# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
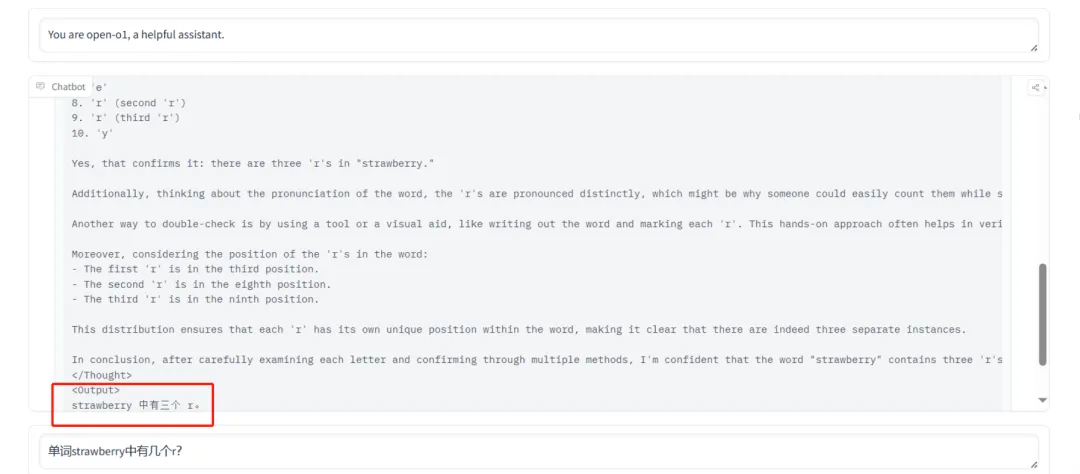
OpenAI o1团队花了半年时间教会o1 "strawberry中有几个r",一个开源项目做对了!
这几天,想撸代码的心按不住了,发现了一个有点牛的开源项目,名为Open O1,是一个名为@OpenSource-O1 的团队,在github上开源的项目,目的是追齐OpenAI o1 模型的强大功能。可以理解是一个开源版小号o1。
不要小看这个开源项目,【strawberry中有几个】难道了绝大多数大模型的题目,它竟然对了。
这是10个主流模型的回答结果:

只有o1和Gemini答对了,正确率只有30%。
它准确地答出了有3个。
牛!
而且,只有7B和8B的参数,还是个小模型,基于LLama-8B和Qwen-7B进行的微调。目前release的模型只有两个型号:
10月5号首次发出来,9号昨天release的模型。

它怎么做到的?
该团队通过整理了OpenAI o1模型的CoT(思维链)数据,对Llama3.1-8b和Qwen2.5-7b模型进行训练,赋予了这两个小体量模型更强的长期推理和解决问题的能力。
看一下项目主页的demo吧:
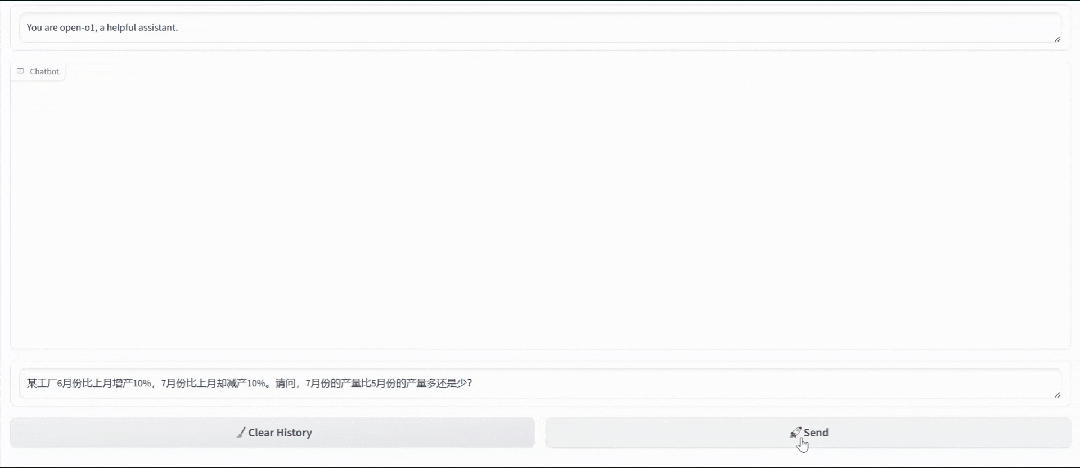
该模型的github页面:
https://github.com/OpenSource-O1/Open-O1
huggingface链接:
https://huggingface.co/spaces/happzy2633/open-o1
直接拿几个问题简单测一下咯~

看来,简单的逻辑题是难不倒这个模型了。
对于复杂一些的题目,这里直接贴上官方提供的示例:



import curses
import time
import random
def main(stdscr):
# 初始化curses
curses.curs_set(0) # 隐藏光标
stdscr.nodelay(0) # 等待输入
stdscr.keypad(True) # 启用特殊键
height, width = stdscr.getmaxyx()
window = curses.newwin(height, width, 0, 0)
window.keypad(True)
window.nodelay(1)
window.border(0)
window.refresh()
# 初始化蛇和食物的位置
snakes = [(height//2, width//2 + 1), (height//2, width//2), (height//2, width//2 -1)]
direction = curses.KEY_RIGHT
food = (height//2, width//2 +2)
# 初始化得分
score = 0
# 生成食物
def make_food(snakes):
food = None
while food is None:
food = (random.randint(1, height-2),
random.randint(1, width-2))
if food in snakes or food in [tuple(pos) for pos in snakes]:
food = None
return food
food = make_food(snakes)
# 游戏主循环
while True:
next_key = window.getch()
if next_key in [curses.KEY_UP, curses.KEY_DOWN, curses.KEY_LEFT, curses.KEY_RIGHT]:
direction = next_key
head = snakes[0]
new_head = (head[0], head[1])
# 根据方向移动
if direction == curses.KEY_UP:
new_head = (head[0] -1, head[1])
elif direction == curses.KEY_DOWN:
new_head = (head[0] +1, head[1])
elif direction == curses.KEY_LEFT:
new_head = (head[0], head[1] -1)
elif direction == curses.KEY_RIGHT:
new_head = (head[0], head[1] +1)
# 检测碰撞
if (new_head in snakes or
new_head[0] in [0, height -1] or
new_head[1] in [0, width -1]):
break
# 更新蛇的位置
snakes.insert(0, new_head)
# 检测吃食物
if new_head == food:
score +=1
food = make_food(snakes)
else:
snakes.pop()
# 绘制蛇和食物
window.clear()
window.border(0)
for pos in snakes:
window.addch(pos[0], pos[1], '#')
window.addch(food[0], food[1], '*')
window.refresh()
time.sleep(0.1)
# 显示得分
window.addstr(height//2, width//2 -5, f"游戏结束,得分: {score}")
window.refresh()
time.sleep(2)
curses.wrapper(main)
有没有小伙伴运行一下试试?

患者 ID:P004
出生日期:2000-03-10
性别:男 病史:无
当前药物:阿莫西林
过敏:青霉素
实验室结果(葡萄糖 mg/dL):95
诊断:感染
治疗方案:开阿莫西林。


有一说一,看起来效果真的不错!
不过,这毕竟只是7b、8b的小模型,自然是无法还原OpenAI o1模型的全部实力。官方给出的benchmark仅与Llama3.1-8b-instruct进行了比较,在MATH、MMLU、ARC-C和BBH方面,该模型均有显著改进。

当然了,这毕竟也是第一个模型,还是0.1版本的模型。
Open-Source O1团队希望:
随着Open O1项目的进展,继续突破大语言模型的界限,不仅能实现类似OpenAI o1的CoT的性能,还能在测试时间扩展方面处于领先地位,使所有人都能使用先进的AI功能,最终,将Open O1变成人工智能进步的灯塔,造福所有人。
还有项目声明:
Open O1还远远达不到OpenAI o1的水平,但他们正在路上。第一个版本的模型提供了一些有希望的数据,但风格仍然非常接近OpenAI o1。该项目是非营利性的,团队欢迎整个社区加入该项目的发展旅程。展望未来,该团队将开源开发过程中的所有代码和材料。
另外,看到Open O1项目的贡献人一栏,发现了其一贡献者来自武汉大学,团队具体详情暂时没有公布。

最后,附上该模型的github页面:
https://github.com/OpenSource-O1/Open-O1
该模型也可在huggingface Space中使用:
https://huggingface.co/spaces/happzy2633/open-o1
文章来自于微信公众号“夕小瑶科技说”,作者“海野”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
