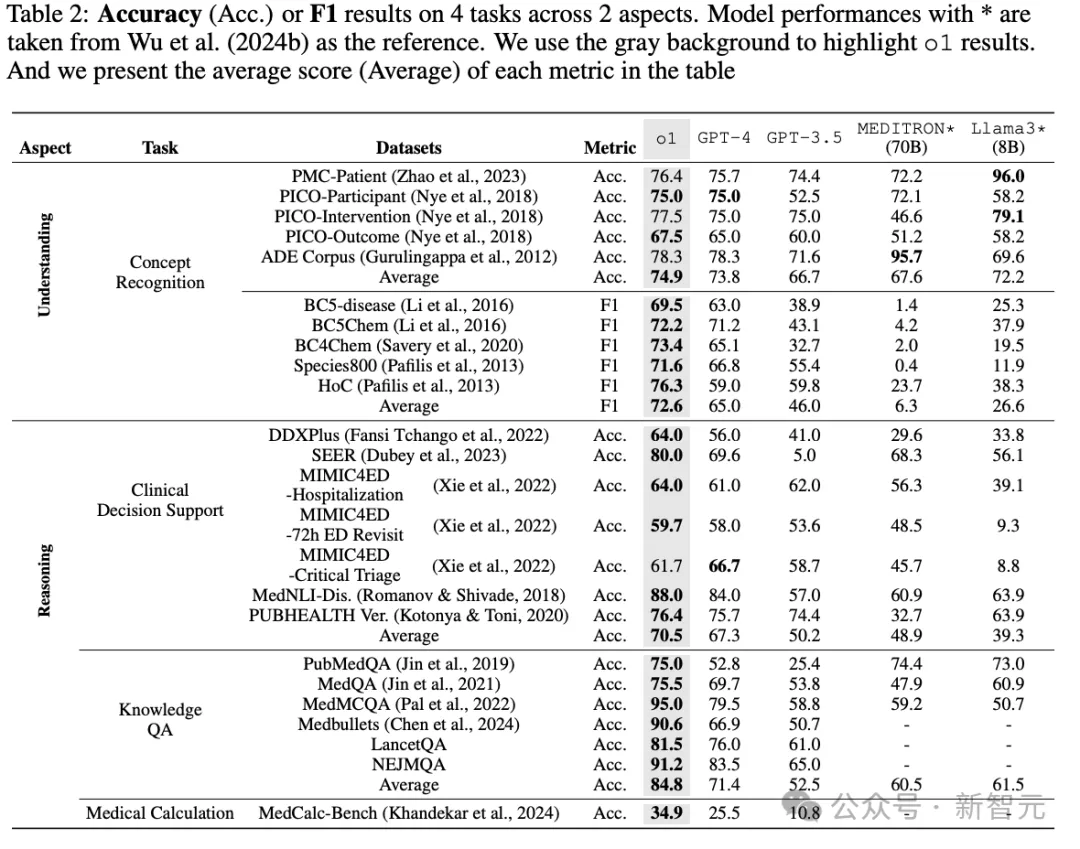
可以看到,在大多数临床任务的理解方面,o1的表现优于其他模型,例如,在5个使用F1作为度量的概念识别数据集上,o1的平均上分别比GPT-4和GPT-3.5高出7.6%和26.6%,在常用的BC4Chem数据集上平均提高了24.5%
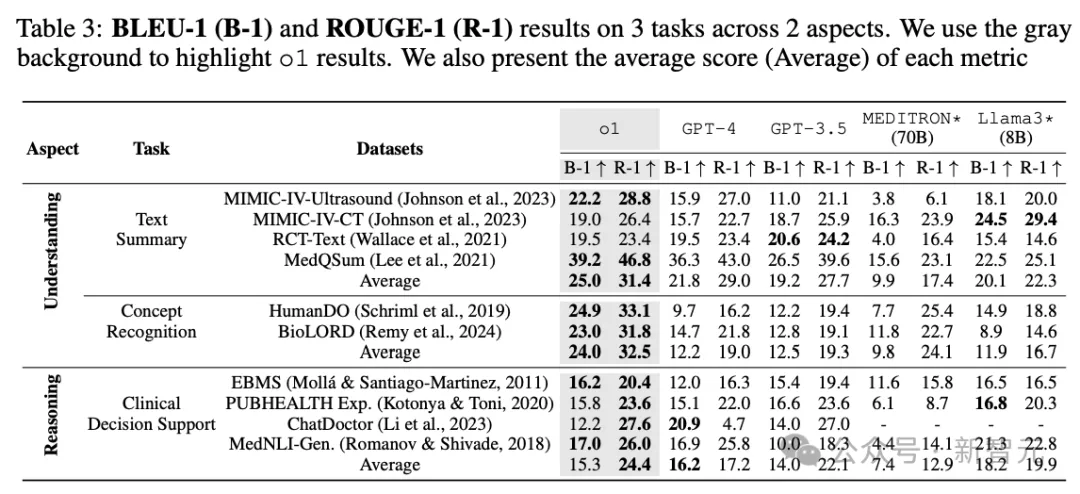
在摘要任务上,o1在ROUGE-1得分上比GPT-4和GPT-3.5分别提高了2.4%和3.7%,证明了其在现实世界临床理解方面的增强能力,结果也证实了大型语言模型在通用自然语言处理能力方面的进展可以有效地转化为医学领域的增强模型理解。
o1模型在临床诊断场景中强大的推理能力
在推理相关的任务上,o1模型也展现出了其在现实世界诊断情境中的优势。
在新构建的、具有挑战性的问答任务NEJMQA和LancetQA中,o1在各自的数据集上平均准确率比GPT-4(79.6%)和GPT-3.5(61.5%)分别提高了8.9%和27.1%
o1在数学推理能力上的另一个值得注意的改进是,将MedCalc-Bench的基线提升到了34.9%,比GPT-4高出显著的9.4%
在涉及多轮对话和环境模拟的更复杂的推理场景中,o1在AgentClinic基准测试中的表现超过了GPT-4和GPT-3.5,在MedQA和NEJM子集上分别获得了至少15.5%和10%的准确率提升,得分分别为45.5%和20.0%
除了更高的准确率外,o1的答案也更简洁、直接,而GPT-4则会于在错误的答案旁边生成幻觉性的解释。

研究人员认为o1在知识和推理方面的改进主要归因于训练过程中使用增强的数据和基础技术(如CoT数据和强化学习技术)。
基于上述乐观结果,研究人员在论文中激动地表示:有了o1模型,我们距离一个全自动AI医生已经越来越近了。
文章来源于“新智元”,作者“新智元”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
