# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
ChatGPT 推出以后,AI 硬件就成为了热门赛道。
AI Pin、Rabbit R1、以及 Meta 的雷朋眼镜,还有豆包即将推出的智能耳机,有成功的,也有不少失败的。
在大模型热潮持续一年之后,或许可以看一下,AI 硬件未来的机会到底在哪里。本文来自科技基金 Capital O 的管理合伙人 Aaron Qian,分享了对AI硬件、XR和具身智能等行业的观察和思考。
硬件是中国的主场
在今年前9个月见过的108个团队中,具身智能项目有14个,AI硬件项目8个,XR相关5个,共占25%。相较于软件,偏硬件的赛道国内团队优势更加明显,特别是AI硬件方向大多围绕深圳世界领先的供应链生态打造团队。我们也正与两家企业深入接洽。

原则#1 这一波AI硬件将由软件驱动
我在上一篇分享中提到新交互方式出现前现阶段AI应用依然是移动互联网逻辑。回顾移动互联网时代,4G/5G的成熟在底层技术架构上为短视频等高信息密度应用的新形态打下了基础,而iPhone开创的触控交互体验真正为应用的繁荣打开了大门。
苹果也因为在交互模式上的创新获得了移动互联网时代最大的红利,时至今日依然可以向软件生态征收“苹果税”。强如Meta,几乎盘踞了海外C端流量和广告收入,也因为缺乏硬件设备而如鲠在喉。Zuckerberg近年来在Reality Labs上的激进投入,狂烧500亿美金就是为了占据下一个时代的硬件入口/计算中心。

在当前格局下, Google ,Meta,苹果和字节跳动等移动互联网巨头从硬件到软件牢牢把持了用户生态,并基于计算中心/物理空间、流量/网络效应、时间/用户习惯这几个核心要素形成了深厚的壁垒。如果这个局面不被打破,AI大模型技术将停留在更先进的生产工具("enabler”)定位,从结果上丰富了移动互联网生态的内容供给和用户体验,“为他人做嫁衣”。科技巨头依然是最大受益者,过去5年强者恒强的局面将会延续。

过去五年科技巨头市场份额不断提升
因此针对AI大模型重新设计的硬件和交互将是GenAI时代挑战者必须攻克的堡垒。这也是为什么Sam Altman很早就联系传奇设计师Jony Ive开始在硬件方向进行探索。
事实上这样的尝试对挑战者来说从未停止。在硬件层面,智能手表、TWS耳机成为体量可观的新硬件品类,但没有摆脱手机配件的定位。在软件层面,前两年大热的crypto在某种意义上创造了新的获客货币,在高企的流量红海中提供了一种bootstrap的可能性,但因为缺乏后续承接能力而已失败告终。直到AI大模型技术在最近两年取得突破,特别是GPT4o在多模态领域的进展让人们看到了一丝希望:软件突破带来的智慧和拟人感如同一道「魔法」给硬件赋予生命。
软件带来的变量主要体现在以下两个方面
AI硬件的三层架构
在原生多模态AI大模型出现后,结合硬件会出现新的信息交互和处理模式,大体上可以分为三个层次(为表述方便下称“AI硬件三层架构”):
2.模型处理和计算 -> 计算中心
3.交互方式 -> UIUX设计
在这三层架构中,计算中心(如手机)将为AI大模型提供端侧和云端运行能力,而AI大模型技术的能力进步驱动整个闭环用户体验的提升,具体表现为让硬件在原有功能的基础上拓展能力边界,在第三层输出更好的效果。反过来中间层需要硬件作为传感器获得更多context来更好地输出模型运算结果。
现阶段AI硬件,特别是新品类新团队的机会大多在第一层,即新式传感器,但长期中如果不能将价值向第二和第三层延伸,则会陷入消费电子卷成本的深渊无限竞争(参考激光雷达之于自动驾驶)。
LUI是否能成为下一代交互方式
「The UI of AGI」是AI硬件从业者需要思考的圣杯问题。
“套壳”其实就是一种最直接的尝试,Arc浏览器,Perplexity,Monica.im都在各个方向积极探索。但LUI(Language User Interface)或者基于语音的交互方式(Voice-first UI)是否能取代触控时代主流的GUI(Graphical User Interface)是在行业内被讨论最多的问题。
我认为GPT4o为代表的低延迟、多情感、高智能原生多模态模型虽然为LUI的落地提供了技术支持,并在某些特定场景有较好的体验,但现在看起来LUI并不能独立成为最主流的交互方式。我认为思考这个问题的关键因素是I/O密度。I即input,指在人机交互中用户向系统输入信息。O即output,指系统向用户反馈信息。
在I端,LUI能很好地解决当下信息输入门槛过高的问题,阵列麦克风技术的发展配合AI大模型的多语言识别和总结能力,让用户在I端更加轻松自如(flowvoice.ai等公司已经有产品落地)。
但在O端,LUI的信息密度有很大的局限,特别是与GUI相比。Vela在「Voice-first,闭关做一款语音产品的思考」中做了详细的解析。
声音在交互上的局限性主要表现在:
1. 输出线性
2. 记不住

在音频自身限制和AI大模型现阶段长程推理能力缺失的情况下,LUI目前只适合做目标明确的单点任务,且输出结果信息密度不宜过高。从数据上看,天猫精灵使用最多的场景是询问天气和设定闹钟。钢铁侠的Javis形态目前在技术边界之外。
因此,LUI配合GUI结合使用我认为是能将I/O密度最大化的交互体验。
原则#2 熟悉的陌生感:从「+AI」开始
做新的硬件产品一般有两种思路:a) 定义全新的品类;b) 在已有品类上做创新和提升。22年裴宇刚做新锐手机品牌Nothing的时候,我和他有过一次交流。当时Humane还没有像今天这样出圈,但也完成了顶级机构领投的融资。我问Carl:“你已经在手机领域证明了自己,现在创业为什么不像Imran一样尝试全新的品类?”多年之后在Sana AI Summit上他给出了更精华的回答:「Survival is the name of the game」。
Kickstarter大中华区首席战略代表彭奕亨在谈到AI硬件时提到了一种说法“熟悉的陌生感”,这个形容非常准确。「Hardware is hard」,与软件开发不同,硬件的试错成本更高,团队需要保持敬畏心。特别是对产品线单薄的新团队来说,每一款产品都至关重要。
Humane AI Pin和Rabbit R1在定义全新品类的路线上进行了勇敢的尝试,但截止目前结果不佳。我认为核心原因是对现有的技术边界没有准确的认识。短期内基于已有成熟硬件品类,在保证优秀的基础体验的前提下,思考如何融入AI大模型技术锦上添花(为表述方便下称“+AI”)将是短期内较为稳妥的路线。
原则#3「Less is more」
在确定产品方向时,务必要遵守「less is more」的原则,能用一个产品覆盖的功能,绝不做两个设备,特别是在个人便携设备品类。理想的方式是做品类和功能之间的整合,如在智能眼镜中整合耳机和音频功能,而不是在用户有限的裤兜/手包里再装进一个产品。
另一方面,特别是对可穿戴设备,轻量化是最重要的设计标准,在现有电池密度和芯片功耗有限的边界下,每添加一项功能都会造成额外的配重和续航消耗。取舍是产品定义中最重要的课题。
「手机+传感器」和「AI陪伴具身化」
在已经需求验证的场景中,我认为以上两个生态是现阶段最大的两个机会。
手机短期内依然是生态位核心。
算力中心一直是消费电子生态位的核心,从个人电脑(PC)到笔电,再带手机和平板,信息处理和运算方式很大程度上决定了硬件的物理形态。从长远来看,基于Transformer架构的大模型从算法上进行了根本的创新,随着技术的演进可能会诞生新的计算机形态,但目前看来这个过程不会在5年内完成。手机作为算力中心,短期内依然可以覆盖绝大部分用户的大多数生产和娱乐需求。
非技术角度,从台式个人电脑向手机演进的过程中,轻便可携带是明显的用户需求趋势。经过近30年的迭代,如今手机的物理形态在重量、体积、续航、交互模式上已经高度成熟,在某种意义上手机是第一款成为人类「电子器官」的产品。

iPhone取代了诺基亚的历史地位,但并没有从本质上改变手机的物理形态。类似的,在短期内,搭载端测模型能力后手机将继续占据双手的使用场景,依然是主要的核心生态位。
实践中也有很明确的例证:
手机在AI硬件三层架构可以在一定程度上覆盖所有三个维度,并占据计算中心的核心价值位。现阶段对其他硬件设备的主要机会在于成为手机的传感器,收集手机目前尚不能覆盖的细分场景信息 - 主要是息屏、用户双手被占用无法拿起手机、无法快速开启手机内置传感器(为描述方便,下文统称“手机空白场景”)- 并尝试探索新的交互体验。
在这样的系统设定下,可穿戴设备最适合扮演传感器的角色。而人本身的信号传感器 – 眼、耳、鼻都集中位于头部 – 围绕头部的可穿戴设备必将成为必争之地。今年5月,我在社交媒体即刻上转发了下面这张图,非常生动地展示了这个事实。
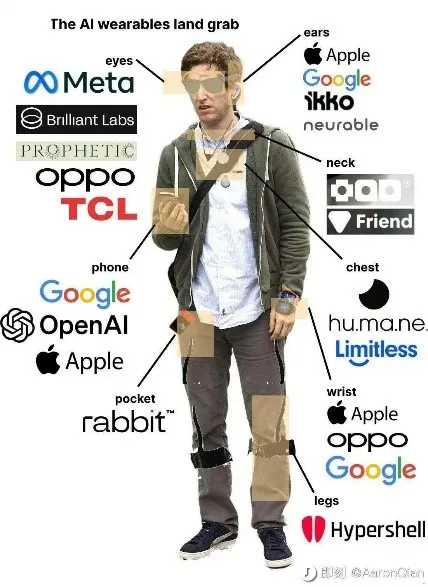
但需要明确的是,由于轻量化和目前硬件技术的瓶颈,可穿戴设备都难以独立支撑好的用户体验(包括眼镜在内),需要和手机配合使用。
轻量化是穿戴设备成功的金标准。
因为要补充手机空白场景,长时间使用(“always on/available”)是对穿戴设备作为传感器功能的核心要求。同等条件下,用手机能更快地捕获信息并进行输入,穿戴设备就会变成累赘。因此,轻量化无感佩戴是这类产品能否普及必须实现的目标。在围绕头的穿戴品类中,主要有手表、耳机、眼镜、挂件、戒指、手环等。这些产品大多都是成熟品类,在好的基础体验上创新也符合「+AI」的策略。
久谦咨询对这些品类的市场规模做了如下估算:
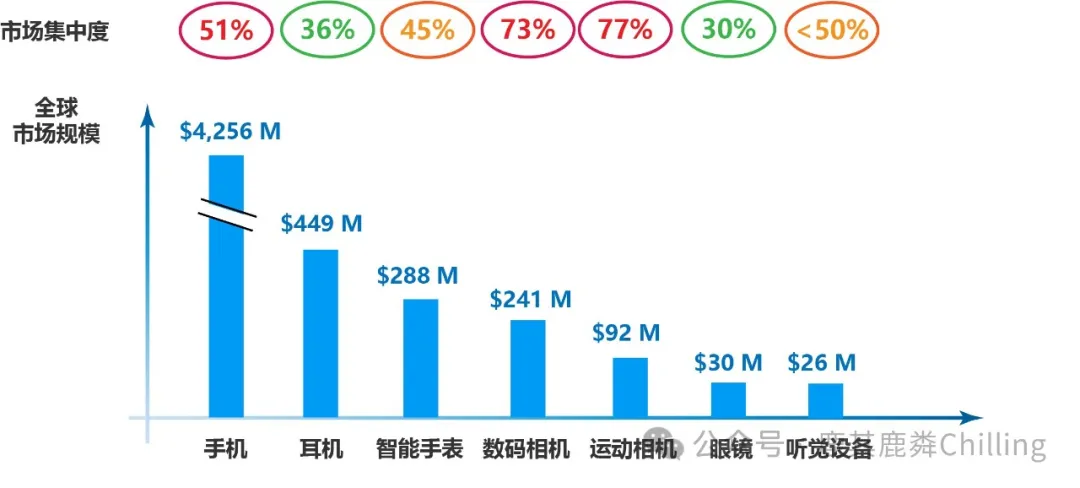
在个人便携式设备中,数码相机和运动相机较难满足长时间无感佩戴(一定程度上可以被眼镜覆盖),且市场集中度高。对AI硬件团队来说,市场足够大的品类依次是耳机、智能手表、眼镜和配饰类设备。
整个智能穿戴设备生态都脱离不了一个主题:Survival is the name of the game
手机厂商因为占住了核心生态位,穿戴设备的新机会都在其射程之内,我们讨论的所有穿戴设备品类都逃脱不了激烈的竞争。对新玩家来说有两种现实的选择:1) 在市场足够大的赛道,争取成为小米华为苹果身后的第三/四名;2)在大厂看不上,小公司搞不定的赛道做差异化竞争。
第一种路线考验的是团队的执行力,需要面对的竞争包括:
第一梯队:华为,小米,苹果;优势无需赘述,且已经有手机、耳机、眼镜等成熟产品线,用户基数大
第二梯队:Oppo/Vivo,大疆,安克等;有成熟的供应链资源和分销渠道,成熟业务可以产生稳定现金流
第三梯队:科大讯飞、韶音、雷鸟、Rokid等;在垂类中有领先市场份额
互联网公司:字节跳动、阿里、腾讯等;拥有大量承接UIUX的场景
竞争确实激烈,但也并不是全无机会。AI硬件时代的一个重要变量是对团队的复合型要求:即软硬件结合的能力。正如文初提到的,这一轮AI硬件本质上是软件驱动的,与硬件龙头竞争,新团队需要具备更强的软件能力,努力将产品向AI硬件三层架构的后两层做价值延伸。而互联网公司,强如字节跳动,虽然目前在积极探索布局豆包大模型与硬件的结合,但从决心和能力上都无法与Meta相提并论。更重要的是,硬件的逻辑与字节跳动信奉的数据驱动的方法论有本质区别,对人才的审美和组织管理形式也大相径庭。收购PICO后的整合就是例证。PICO的铩羽动摇了字节在这个方向投入的信心,造成了阴影(从目前的信息来看,字节可能从下一章节陪伴硬件的角度先切入)。
当然,也可以选择第二条路线。这就要求团队对消费者需求有深度的洞察和提前的预判。一个可以参考的思路是将软件功能硬件化。核心是找到一个软件端有需求的场景,并通过极简的设计,将多步操作压缩到一步。Plaud就是看到Live Transcribe这个app巨大的用户基础,将录音这个本来可以在app端完成的场景硬件化。将原本需要掏出手机,解锁,找到app,打开app,开启录音的一系列操作融合到简单的一键到位。虽然Plaud的软件端目前还非常拉胯,但硬件的极致设计,已经让它成为了我的必备用品。
在可穿戴设备的众多品类中,我最看好眼镜这个品类,因此独立一个小节进行分析。
智能眼镜:连接人类与机器的第三只眼?
在展开讨论之前,需要明确的是,这里讨论的智能眼镜主要是Rayban Meta的形态。这不是一款AI眼镜(至少现在不是),而是以摄像为核心功能的智能音频眼镜,且需要和手机配合使用。而VST方案的眼镜会在XR章节中展开讨论。
智能眼镜的优势和机会
近期Rayban Meta意外大卖,增强了Zuckerberg对智能眼镜这个形态的信心。Connect大会上,Meta发布了研发9年之久的AR眼镜原型机Orion。小扎对此如此笃定不无道理,因为眼镜作为传感器定位的智能穿戴设备确实有得天独厚的优势
此外,摄像眼镜在传播上也有天生的优势,从目前用户的行为来看,摄影摄像是主要的使用场景。Rayban Meta在内容创作者和大V中非常受欢迎,他们创作的POV视角的内容在社交媒体传播容易形成潮流效应,从而形成自传播。
在Rayban Meta取得成功后,海外大厂已经形成共识:Google决定与硬件合作伙伴三星探索类似形态,落地在Google I/O上惊鸿一瞥的Project Astra,苹果也开始重新审视自己的Vision产品线。
Rayban Meta:偶然的爆款,这一次不一样?
这并不是科技公司在眼镜上的第一次尝试,实际上这是一个命途多舛的品类。从Magic Leap,HoloLens一直到Meta Orion,钢铁侠Javis形态的智能眼镜一直是大家心目中的终极形态。
在诸多落地挑战中,最核心的问题是无法达到轻量化要求。具体到眼镜,行业普遍认为超过60g的眼镜(普通眼镜20g左右)无法提供长时间无感的舒适体验,而Rayban Meta在保持足够好的基础体验的前提下,将重量控制在50g左右。
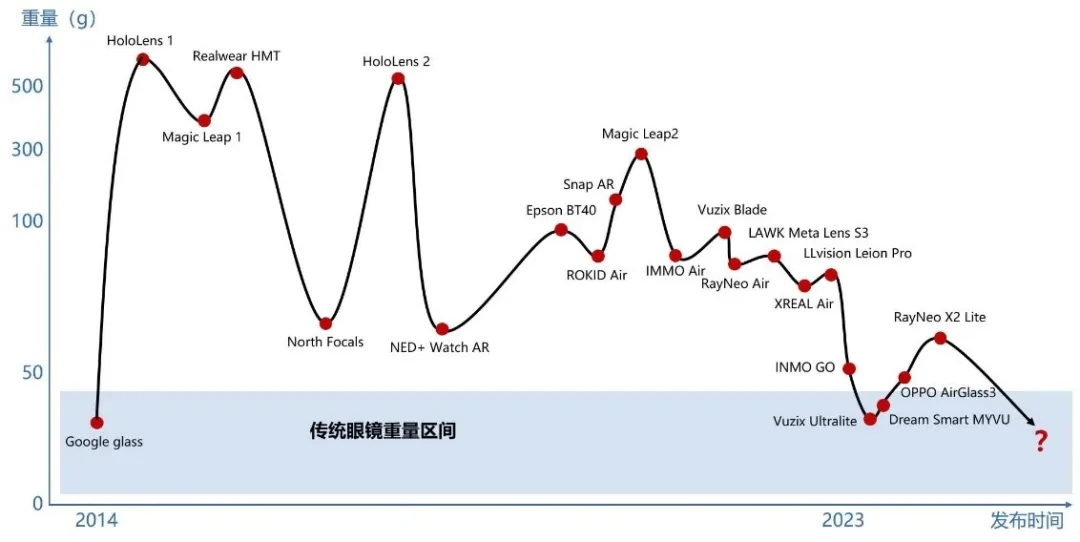
另外,近年来TikTok和Instagram等视觉系社交软件的风靡也为智能眼镜的普及扫清了障碍:在公共场景使用摄像头拍摄变得司空见惯。这曾是阻碍Google Glass普及的最大原因(Google Glass也极致轻量化)。
然而与Rayban的联名更像是一个计划外的产物,更准确地说是Orion做减法得到的产物。Meta负责研发硬件的Reality Labs由CTO Andrew "Boz" Bosworth负责,这是一个超过15,000人的庞大部门。Boz是Zuckerburg最信任的亲信之一,但在产品方向上Zuckerburg两次亲自做出了与Boz意见相左的决定,一次是在早期决定Quest走无线的一体机头显方案,另一次则是在2019年在评估Orion短期内无法量产后,要求转变方向与Rayban合作探索新的产品形态。
从科技角度来说,Rayban Meta是Orion技术的一次下放,但这样的功能取舍和组合,却意外地在重量、功能、设计和成本之间达到了消费者能接受的平衡。
从产品定义上,这与传统意义上通过视觉显示增强现实(“AR”)的定位不同,这是一款定位“living in the moment”,以摄影摄像为主要功能的产品。Rayban Meta是第二代产品,相比第一代产品Rayban Stories(第一代产品并没有AI功能),由于高通AR1芯片升级,在摄像(5MP提升至12MP)和音频上(3阵列到5阵列麦克风,加入空间音频;音量提升50%)都有明显的提升,并加入AI功能。此外,EssilorLuxottica也为Rayban Meta提供了更多的线下渠道覆盖。


智能眼镜形态的主要划分和优劣势
智能眼镜根据功能组合和视场角(“FOV”)大致可以分为以下几类:
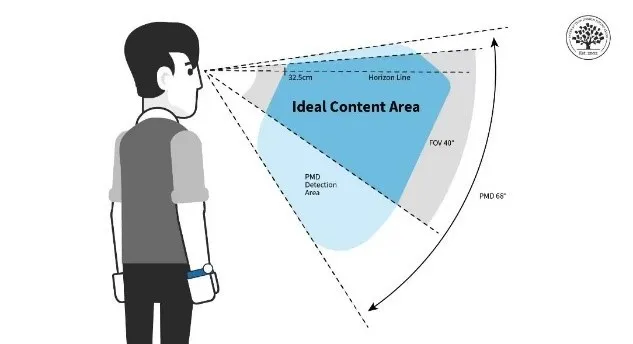
1. 不带显示的智能眼镜(已经能将重量控制在50g以内,符合轻量化要求)
2. 带显示的智能眼镜(能控制在100g以内,但在轻量化上还有提升空间)
不带显示的智能眼镜在轻量化和成本控制上已经相对成熟。但目前只覆盖AI硬件三层架构的第一层,并通过LUI提供有限的交互。纯音频眼镜收集信号密度有限,同时受制于系统权限,产品功能单薄,且与TWS耳机重合度高。另外电子消费品追求标准化的模式,并不能满足消费者对眼镜个性化多SKU的需求。从华为和小米的实际销量上看,只搭载音频带来的功能增强并没有提供足够强的说服力。
而带有摄像头的智能眼镜,在保留音频功能的同时,通过与手机配合使用,能解锁更多延伸场景,提供较好的基础体验。
在带显示方案的眼镜产品中,现有的成熟量产方案只能提供40-50度FOV的轻显示,定位鸡肋。一方面需要搭载光机带来额外的重量和成本,另一方面视场角有限,实际上只起到了通知中心(push center)和widget看板的功能。运用新一代技术的Even Realities G1等产品,虽然在轻量化上更进一步,但这类产品的落地场景目前集中于:实时翻译、导航、提词器等场景。这些场景中确实有不错的体验,但可以试想一下普通人使用上述三个场景的频次。
AI功能目前也仅限基于识图的任务延伸(类似Apple 16展示的功能)。除此之外,不少人幻想的使用场景,在OST方案中都在目前的技术边界之外。Orion也只能勉强提供几个鸡肋的场景。在某种程度上智能眼镜除摄影摄像和音频之外的功能都可以被智能手表覆盖。
选择比努力重要。对试错成本更高的硬件创业公司来说更是如此,虽然上海显耀等Micro LED公司近年取得一些技术突破,但显示方案受制于FOV,即使落地也无法独立支撑太多的应用场景,现在看来并不是最优的技术路线。
而Rayban Meta则为智能眼镜指明了方向,短期内取代不了手机,但眼镜保有量大,若出现类似汽车电动化的眼镜智能化趋势,市场体量也相当可观。但目前的主要缺陷是因为轻量化无法搭载高容量电池的情况下,如何控制芯片功耗从而实现更长续航。
各类AI陪伴和助手产品已经在软件层面验证了用户需求。在上一篇文章中已有详细论述。这里简单提三个可以硬件化的品类:AI语音秘书、AI智能玩具和陪伴机器人(电子宠物)。这几个方向同样需要软硬件结合的团队,同时理解AI大模型能力的边界,也能调动供应链资源投入量产。
AI语音秘书
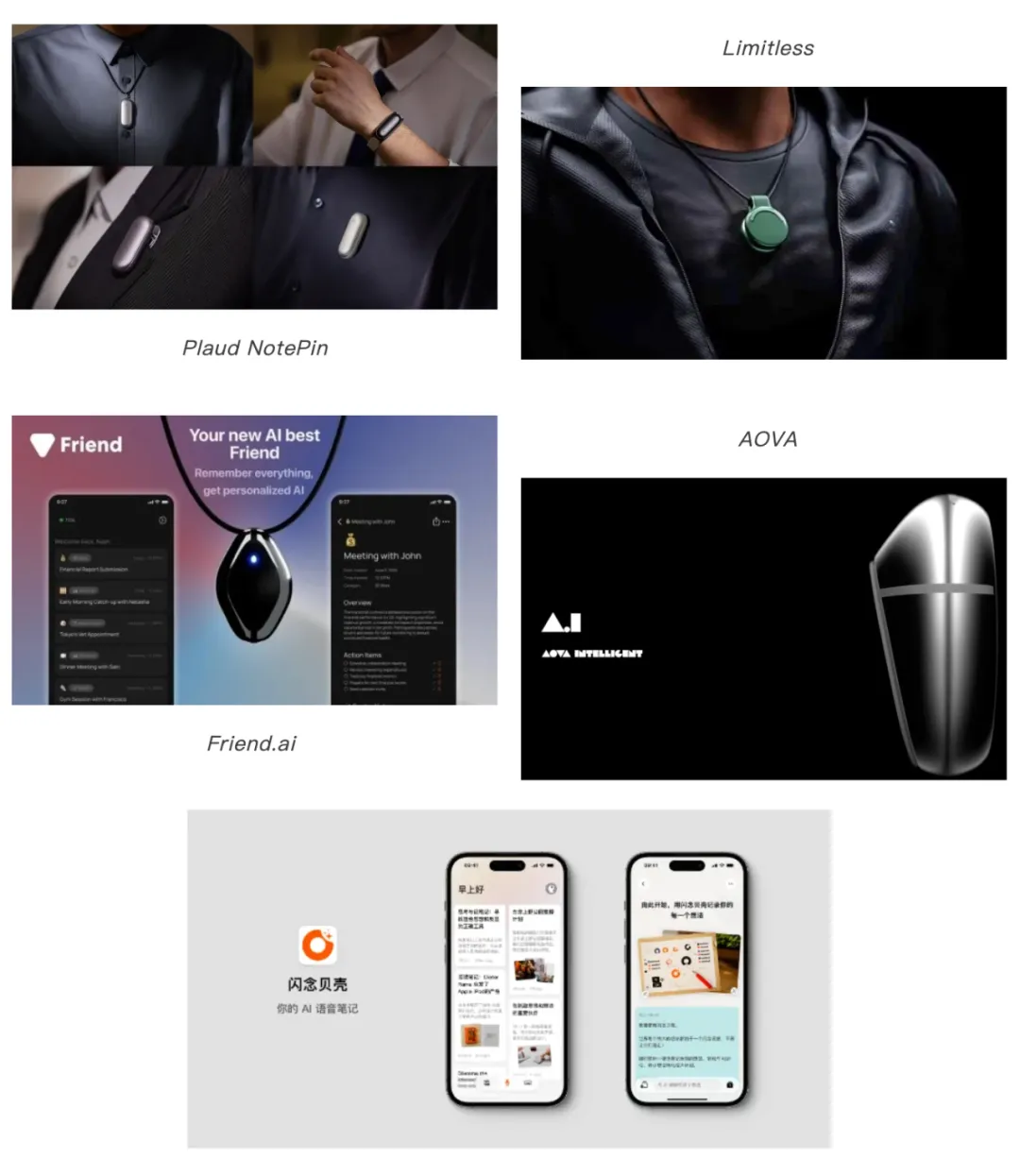
基于AI大模型在长文本理解和信息提取上的优势,一些团队开始在将长音频信息通过硬件收集并结合软件处理的AI语音秘书/第二大脑的方向进行探索。Rewind最先提出这个概念,并在软件场景得到需求验证后推出智能挂件Limitless(并将公司改名)。Plaud也在第一款产品Note在通话录音方向取得成功后,推出面向更长时长更广泛场景的NotePin。这些产品都有类似的特点:轻便随身且长时间待机,随时随地收集用户所处环境的音频信息。
Humane AI Pin虽然在功能和交互上惨败,但在硬件形态和佩戴方式上不无可取之处。离嘴和耳近且能方便触发功能是核心的用户需求,在外观上还不能太有侵略性。胸针、项链等配件是更加合适的选项。这其中Plaud NotePin的设计非常聪明,类似小米手环的设计不但容易适配多种场景,同时可以复用供应链资源。
如何在有限的空间内通过阵列麦克风组合实现空间音频适配,以及低功耗长续航是这类产品在硬件端需要攻克的难题。而在软件端,如何在海量的信息中,萃取信息价值是体现产品价值差异化的关键。
AI智能玩具
玩具是搭载LUI的理想硬件载体。一方面,小朋友需要的信息密度和精度要求相对不高,且语音的流式交互也可以被硬件一部分承载。另一方面,相比于纯软件的形态,通过硬件具象化也更方便用户代入情感寄托,提供更高的情绪价值。这个品类也符合“熟悉的陌生感”逻辑,用户教育门槛低,基本上手即可使用。
需要注意的是玩具的使用者和购买决策者分离,团队需要在软件后台针对家长的诉求(主要是安全控制和成长记录)有相对应的设计。
国内的跃然创新Haivivi和海外的Curio都陆续推出了产品,且获得不错的市场反响。Haivivi的第一款产品Bubble Pal取巧地采用了挂件的设计,一方面硬件形态相对简单容易快速量产,另一方面“蹭”了用户现有玩具的形象设计,规避了冷启动时外形设计的风险。但长期中,IP的授权和绑定将是这个品类的核心竞争力。

陪伴机器人
同样,针对成年人类似豆包的AI个人助理也可以被赋予硬件的“肉身”,将情绪和陪伴价值进一步延伸和固化。Looi是一款可移动手机支架形态的桌面机器人,在搭载基础AI大模型交互功能的基础上,团队还开发了配合物理移动的表情设计及世界观设定。这类产品在软件AI个人助理的基础上更进一步,通过与用户的物理交互建立更深层的情感连接。本质上这类产品是对桌面智能音箱、时钟等硬件的整合和体验提升。同时Looi的设计巧妙的将摄像传感器转移给手机,在一定程度上规避了这个品类中潜在的数据收集和隐私风险。
同样的思路也可以延伸至家庭地面机器人。三星的Ballie就是这个方向的一个代表,这个形态的产品可以结合扫地机器人和智能音箱的功能,甚至在某种程度上分担了宠物的部分情感陪伴功能。

影视作品「头号玩家 Ready Player One」生动地描绘了人类对XR产品的想象。从早期的Oculus Rift,HTC Vive到Magic Leap, HoloLens,再到现在的Quest,Vision Pro和Pico。XR产品的发展在过去10年,已经走过了“10个元年”,在技术程度曲线(the hype curve)上经过了从「过高期望的峰值」跌落「去泡沫的谷底」的过程,目前正处于线性稳步向前的阶段,但离大规模普及实现指数性增长的阶段尚有距离。除了软件和硬件的技术边界之外,XR设备本身具有单次使用门槛/仪式感高、佩戴和使用体验高度个人化且不易分享的特性,使得产品入门阈值一直较高。
总的来说,VR方向硬件产业链、光学方案和软件生态的方向都已经基本确定,在Vision Pro指明OS和交互逻辑后,未来3年行业将持续稳步打磨产品。而在AR方向,光学方案尚未收敛,产业链也处在早期阶段,虽然梦想美好,但现实很残酷。就算是天顶星的Orion,在3-5年之内都不会量产。
行业在AR领域的迷茫,一部分原因是现阶段硬件技术边界的限制,但我认为也有很大一部分原因是从业者被对显示的执念束缚。AR(augmented reality)现实增强的定义简单可以概括为:增强能力,解放双手。视频显示固然能带来最强的现实增强,但人有五感(即多模态),通过音频等其他形式带来的能力增强,双手解放,广义上也是AR。Rayban Meta因为不带显示不被部分从业者认为是AR眼镜(包括Meta CTO Boz一度也这么认为),但在广义下,却实现了AR的目标。
苹果和Meta无疑是过去5年为争夺「头号玩家」投入最多的两家厂商。两家分别采用了不同的战略路径,这里做一个简要的总结和现状的分析。

苹果
战略侧重VST的MR方向,闭源路径,高端定位,希望从效率场景切入。
从目前的情况来看,万众期待的首款产品Vision Pro已经失败,失败的核心点不在于销量(本身也没有很高的预期),而是没有在先锋人群中形成时尚效应。在过往新品类发布中,无论是Apple Watch还是AirPods,苹果都能通过顶尖的广告和推广在最酷的人群中产生示范效应从而带动后续更大众系列的普及,但在Vision Pro上并没有成功。
但这款产品也并非一无是处,其出色的交互设计和空间定位,为行业指明方向。
Meta
同时布局OST方向AR产品(Orion)和VST方向VR产品(Quest)
Quest以游戏主机定位起步,无论从定价还是内容供给都进行强锚定以带动销量和用户覆盖。Quest2取得阶段性成功步入千万量级销量。从Quest3开始加入彩透功能开始向MR结合的更多场景拓展,在Vision Pro发布后,明确OS和交互模式将会向苹果靠拢。Quest4的主要定位预计是无限靠近Vision Pro的体验,但有明显价格优势。
AR方向产品Orion 3-5年内不会量产落地。
比较可惜的是国内的PICO,在被字节收购后被没有得到应有的整合。砸出100亿人民币后,便战略收缩。最可惜的是研发并未占投入大头,且没有像苹果和Meta一样形成技术体系(研发成果可以在多款产品继承)。
总的来说,未来3年的主力机型(Meta Quest3/3s/4和Apple Vision/Pro)都无法将用户基数带过指数级增长的拐点,而只能在千万级别线性增长。这个级别的用户体量可能对游戏之外的应用品类来说相对有限,但在XR用户的价值在于对低龄用户的渗透:无论是海外的Gorilla Tag,VRChat还是国内的轻世界都有比例相当大的低龄用户。随着这个年龄XR原生用户的发展壮大和购买力增强,长期渗透率的拐点将可能出现。
另外,AI大模型技术的出现可能也会在VST方案的设备中引入新的趋势。在内容生产端,AI多模态内容生成工具将有效降低VR内容制作门槛(特别是3D内容),长期中可能会出现Roblox、蛋仔派对形态的UGC平台。更为重要的是在交互端,显示渲染系统与AI内容生成技术天然易结合,可能出现一个重要的交互场景变化,即将内容创作者的摄像头向另一端投射 - 「POV视角」- 的创作,而AI内容生成技术将让「世界滤镜」成为可能,从而衍生出更多的玩法,在真正意义上实现现实增强 ("AR") 的体验。Snapchat Spectacles的宣传片中已经demo了这种场景,苹果内部对这个方向的确定性也非常笃定。
目前已有一些GenAI公司尝试在这条路线探索,AI图像生成公司Midjourney因为创始团队Magic Leap的背景更是对此深信不疑,据我了解团队目前在同时研发VR设备在内的多条技术路线。但目前的主要挑战是:
受篇幅限制,不在这里展开讨论现阶段具身智能方向的投资价值。主要谈一谈两个问题:1) 造成目前行业投资热情的原因;2)当下需要面对的主要技术挑战
具身智能同时在中美两个市场掀起热潮,无疑是今年国内市场融资最活跃的赛道。背后的核心原因是资本需求和项目供给的关系。
在资本需求端,海外市场明星项目Tesla Optimus,Figure,1X等在市场制造声量,一定程度上起到示范科普作用,黄仁勋在英伟达GTC大会上和一众机器人的同框亮相更是将市场的热情拉满。另一方面,我国的政策也十分支持机器人相关的高端制造业。结果上导致美元和人民币背景的基金都有配置的兴趣和需求。

在项目供给端,具身智能主要包括大脑、小脑和本体三个系统,分别要求团队在机器视觉、AI大模型、通用移动、运动控制、硬件机械等多个跨学科交叉领域都有深厚的技术储备。根据我们对人才库的梳理,在具身智能创业方向可以独当一面的顶级华人人才不超过30人。具身智能是最近几年兴起的前沿研究方向,更多的人才还在学界和业界做研究,或者对产业缺乏经营上的认识和经验。而从机器视觉、自动驾驶等领域跨界创业的团队还在学习适应中。
虽然与自动驾驶相比,具身智能资本投入需求相对可控,但机器人自由度之多控制之复杂,让实现更拟人的智能这件事的难度不亚于任何一项复杂的系统工程。
高质量团队稀缺和资本配置兴趣旺盛之间供不应求的关系直接造成了目前行业火热的氛围。
大语言和多模态模型的技术突破,让具身智能在大脑和小脑控制上得到大幅提升,但我们也应该正视需要攻克的技术难点:
数据采集的成本和质量
相较于专机专用的传统机器人,具身智能的核心技术进步是跨场景任务的通用性。通用性包括两个方面:
2.场景通用:针对不同场景,执行多样化任务
为了实现通用性,参考AI大语音模型的scaling law,就需要大规模高质量的训练数据来提升智能。相较于语言模型的数据语料,具身智能要求的训练数据维度更高。除了常见的用于物体识别的视频信息之外,具身智能的训练还需要涉及力反馈的交互信息和空间位置等高维度高质量的数据集。在现有的技术架构下,只能通过工程手段解决刚性物体低精度通用操作。更高阶的柔性物体高精度通用操作还属于待攻克的科学问题。
具身智能公司能否像特斯拉卖车一样找到可持续收集大规模高质量训练数据的方式是长期核心竞争力。如若不然,可能将重走L4自动驾驶初创公司的老路:数据采集成本高企,但规模和质量都达不到scale up的门槛。
具体在场景选择上,我并不看好工业场景。以汽车生产线为例,大部分工序都高度流程化并可以通过机械臂为主的流水线严格完成,也就是说这类场景数据并不具备很好的通用泛化性。而具有泛化可能的场景(如座椅装配)现阶段对机器人来说难度过高。
在家庭和服务场景虽然数据通用泛化性理论上来说更好,但也充满挑战。具体到家庭场景,目前的具身智能方案在鲁棒性和效率上离商用还有明显距离,而在服务和陪伴场景中与人和物体的物理交互有限,很难收集力反馈信息。
此外,合成数据在具身智能训练上的有效性和通用性也需要进一步证明。
硬件的选型和适配
现阶段具身智能公司的产品主要以demo性质为主,因此硬件选型上同质化高。但进入具体落地阶段,需要面对「一脑多形」的挑战,如何针对场景设计机器人的形态,并进行传感器、零部件和电机的选型适配也需要通过实践进行打磨。
同时,传感器排布和硬件配置改变后,训练数据是否还能复用等问题都需要在时间中进行验证。
团队长期融资能力
机器人单价相比汽车来说相对可控,但批量收集数据依然需要千台以上的机器部署,在短期很难实现单机盈利的情况下,如何在规模化和成本控制之间找到平衡也是团队需要面临的调整。Figure等过于强调demo和叙事的公司已经在业内引起警觉,其CTO Jerry Pratt也于今年离职。当市场情绪回归理性,明星公司交付不及预期时,如何持续保持融资能力也是具身智能团队需要具备的能力。
最后非常感谢你耐心地读到这里。如果这篇文章能让你记住一句话,我希望是:
Hardware is hard. Survival is the name of the game. 相比于软件,其实制约AI硬件、XR设备和具身智能发展的最大卡点是电池能量密度,如果电池材料取得突破将在这些领域都带来一次大的飞跃。
文章来自于微信公众号“鹿其鹿粦Chilling”,作者“Aaron Qian”



【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
