# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Molmo,开源多模态模型正在发力!
虽然大家一直在期待谷歌、OpenAI 等等拥有无限资金储备和顶尖人才的大厂做出新的 Sota 模型。不过,一家默默耕耘的创业公司 Ai2 发布了一款多模态人工智能模型 Molmo。
在下面展示的视频中,我们可以看到 Molmo 就像钢铁侠的「贾维斯」一样万能。想卖自行车,咨询一下 Molmo 的建议,仅靠一张照片,Molmo 就能把自行车的颜色、品牌和二手售价搞清楚,并且帮你写出一句顺口的广告语。

它也可以从虚拟世界帮你解决现实世界的问题,说一句:「Molmo,帮我买杯星巴克的南瓜拿铁。」剩下的就不用动手了,打开外卖网页、点餐、付款,Molmo 一气呵成。你所要做的,就是坐在家中,静候咖啡送到你的手中。
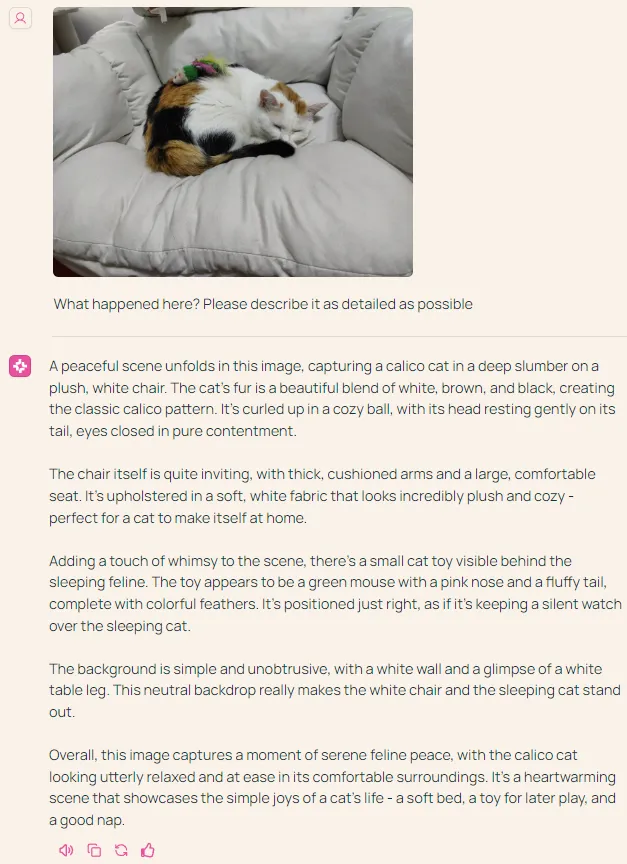
机器之心也尝试了一下他们在线发布的 Demo 模型。相较于宣传视频,其功能还很有限,所以我们让其执行了图像描述任务,可以看到 Molmo 在细节描述和准确度上的表现确实很不错,它甚至能注意到猫背上的小玩具:「玩具看起来像一只绿色的老鼠,鼻子是粉红色的,尾巴是蓬松的,羽毛色彩缤纷。」
但遗憾的是,Molmo 的汉语输出能力非常有限,即使我们明确要求其输出汉语,它也未能办到:

除了 Demo,从数据来看,Molmo 的表现也足够惊艳。在人类测评和一系列测试集中,Molmo 的得分击败了 Claude 3.5 Sonnet、GPT4V 等一众顶尖模型,甚至可以媲美 GPT4o。

不过,Molmo 的体量更小,却能「以小搏大」,性能超越了比它的参数量大十倍的其他模型。据 Ai2 首席执行官 Ali Farhadi 称,Molmo 的体积小到可以在本地运行,它无需 API、无需订阅、更无需成本高昂的液冷 GPU 集群。
更重要的是 Molmo 完全免费且开源,所有的权重、代码、数据和评估流程都即将公布。
部分模型权重、推理代码和一个基于 Molmo-7B-D 模型的公开演示已经可以使用。
Ai2 又是如何做到「四两拨千金」的呢?答案在 Ai2 公布的技术报告和论文中,这个秘诀就是:数据。

目前,最先进的多模态模型大多是闭源的,即使有一些开源的模型表现不错,但它们通常依赖于专有模型生成的合成数据。因此,如何从零开始构建高性能 VLM,对于开源社区来说,种种基础知识都很难获得。
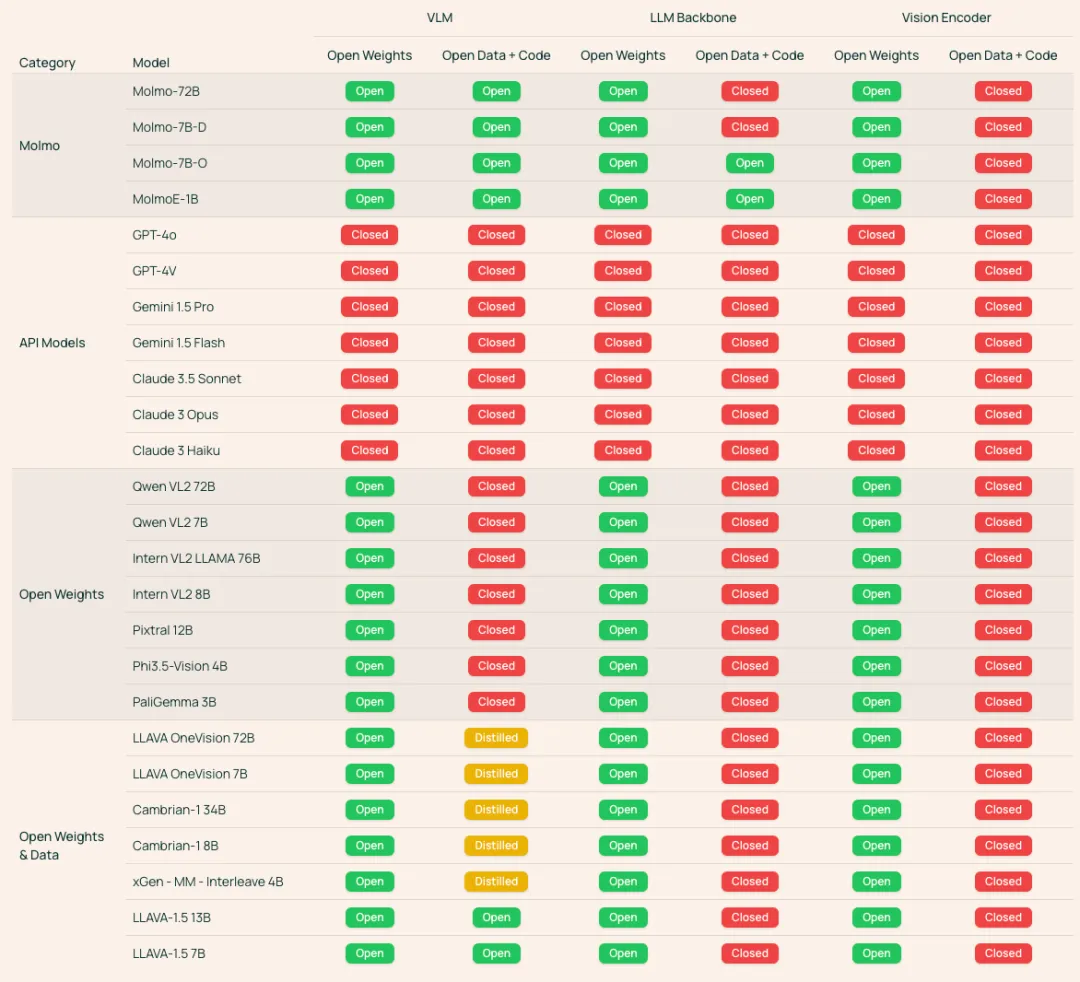
如上图所示,Ai2 的研究团队统计了目前 VLM 的开源程度,除了直接看模型的权重、数据和代码是否公开,他们还考虑了模型是否依赖于其他闭源模型。如果一个模型在训练中用了其他专有模型生成的数据,那它就被标记为「蒸馏」,这意味着它无法完全独立再现。
针对「闭源」的瓶颈,Ai2 使用语音描述收集了一个高细节度的图像描述数据集,这个数据集完全由人工标注,并可以公开访问。
该团队认为提升模型性能的诀窍是使用更少但质量更好的数据。面对数十亿张图像,不可能仅靠人力完成筛选、精细标注和去重的工作,因此,他们没有选择 scaling law,而是精心挑选并注释了 60 万张图像。
为了让 Molmo 能处理更多任务,Ai2 还引入了一个多样化的数据混合对模型进一步微调,其中就包括一种独特的二维「指向」数据。
因为现在市面上的多模态模型的工作原理是把图片、声音、文字等多种模态转换成自然语言的表示,而基于「指向」数据的 Molmo 更进一步,它可以用非语言的方式(如指向物体)进行解答。
比如,向 Molmo 提问:「你可以指出这块白板上的哪个模型的训练时间最短吗?」它不仅能用语音准确回答,还能直接用箭头「指向」它是从哪些数据中得到答案的。

要求 Molmo 数图中有多少只狗,它的计数方法是在每只狗的脸上画一个点。如果要求它数狗狗舌头的数量,它会在每只舌头上画一个点。
「指向」让 Molmo 能够在零样本的情况下执行更广泛的任务,同时,无需查看网站的代码,它可以懂得如何浏览页面、提交表单。
这种能力也让 Molmo 更自然地连接现实世界和数字世界,为下一代应用程序提供全新的互动方式。
通常而言,要训练一个大型 VLM,需要数以十亿计的图像 - 文本对数据。而这些数据往往取自网络,因此噪声很高。模型就需要在训练过程中分离信号与噪声。有噪声文本还会导致模型输出出现幻觉。
基于这样的考虑,该团队采用了不同的方法来获取数据。他们将数据质量放在了更重要的位置,结果发现,使用少于 1M 的图像 - 文本对就足以训练出强大的模型 —— 这比许多其它同类方法少了 3 个数量级。
Molmo 系列模型之所以能取得成功,最关键的要素莫过于 PixMo——Molmo 的训练数据。
Pixmo 包含两大类数据:(1) 用于多模式预训练的密集描述数据和 (2) 用于实现各种用户交互的监督式微调数据,包括问答、文档阅读和指向等行为。
该团队表示,在收集这些数据时,主要限制是避免使用已有的 VLM,因为「我们希望从头构建一个高性能 VLM」,而不是蒸馏某个已有的系统(但注意,他们也确实会使用仅语言的 LLM,但并不会把图像输入这些模型)。
在实践中,要让人类来标注大量数据是非常困难的。而且人类编写的图像描述往往仅会提及一些突出的视觉元素,而缺乏细节。如果强制要求最低字数,标注者要么需要花费太长时间,使收集过程成本高昂,要么就会从专有 VLM 复制粘贴响应,这又会违背避免蒸馏模型的目标。
因此,开放研究社区一直在努力,在不依赖专有 VLM 的合成数据的前提下,创建这样的数据集。
该团队提出了一种简单但有效的数据收集方法,可以避免这些问题:让标注者用语音描述图像 60 到 90 秒,而不是要求他们打字。他们让标注者详细描述他们看到的一切,包括空间定位和关系的描述。
从结果上看,该团队发现,通过这种模态切换「技巧」,标注者可以在更短的时间内提供更详细的描述,并且对于每个描述都有对应的录音,可证明未使用 VLM。
总的来说,他们收集了 71.2 万幅图像的详细音频描述,涵盖 50 个高层级主题。
他们的混合微调数据包含了标准的学术数据集以及一些新收集的数据集,这些新数据集也将会公开发布。学术数据集主要用于使模型在基准测试数据上表现良好,而新收集的数据集则能赋予模型大量重要功能,包括在与用户聊天时能够回答关于图像的一般性问题(超出学术基准数据范围)、提升 OCR 相关任务(如读取文档和图表)、精准识别模拟时钟的时间,以及在图像中指向一个或多个视觉元素。
指向功能可为图像中的像素提供自然的解释,从而带来 Molmo 全新且更强大的能力。该团队认为,指向将成为 VLM 和智能体之间重要的交流方式。例如,一个机器人可以查询具有指向功能的 VLM 以获得路径点或要拾取物体的位置,而一个网页智能体可以查询 VLM 以定位需要点击的用户界面元素。这组系列数据集也分为以下六个:
为了进行全面的评估,该团队既使用了学术基准评测,也执行了人类评估以根据用户偏好对模型进行排名。
从结果上看,学术基准评测结果与人类评估结果高度一致。唯一的例外是 Qwen VL2,其在学术基准上表现很好,但在人类评估中表现相对较差。
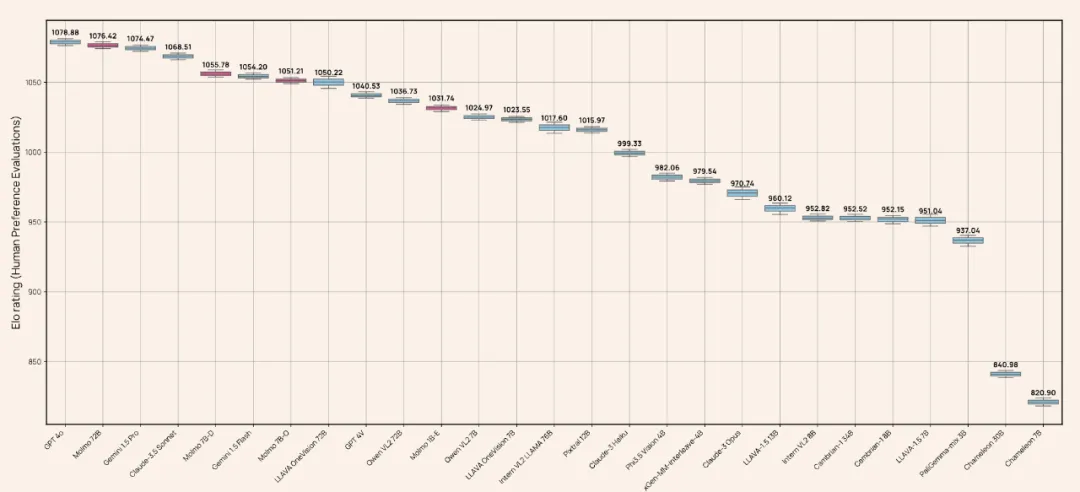
该团队总结得到了一些关键结果,并表示「Small is the new big, less is the new more」,详情如下:
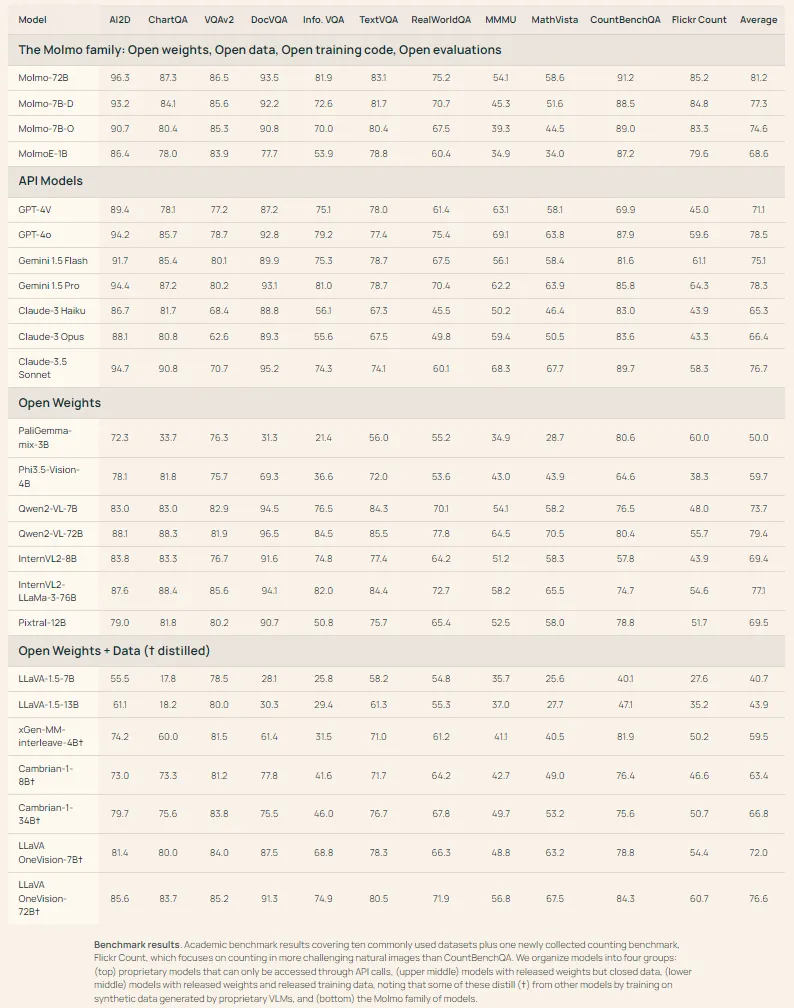
在接受 TechCrunch 的采访时, Ai2 首席执行官 Ali Farhadi 表示,人工智能界有条定律 ——「越大越好」,训练数据越多,模型中的参数就越多,需要的算力也就越多。但发展到一定阶段时,「scaling law」就会遇到瓶颈,根本无法继续扩大模型规模了:没有足够的数据、或者计算成本和时间变得太高,以至于弄巧成拙。你只能利用现有的资源,或者更好的办法是,用更少的资源做更多的事情。

Molmo 的模型架构采用了简单的标准设计,也就是将一个语言模型和一个图像编码器组合起来。其包含 4 个组件:
该团队基于这一模板构建了一个模型系列。通过选择不同的视觉编码器和 LLM 可以为其赋予不同的参数。在这些选择基础上,所有模型的后续训练数据和方案都一样。
对于视觉编码器,他们发布的所有模型均使用 OpenAI 的 ViT-L/14 336px CLIP 模型,该模型的效果好且质量稳定。
对于 LLM,他们采用不同的规模,基于不同的开放程度训练了模型:OLMo-7B-1024 的权重和数据完全开放的(使用了 2024 年 10 月的预发布权重,其将于晚些时候公布)、高效的 OLMoE-1B-7B-0924 也是完全开放权重和数据,Qwen2 7B、Qwen2 72B、Mistral 7B、Gemma2 9B 则是仅开放权重。新发布的是该系列的 4 个样本。
他们的训练过程也很简单,首先从已经独立完成预训练的视觉编码器和 LLM 开始,接下来分为两个阶段:
这两个阶段都会对所有参数进行更新,并且过程中不使用 RLHF。
该团队首次发布就分量十足,包含一个演示模型、推理代码、一份简要的技术报告和以下模型权重:
未来两个月,该团队还将陆续发布以下研究成果:
更多研究细节,可访问原博客。
文章来源于“机器之心”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
