# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI能理解搞笑视频笑点在哪里了。
AI回答:这个视频之所以搞笑,在于一个小宝宝正坐在床上努力读书,但他显然还不会真正读书。他只是不停地指着书页上的各处,而摄影者则在背后笑他。小宝宝的这种尝试很有趣,因为他在尝试阅读一本对他而言过大的书,也看不懂里面的文字。
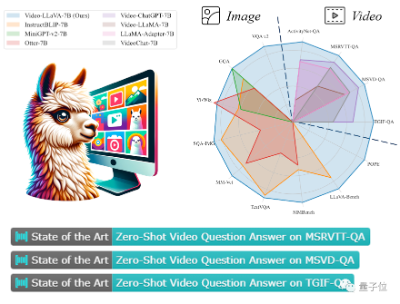
北大等团队开源视觉语言大模型Video-LLaVA,将图像和视频表示对齐到统一的视觉特征空间,在13个图片和视频基准上达到先进的性能。
值得注意的是,Video-LLaVA在训练过程中没有使用成对的视频和图片数据,但在训练后,LLM令人惊讶地展现出同时理解图片和视频的能力。
如下图所示,Video-LLaVA成功地识别出自由女神像的图片是近景且细腻的,而视频描述了自由女神像的多个角度,表明它们来自同一个地方。
这项工作具体贡献如下:
对于模型能力,研究团队做了充分实验。
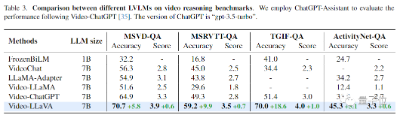
如表3所示,Video-LLaVA在4个视频问答数据集上全面超过了Video-ChatGPT,并且涨幅相当可观。
图片理解能力实验。
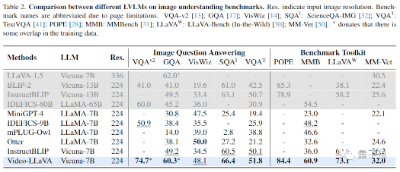
该研究还与InstructBLIP,Otter,mPLUG-owl 等图片语言大模型在图片语言理解任务上进行了比较,结果如表2所示:
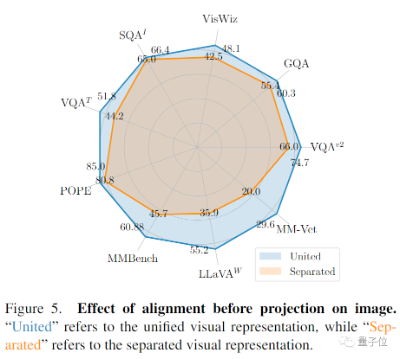
为了评估预先对齐视觉输入的效果,研究团队进行了大量的对比实验。
他们使用了相同规模的MAE编码器替换了图片编码器,其中MAE编码器生成分离的视觉表示,而LanguageBind编码器生成统一的视觉表示(因为预先对齐了视觉表征)。
然后,他们在13个基准测试中比较了MAE编码器和LanguageBind编码器的性能,包括9个图片理解基准和4个视频理解基准。
通过替换图片编码器为MAE编码器,LLM在初始学习视觉表示时将视频特征和图片特征分开处理,不再将它们统一起来。
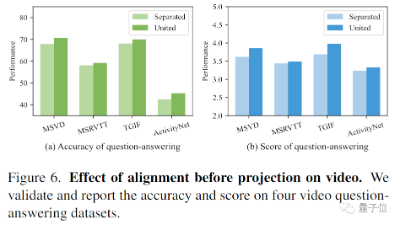
有关图6的实验结果显示,与分离的视觉表示相比,联合的视觉表示在4个视频问答数据集上显著提升了性能。
这一发现表明,预先对齐的视觉表征有助于LLM进一步学习和理解视频内容。它提供了更好的能力,使得模型能够更有效地处理视频问答任务并展现出更好的性能表现。
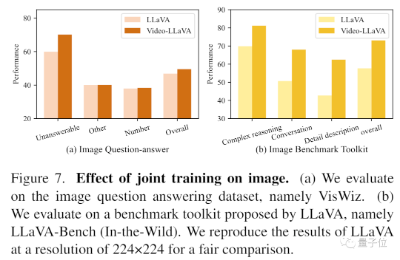
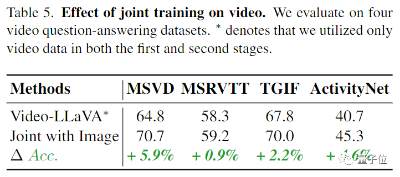
同时论文还验证了无论是对于图片还是视频,在联合训练中他们能相互受益。
通过联合训练视频数据,对于图片理解任务,可以缓解幻觉问题。类似的趋势也在LLaVA-Bench基准测试上观察到。
在视频理解方面,联合训练的也得到了明显的提升。
参考资料:
[1]https://arxiv.org/abs/2311.10122
[2]https://github.com/PKU-YuanGroup/Video-LLaVA
文章来自微信公众号 “ 量子位 ”,作者 梦晨


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda