# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
未来的大模型,或许都是 A 卡来算的?
从 PC 端到服务器,AMD 一次发布就完成了对 AI 计算的全覆盖。
今天凌晨,AMD 首席执行官苏姿丰(Lisa Su)在旧金山举行的 Advancing AI 2024 活动上发布了全新一代 Ryzen CPU、Instinct AI 计算卡、EPYC AI 芯片等一系列产品。

苏姿丰表示,在未来,人工智能将提高每个人的生产力。通过实时翻译等功能,人与人的协作将变得更加高效,无论创作者还是普通用户,生活都将变得更轻松。除此以外,更多的 AI 任务将在本地进行处理,以保护你的隐私。
基于这样的愿景,新一代 AMD Ryzen AI Pro PC 将支持 CoPilot+,并提供多至 23 小时的电池续航时间。
「我们一直与 AI PC 生态系统开发人员密切合作,」苏姿丰说道,并指出到今年年底将有 100 多家公司致力于开发 AI 应用程序。

首先是 CPU。AMD 今天推出了专为 PC 设计的全新 Ryzen AI Pro 300 系列处理器。新款 CPU 采用 4nm 工艺打造,使用该公司最新的微架构,结合 GPU 与 Microsoft Copiliot+ 认证的神经处理单元 (NPU),可实现 55 TOPS 性能的 AI 算力。
AMD Ryzen AI Pro 300 系列 CPU 处理器代号为 Strix Point,最多有 12 个 Zen 5 核心、RDNA 3.5 GPU,最多 1024 个流处理器,包含最新的 XDNA 2 NPU,性能为 50 TOPS – 55 TOPS(8-bit),以及一组适用于商用 PC 的功能,如远程管理、增强的安全功能(内存加密、安全启动过程、AMD 安全处理器 2.0、TPM 2.0)、云恢复和看门狗定时器。
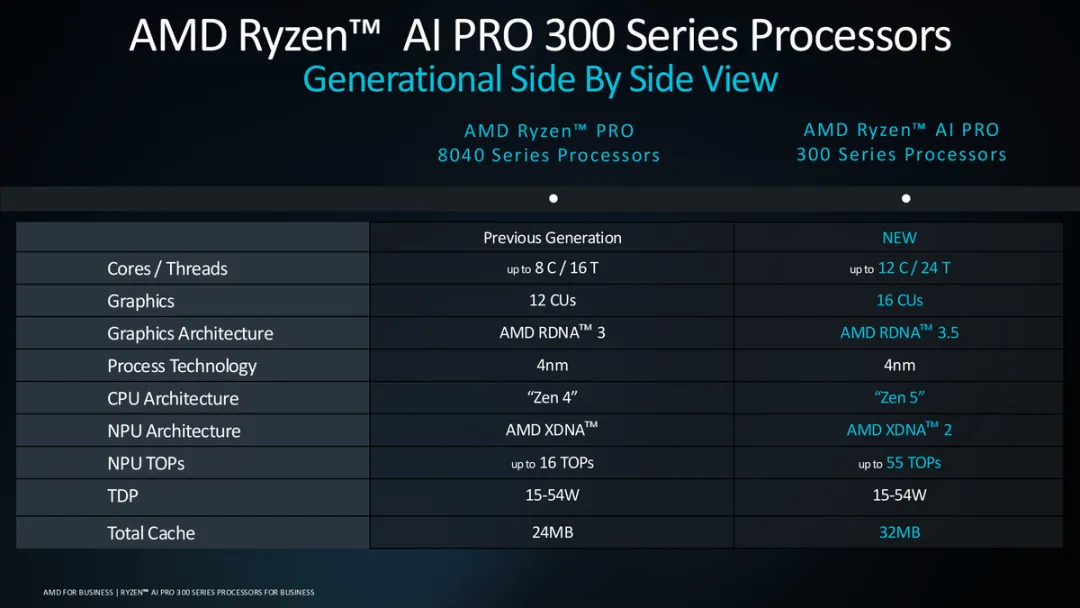
目前,AMD 的 Ryzen AI Pro 300 系列产品线包括三种样式:最高端的 12 核 Ryzen AI 9 HX Pro 375,配备 55 TOPS NPU;速度稍慢的 12 核 Ryzen AI 9 HX Pro 370,配备 50 TOPS 算力的 NPU;以及八核的 Ryzen AI 7 Pro 360,配备 50 TOPS 的 NPU。
与英特尔 Core Ultra 7 165U 相比,最高版本的 Ryzen AI 9 HX PRO 375 可提供高达 40% 的性能提升和高达 14% 的生产力提升。
与往常一样,HX 版本的 TDP 高达 55W,面向高性能笔记本电脑(包括一体机),而常规处理器的 TDP 可以固定为低至 15W。

与上代 AMD Ryzen Pro 7040 系列处理器相比,Ryzen AI Pro 300 不仅具有显著更高的通用和图形性能,而且还支持微软的 Copilot+ 功能,其将在 11 月的下一次 Windows 更新中推出。AMD 在发布活动中宣传了 Copilot+ 的实时字幕和实时翻译、Cocreator 以及颇具争议的 Recall 功能 —— 这些都是新 CPU 支持的关键能力。
除此之外,其中的 NPU 还支持各种第三方软件供应商带来的 AI 增强应用,例如来自 Adobe、Bitdefender、Blackmagic Design 和 Grammarly 等公司的产品。
AMD 表示,到 2025 年,Ryzen AI Pro 平台将搭载于超过 100 款产品中,惠普和联想将率先在其商用 PC 上采用 Ryzen AI Pro 300 系列处理器。
最近,全球 AI 芯片供不应求,AMD 已成为 GPU 领域的重要玩家,今天该公司宣布了最新的 AI 加速器和用于 AI 基础设施的网络解决方案。

具体而言,AMD 推出了 AMD Instinct MI325X 加速器、AMD Pensando Pollara 400 网络接口卡 (NIC) 和 AMD Pensando Salina 数据处理单元 (DPU)。
AMD 声称 AMD Instinct MI325X 加速器为 Gen AI 模型和数据中心树立了新的性能标准。
AMD Instinct MI325X 加速器基于 AMD CDNA 3 架构构建,旨在为涵盖基础模型训练、微调和推理等要求苛刻的 AI 任务提供性能和效率。
AMD Instinct MI325X 加速器提供了业界领先的内存容量和带宽,256GB HBM3E 支持 6.0TB/s,比英伟达 H200 提供了高 1.8 倍的容量和 1.3 倍的带宽。与 H200 相比,AMD Instinct MI325X 的峰值理论 FP16 和 FP8 计算性能提高了 1.3 倍。
这种领先的内存和计算性能,较于英伟达 H200,能够在 FP16 精度下,为 Mistral 7B 模型提供高达 1.3 倍的推理性能,在 FP8 精度下为 Llama 3.1 70B 模型提供 1.2 倍的推理性能,同时在 FP16 精度下为 Mixtral 8x7B 模型提供 1.4 倍的推理性能。
AMD Instinct MI325X 加速器目前有望在 2024 年第四季度投入生产,预计从 2025 年第一季度开始将在包括戴尔、Eviden、技嘉、惠普、联想等在内的众多平台提供商的系统中广泛使用。
此外,AMD 还更新了其年度路线图,即下一代 AMD Instinct MI350 系列加速器。基于 AMD CDNA 4 架构,AMD Instinct MI350 系列加速器的推理性能比基于 AMD CDNA 3 的加速器提高了 35 倍。

具体来说,MI300X 目前能提供 1.3 petaflops 的 FP16 算力和 2.61 petaflops 的 FP8。相比之下,MI355X 将分别将其提升至 2.3 和 4.6 petaflops。与上一代相比,这个数字提高了 77%。
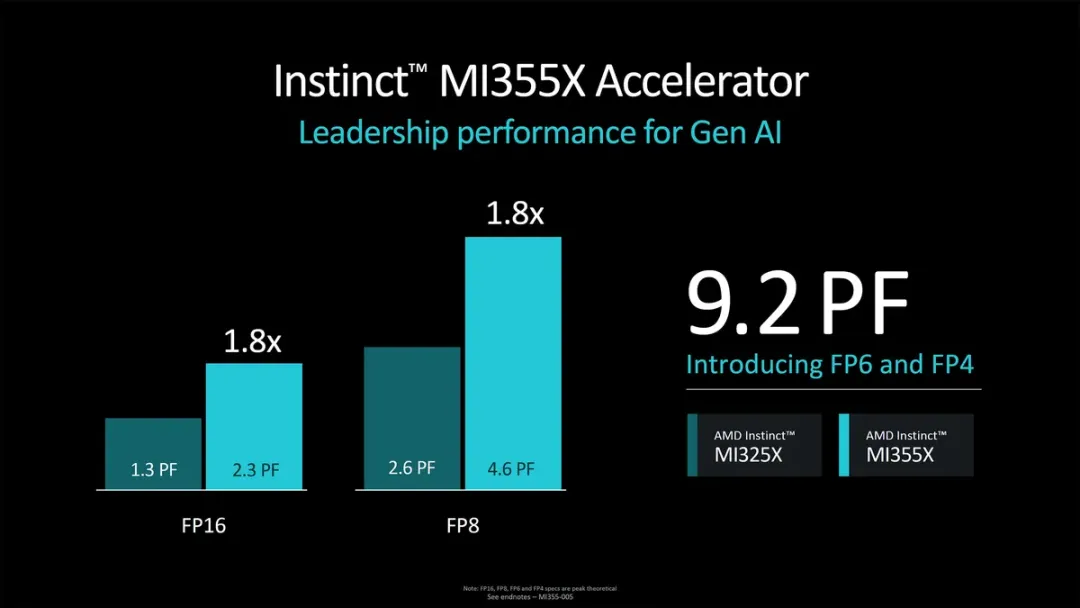
MI355X 不仅拥有更多的原始计算能力。FP4 和 FP6 数字格式的引入使潜在算力相对于 FP8 再次翻倍,因此单个 MI355X 可提供高达 9.2 petaflops 的 FP4 计算能力。这是一个有趣的数字,因为英伟达 Blackwell B200 也提供了 9 petaflops 的密集 FP4 计算能力 —— 功率更高的 GB200 可以为每个 GPU 提供 10 petaflops 的 FP4。
仅基于该规格,AMD 的 MI355X 可能提供的 AI 计算能力与英伟达的 Blackwell 大致相同。然而,AMD 还将提供高达 288GB 的 HBM3E 内存,这比目前 Blackwell 的内存多出 50%。Blackwell 和 MI355X 的每块 GPU 都将具有 8 TB/s 的带宽。
AMD Instinct MI350 系列加速器有望在 2025 年下半年上市。
「毫无疑问,AMD 凭借 EPYC 拉大了与英特尔之间的差距。目前,它在高端市场占有 50-60% 的份额,而且我认为这一趋势不会减弱。AMD 面临的最大挑战是获得企业市场份额。AMD 需要在销售和营销方面投入更多资金,以加速其企业增长,」Moor Insights & Strategy 分析师 Patrick Moorhead 表示。「很难评估 AMD 与 NVIDIA 在数据中心 GPU 方面的地位。到处都有数据,两家公司都声称自己更胜一筹。」
Moohead 补充道:「我可以毫不含糊地说,AMD 的新 GPU,尤其是 MI350,与前代产品相比,效率和性能都有所提高,对低比特率模型的支持也更好,这是一个巨大的进步。这是一场激烈的竞逐,英伟达遥遥领先,AMD 正在迅速追赶并取得了有意义的成果。」

AMD Pensando
AMD 正在利用可编程 DPU 为超大规模计算提供动力,为下一代 AI 网络提供支持。
AI 网络分为两部分:前端(向 AI 集群提供数据和信息)和后端(管理加速器和集群之间的数据传输)。
为了有效管理这两个网络并推动整个系统朝着高性能、可扩展和高效率发展,AMD 推出了用于前端的 AMD Pensando Salina DPU 和用于后端的 AMD Pensando Pollara 400。
AMD Pensando Salina DPU 是全球性能最高、可编程性最强的第三代 DPU,与上一代相比,其性能、带宽和规模提高了两倍。AMD Pensando Salina DPU 支持 400G 吞吐量,可实现快速数据传输速率,是 AI 前端网络集群中的关键组件。
AMD Pensando Pollara 400 搭载了 AMD P4 可编程引擎,是业界首款支持 UEC(Ultra Ethernet Consortium) 的 AI NIC。它支持下一代 RDMA 软件,并由开放的网络生态系统提供支持。
AMD Pensando Salina DPU 和 AMD Pensando Pollara 400 均于 2024 年第四季度向客户提供样品,并有望于 2025 年上半年上市。

AMD 在旧金山举行的「Advancing AI 2024」活动。
AMD 将对软件功能和开放生态系统进行投资,以在 AMD ROCm 开放软件堆栈中提供强大的新特性和功能。
在开放软件社区中,AMD 正在推动 AI 框架、库和模型(包括 PyTorch、Triton、Hugging Face 等)对 AMD 计算引擎的支持。这项工作使得 AMD Instinct 加速器在流行的生成式 AI 模型(如 Stable Diffusion 3、Meta Llama 3、3.1 和 3.2)以及 Hugging Face 上的一百多万个模型上提供开箱即用的性能和支持。
除了社区之外,AMD 还继续推进 ROCm 开放软件堆栈,为用户带来最新功能以支持生成式 AI 工作负载的领先训练和推理。
现在,ROCm 6.2 支持很多 AI 应用,例如 FP8 数据类型、Flash Attention 3、Kernel Fusion 等。与 ROCm 6.0 相比,ROCm 6.2 在推理方面提供了 2.4 倍的性能改进,在各种 LLM 的训练方面提供了 1.8 倍的性能改进。

在服务器端,Zen 架构已经让 AMD 的市场份额从 2017 年的零上升到 2024 年第二季度的 34%。
AMD 揭开了其全新 Zen 5 架构服务器 CPU 系列的详细细节。第五代 EPYC「Turin」处理器 CPU 适用于企业、AI 和云服务用例。
AMD 已将其具有全功能 Zen 5 内核的标准扩展优化模型和具有密集 Zen 5c 内核的扩展优化模型统一为一个堆栈,该堆栈以 EPYC 9005 Turin 为名,与英特尔的竞争对手 Xeon 处理器相比,性能表现令人印象深刻。
AMD 声称,其旗舰产品 192 核 EPYC 9965 比英特尔竞争对手的旗舰产品 Platinum 8952+ 快 2.7 倍,速度提升显著。在具体应用方向上,还包括视频转码速度提高 4 倍、HPC 应用程序性能提高 3.9 倍、虚拟化环境中每核性能提高 1.6 倍。AMD 还宣布推出其新的高频 5GHz EPYC 9575F,据称在用于加速 AI GPU 工作负载时,它比 Zen 4 EPYC 型号要快 28%。
值得注意的是,AMD 并未在本代推出带有堆叠 L3 缓存的 X 系列型号,而是暂时依赖其 Milan-X 系列。AMD 表示,其 X 系列可能会隔代进行升级。
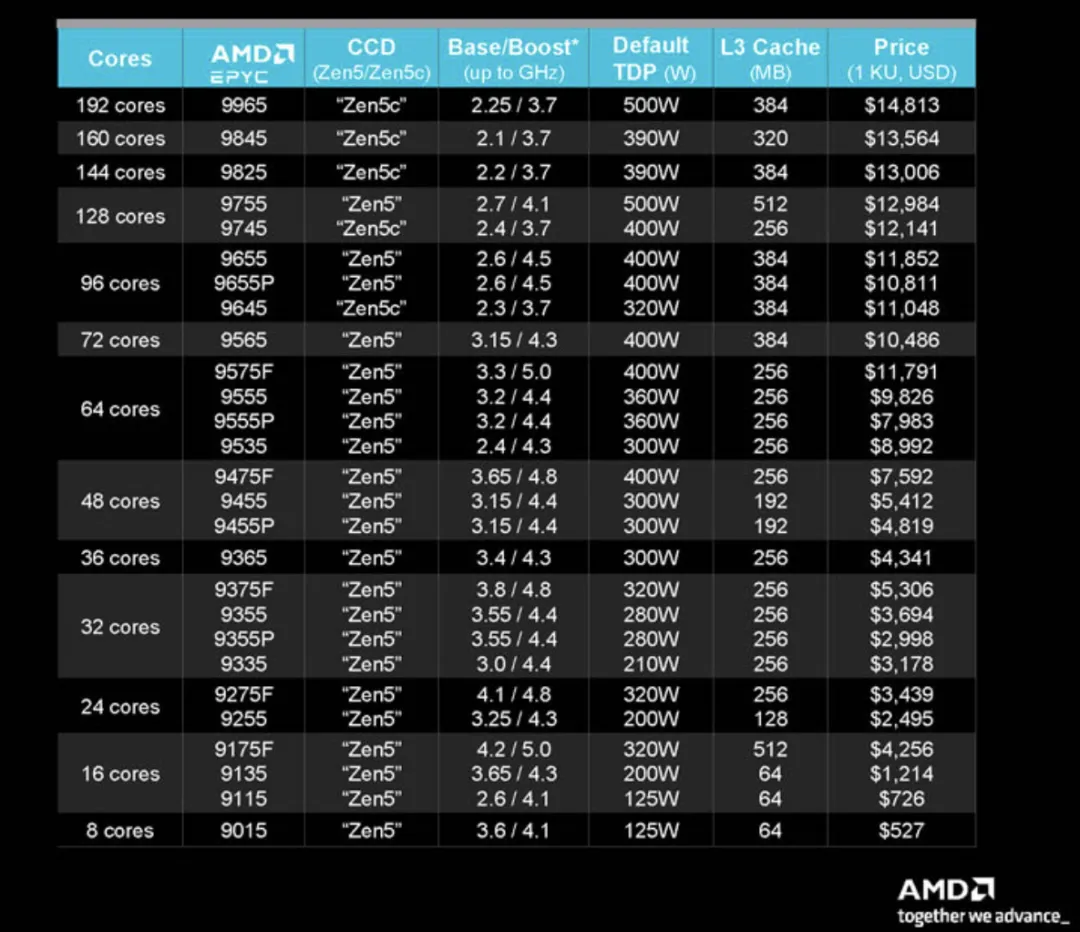
AMD 的新系列最高端是一款 14813 美元的 192 核 / 384 线程 EPYC 9965,这是一款 500W 功率的庞然大物,利用台积电的 3nm 节点通过密集的 Zen 5c 内核实现极致的计算密度。还有另外五款 Zen 5c 驱动的型号,包括 96、128、144 和 160 核心的型号,适用于高密度应用。
标准型号的 Zen 5 内核在 4nm 节点上制造,最高可达 128 个内核和 256 个线程 —— 售价 12984 美元的 EPYC 9755。该堆栈共有 22 种型号,从仅仅 8 个内核开始,这是 AMD 为响应客户需求而创建的全新小内核级别。AMD 在其产品堆栈中还散布了四个单插槽「P」系列型号。
AMD 的标准 Zen 5 系列现在包括新的高频 SKU,最高可达 5.0 GHz,这是 AMD 数据中心 CPU 系列的新高水准,可最大限度地提高 GPU 编排工作负载的性能。AMD 共有五种 F 系列型号,适用于不同级别的性能和内核数。

标准 Zen 5 型号采用多达 16 个 4nm CCD(核心计算芯片,又称小芯片)。它们与大型中央 I/O 芯片配对,每个 CCD 提供多达 8 个 CPU 核心,TDP 范围从 155W 到 500W。Zen 5c 型号采用多达 12 个 3nm CCD,每个小芯片有 16 个 Zen 5c 核心,与相同的 I/O 芯片配对。
AMD 声称,基于全新 Zen 5 架构的 RPYC 9005 系列的 IPC 增加了 17%。Zen 5 还显著增加了对 AVX-512 的完整 512b 数据路径支持,不过用户也可以选择在「双泵」AVX-512 模式下运行芯片,将 512b 指令作为两组 256b 发出,从而降低功率要求并提高某些工作负载的效率。
除了旗舰 192 核型号外,所有 Turin 处理器都可以放入现有的服务器平台采用 SP5 插槽。192 核型号也适用于 SP5 插槽,但需要特殊的电源配置,因此该高端型号需要较新的主板。
Turin 系列仅提供 12 个 DDR5 内存支持通道,每台服务器的内存容量高达 12TB(每插槽 6TB)。AMD 最初将 Turin 的规格定为 DDR5-6000,但现在已将其提高到合格平台的 DDR5-6400。AMD 的平台仅支持每通道 1 个 DIMM(DPC)。
对于 AMD 来说,目前面临的环境即是机遇也是挑战,如何能将架构、制程上的优势转化为胜势?从今天凌晨的发布会上,我们或许已经看到端倪。
参考内容:
https://www.youtube.com/watch?v=vJ8aEO6ggOs
https://www.tomshardware.com/tech-industry/artificial-intelligence/amd-reveals-core-specs-for-instinct-mi355x-cdna4-ai-accelerator-slated-for-shipping-in-the-second-half-of-2025
https://www.tomshardware.com/pc-components/cpus/amd-unveils-ryzen-ai-pro-300-cpus-zen-5-and-copilot-pcs-for-businesses-and-enterprise
https://venturebeat.com/ai/amd-unveils-ai-infused-chips-across-ryzen-instinct-and-epyc-brands/
文章来自于微信公众号“机器之心”,作者“关注AI芯片的”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
