# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
论文《Chat Edit 3D: Interactive 3D Scene Editing via Text Prompts》的作者包括来自北京航空航天大学博士生方双康、北京航空航天大学副研究员王玉峰,谷歌AI技术主管Tsai Yi-Hsuan,旷视高级研究员杨弋,北京航空航天大学研究员丁文锐,旷视首席科学家周舒畅,加州大学默塞德分校和谷歌DeepMind研究科学家Yang Ming-Hsuan教授。

1. 一句话概括
本文设计了一种由大语言模型驱动的、可集成任意数量视觉模型的交互式三维场景编辑框架,其文本形式不再受限、编辑能力不再单一。
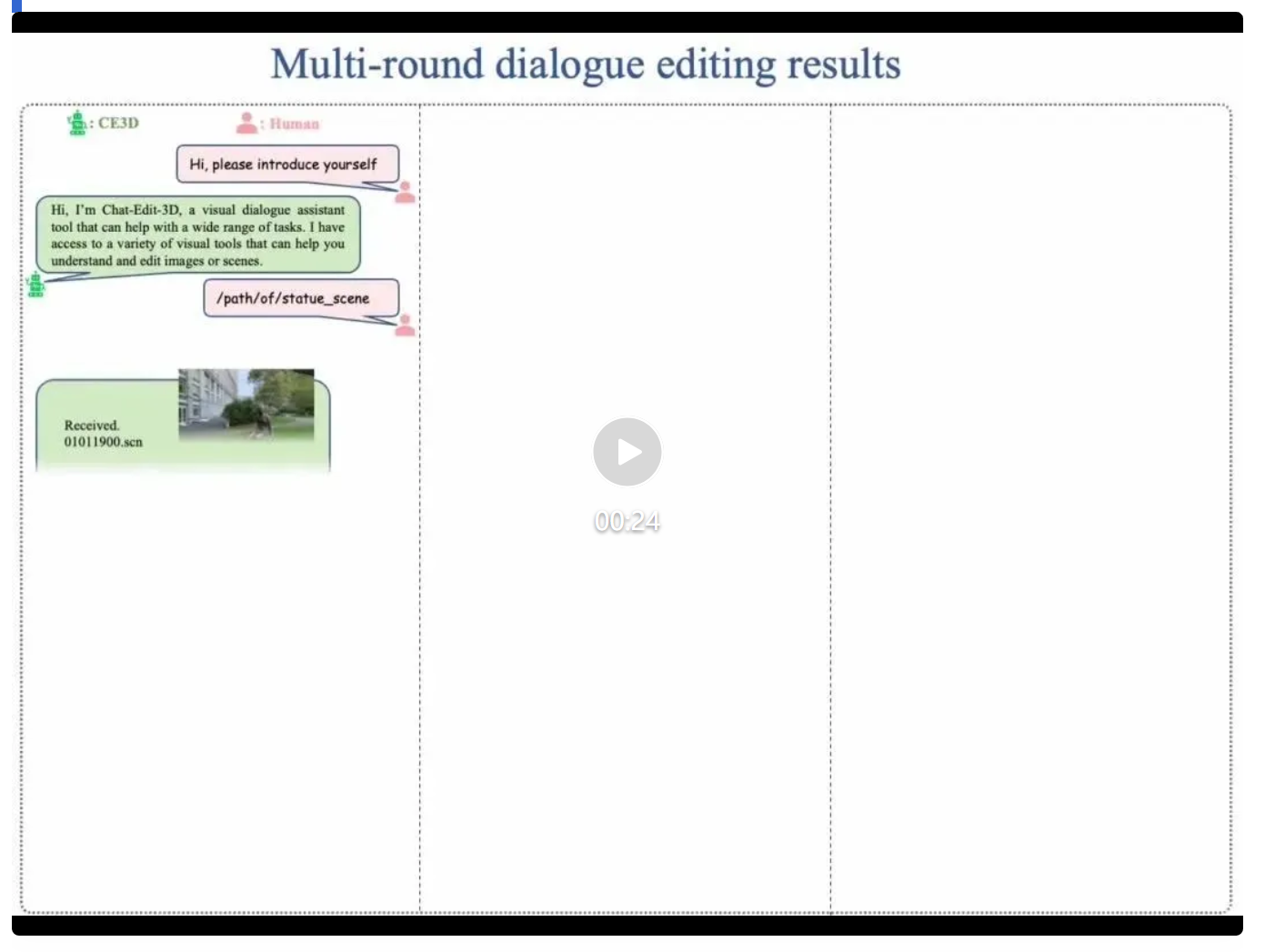
(对话式 3D 场景编辑过程示例视频)
2. 引言
现有的文本驱动 3D 场景编辑方法通常局限于固定的文本输入形式和受限的编辑能力。用户需要使用固定形式的文本指令或单一的 diffusion 多模态模型来实现所需的效果。比如 InstructNeRF2NeRF 只能使用 “指令式文本” 且编辑能力受限于 InstructPix2Pix 模型。然而,实际应用中,用户的语言是及其丰富的,用户的编辑需要也是多种多样的,现有方法的设计范式均无法满足用户的诉求。
为了突破这些限制,本文提出了一种全新的 3D 场景编辑新范式 —CE3D。该方法将 3D 场景的编辑变成在 2D 空间上图集的编辑,实现对现有方法的 “降维打击”。降维后可利用大规模语言模型实现灵活且高效的任意模型的集成,大大丰富了文本对话能力和场景编辑能力。
3. 本文方法 CE3D
CE3D,即 Chat-Edit-3D。其核心思想是通过大规模语言模型解析用户的任意文本输入,并自主调用相应的视觉模型来完成 3D 场景的编辑。为了实现任意视觉模型的集成,本文先设计 Hash-Atlas 的映射网络,将对 3D 场景的编辑转换为对 2D 空间内的图集编辑操作,从而实现了 2D 多视角编辑与 3D 场景重建过程的完全解耦,因此,本文将无需固定的 3D 表示形式和 2D 编辑方法。用户想用什么视觉模型就可以用什么视觉模型。
3.1 Hash-Atlas 网络
Hash-Atlas 网络将 3D 场景的不同视图映射到 2D 图集中,从而将 3D 场景编辑过程转移到 2D 空间中执行。为了实现适配已有 2D 多模态编辑模型,映射后的图集需要满足以下条件:(1)防止图集中出现过多的扭曲和倾斜,以维持视觉模型的理解能力;(2)前景和背景图集应大致对齐,以确保精确编辑;(3)需要更快、更精确的映射,以便于高效编辑。为了满足这些条件,本研究设计了一个基于哈希结构的网络,如图所示:
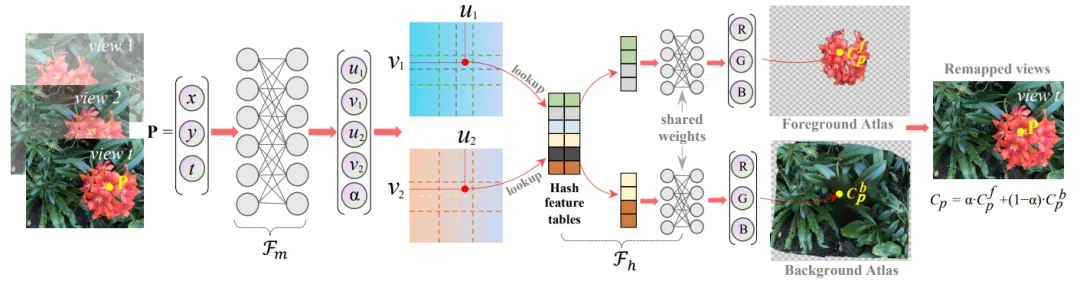
图 1 Hash-Atlas 网络示意图
假设场景中有 T 个视图,点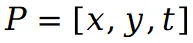 在第 t 个视图中被函数
在第 t 个视图中被函数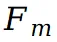 映射到两个不同的 UV 坐标:
映射到两个不同的 UV 坐标:

其中 表示在两个 UV 空间中的坐标。参数
表示在两个 UV 空间中的坐标。参数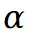 在 0 到 1 之间,表示前景图集中像素值权重。然后使用
在 0 到 1 之间,表示前景图集中像素值权重。然后使用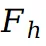 预测在 UV 坐标中对应的前景和背景图集的 RGB 值:
预测在 UV 坐标中对应的前景和背景图集的 RGB 值:
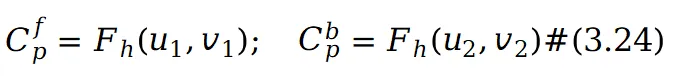
其中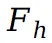 采用哈希结构来捕捉图像中的纹理细节,并实现更快的模型训练和推理。在图集中获得像素
采用哈希结构来捕捉图像中的纹理细节,并实现更快的模型训练和推理。在图集中获得像素 后,可以按如下方式重建场景视图中点P的原始像素:
后,可以按如下方式重建场景视图中点P的原始像素:
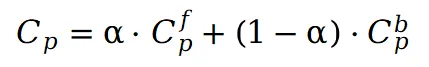
当图集被编辑后,可以通过上式还原带有编辑效果的 3D 场景的每个视图,而无需重新训练哈希图集网络。为了确保得到的图集更加自然以及避免物体过度倾斜和扭曲,在模型训练的早期阶段,仅使用来自第 0 个视图的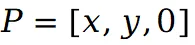 ,此时预训练位置损失定义如下:
,此时预训练位置损失定义如下:

此损失函数鼓励坐标映射后场景在第 0 个视图中的位置变化最小。此外,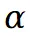 的预训练涉及初步通过 VQA 模型确定场景的前景及其对应的掩码,通过分割模型获得假设前景掩码为
的预训练涉及初步通过 VQA 模型确定场景的前景及其对应的掩码,通过分割模型获得假设前景掩码为 ,则
,则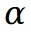 的预训练损失定义如下:
的预训练损失定义如下:

其中 CE 表示交叉熵损失,等式右侧第二项则鼓励 和前景图集的稀疏性,这有助于前景和背景图集内容的明确分离。完成预训练后,可以通过监督图集重建视图来训练整个模型。但直接进行训练会导致背景图集中明显的区域遗漏,影响了后续的编辑任务。为了解决这个问题,本文引入了修补损失。具体而言,利用 ProPainter 模型对遮罩背景进行初步修补,生成一组新的修补视图。假设原始视图中的点 P 在修补视图中对应于
和前景图集的稀疏性,这有助于前景和背景图集内容的明确分离。完成预训练后,可以通过监督图集重建视图来训练整个模型。但直接进行训练会导致背景图集中明显的区域遗漏,影响了后续的编辑任务。为了解决这个问题,本文引入了修补损失。具体而言,利用 ProPainter 模型对遮罩背景进行初步修补,生成一组新的修补视图。假设原始视图中的点 P 在修补视图中对应于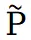 ,则重建损失可以表示如下:
,则重建损失可以表示如下:
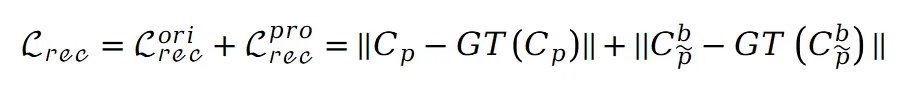
其中 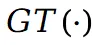 表示从场景的原始视图或修补视图中获得的真实值。此外在场景上引入刚性和流动约束:其中
表示从场景的原始视图或修补视图中获得的真实值。此外在场景上引入刚性和流动约束:其中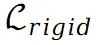 的目的是保持不同点之间的相对空间位置不发生剧烈变化。与此同时
的目的是保持不同点之间的相对空间位置不发生剧烈变化。与此同时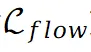 鼓励将不同视图的对应点映射到图集上的同一位置。因此,总损失可以表示如下:
鼓励将不同视图的对应点映射到图集上的同一位置。因此,总损失可以表示如下:
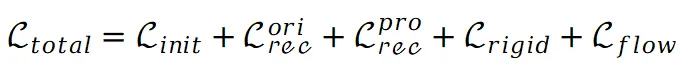
其中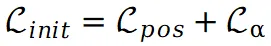 仅在初始训练阶段使用。
仅在初始训练阶段使用。
完成 3D 场景映射到 2D 图集后,可以在图集上完成场景的编辑,然而直接编辑两个图集再将其映射回场景视图,通常不会得到令人满意的编辑结果,这主要是因为单个图集包含的场景信息不完整,尤其是在稀疏的前景图集中。这一限制使得编辑模型无法获得完整的场景语义,从而无法始终实现可靠的编辑。因此,本研究设计了一种合并 - 拆分策略来编辑图集。在此过程中,首先利用 ChatGPT 的解析功能和 VQA 模型来识别编辑区域,如果这些区域涉及前景内容,则将前景图集覆盖在背景图集上,作为实际的编辑图集。随后使用原始的前景掩码和新的对象掩码将编辑后的图集分离开来。
3.2 基于大语言模型的对话框架: CE3D
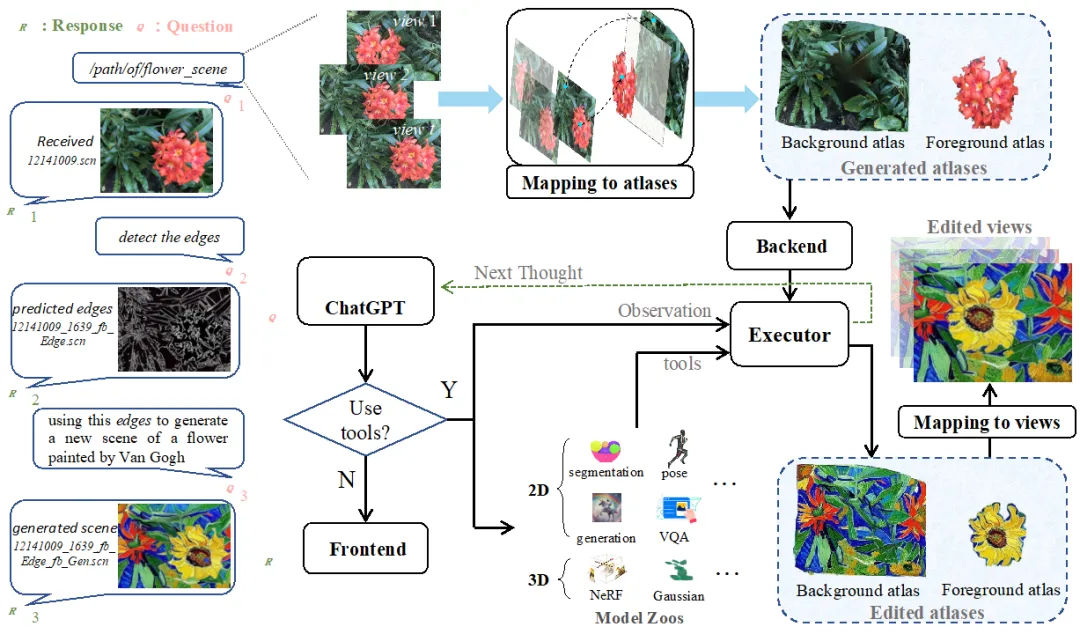
图 2 交互式编辑方法 CE3D 示意图
如图所示,CE3D 的基本流程如下:(1)根据用户的文本查询,ChatGPT 解释文本并确定是否需要在此次对话中使用视觉工具;(2)当需要视觉工具时,ChatGPT 将从模型库中调用所需的工具并为它们提供相应的参数;(3)后端进一步查询要调用的图集和其他文件。如果图集不存在,后端首先使用 Hash-Atlas 网络获取它们;(4)执行器执行视觉工具以编辑图集,并将新的状态反馈给 ChatGPT 以便后续操作。编辑后的图集通过 Hash-Atlas 网络映射回 3D 场景视图,以进行后续的场景重建;(5)由于一次对话可能需要多次模型调用,ChatGPT 重复上述过程,直到确定不再需要视觉工具。然后前端将编辑结果和 ChatGPT 的输出回复给用户。
作为一种语言模型,ChatGPT 无法直接访问文本以外的信息。然而,由于编辑过程中涉及的文件众多,不可能将所有文件作为文本输入 ChatGPT。因此,本研究中用格式为 “xxx.scn” 的字符串来表示所涉及的文件。这个字符串是唯一且无意义的,以防止 ChatGPT 编造场景名称。尽管这个场景名称并不是一个真正可读的文件,但前端和后端的进一步处理使得 CE3D 能够有效处理真实文件。前端将编辑结果和 ChatGPT 的输出整理成用户回复,而后端分发编辑过程中涉及的真实场景文件,并管理新场景的名称和文件。
在面对用户输入时,ChatGPT 模拟一个思考过程:“我需要使用视觉工具吗?”→“我需要哪些工具?”→“工具的具体输入应该是什么?”。因此,需要预先向 ChatGPT 注入每个视觉专家的相关信息,以完成这个推理过程。本方法为每个视觉工具标注了四个类别:工具的名称、在什么情况下使用、所需参数和具体输入示例。具体可阅读开源代码。
4. 代码使用展示
在多轮对话编辑案例中,CE3D 能够处理各种类型的编辑请求,例如精准对象移除或替换、基于文本或图像的风格迁移、深度图预测、基于文本和深度图条件的场景再生、人体 Pose 预测、场景超分、场景分割等。此外,它还可以完成与场景相关的视觉问答任务和基本的文本对话。总之,因为能任意扩展视觉模型,因此编辑能力无上限!
功能太多,且能轻松扩展,代码已经开源。

与其他方法的对比 (视频对比可参看 Project Website):

图 3. 与其它方法对比,CE3D 能实现更丰富的编辑能力

图 4. 与 InstructNeRF2NeRF 相比,CE3D 的多轮对话能力和编辑能力超强!
5. 总结和展望
CE3D 打破现有 3D 场景编辑方法的范式,实现了多模态编辑模型和 3D 场景表示模型间的完全解耦,因此可以兼容任意的 2D 和 3D 的视觉模型。进一步通过大语言模型的逻辑推理和语言理解能力,来实现对用户文本查询的解析和模型的自主调用管理,以实现对话式的 3D 场景编辑框架 CE3D。不过,虽然 CE3D 在 3D 场景编辑方面取得了显著进展,但该技术在处理 360 度场景时会遇到一些挑战,还有进一步研究的空间。
文章来源于“机器之心”




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
