# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
三个月前我在硅谷沉浸式泡了两个多月把产品上的整体感受和几个趋势简短写在了这里,在和不同的创业者交流研究了 40 多个产品后,最终回归到了“语音”这个方向,写下“Voice is a big thing”,语音产品是我认为 AI 在 C 端领域的核心变革点。

“语音正在成为一个较稳定的接口扩宽人们与产品交互的物理边界,可以重点关注的几个方向:语音 for 搜索、情感疗愈、社交、音乐等内容创作。”
我写完这篇文章,算是给自己的汇报后就迫不及待地开始做一款很有意思的语音产品。这三个月经历了闭关与起起落落,对现在的实时语音交互能力边界和语音更适合做什么样的事有了更深入的理解。
本篇记录最近做语音产品的思考,包括以下内容:
1. 语音是一种怎样的信息模态?
2. 口语对话?人类最早的交流方式
3. 语音产品(Voice-first),有什么特点?
4. 语音产品(Voice-first),为什么是现在?
5. LUI 还是 GUI?如何做一款 Voice-first 产品?
文字、语音、图片、视频,广义来讲这些不同的内容模态各自成为一种”语言“,我们借以选择一种语言进行自我表达,并与他人进行交流、与机器进行交互。
我们能够思考的事物往往局限于我们能够用语言表达的事物,不论是音频还是文字、图像,不同的语言表达方式也决定了思维方式的不同。
维特根斯坦在早期写《逻辑哲学论》的时候提出“语言的界限决定了思维的界限”,即语言不仅是一种表达工具,也是一种思维的框架,它影响着我们如何理解和组织世界。但其实,不仅仅是中文、英文、拉丁语系等语言体系,文字、音乐、图像等“语言”也在很大程度上塑造了我们的认知世界。
这也影响着人们与他人和机器交互的习惯,由此决定了不同产品的核心内容模态和“表达方式”。从产品的第一内容模态出发,可以把产品分为一下几类,各自的代表性产品举例如下:
文字类|Text-first:文字是人类发明的记录工具,最早的文字记载是被用来记数字的财务帐本,代表产品:书(书也是一种产品不是吗)。
文字是线性的,思想是网状的。
美国认知科学家、心理学家、语言学家史蒂芬·平克认为,写作的本质在于将复杂的、非线性的思维网络通过有组织的句子结构(树状句法)转化为线性的文字序列。好的写作应该能够让读者跟随作者的思路,就像在对话中一样,而不是单向的线性信息传递。
语音类|Voice-first:人与人之间最自然的交流方式,自然也应当是人与机器最顺畅的交互方式。然而,目前还未出现以语音为第一入口的头部产品。
图片类|Picture-first:视觉性的图片内容本身也可以作为一种语言,比如我们使用相册作为生活的记录大过于写文字日记,比如有时候我们仅仅需要一张图片来搜索相应的内容。代表产品:手机相册、图片搜索、Instagram|Snapchat|小红书、Canva。
视频类|Video-first:信息最丰富也是内容传递效率最高的模态,代表产品:TikTok、Youtube。
每个人都有一个侧重的感官语言,对应着不同的表达和思维方式。我也是慢慢发现自己是一个听觉更敏感的人,相比图像,我更喜欢用“听”去认识事物,比如喜欢与人对话,喜欢听街头的叫卖声、咖啡店人们的谈话声来认识一座城市。后面逐渐喜欢上收集声音,记录与好友难忘的对话,以及属于城市或者自然的声音。

用声音记录
与我而言,声音更真实、温和,真实是因为它能够传递文字之外的情感、节奏等信息,而声音温和指的是相比“看”,听不依赖屏幕,如果是记录一个“决定性瞬间”,“录音”这一动作不会产生“摄影”这一行为带给被记录主体的“侵入性”(“侵入性”来自苏珊·桑塔格的《论摄影》)。
音乐、图像、文字、代码各成一门独立的语言。
代码是人类创造的计算机语言,用以进行“人-机”交流,让机器建构人类之所想。
音乐本身即是一种独立的语言,它不依赖于特定的自然语言。在音乐中闭上眼,我们仿佛悬停在一个时间以外的地方,获得一种跨越时间和空间的无限性与沉浸感。
还有很有趣的一点是,一个产品的第一信息形态也决定了一个公司的思维模式,相对于同一种思维方式的人聚集在一起创造一个产品。
“你正在构建的产品类型影响着你的思维方式”
Canva 的 CPO Cameron 之前在一次播客中说过,在 Canva 大家更倾向于用视觉交流,比如喜欢准备宣传资料、社交媒体帖子、视频、写着 logo 的 T 恤等等。而 Spotify 作为全球头部的流媒体音乐平台,是典型以听觉为导向的产品。人们会通过开会这种基于对话的方式来讨论新产品的功能,每个人都在思考音乐、声音、播客。
对话、而不是文字,
才是人类之间最早的交流方式。
文字是人与人交流的语言,然而其实在文字发明以前,人们就已经开始使用口语来进行日常对话。语音,而不是文字,是人类最早的交流方式。
在文字被发明以前,人们通过声音进行交流可以被概括为三个阶段:
1. 原始声音信号阶段:人类主要通过自然的声音信号进行交流。大约在 100 万年前,远古人类已经开始使用声音来传递简单的信息和表达情感。这些声音可能包括叫声、吼叫、拍打等,类似于现在一些动物的交流方式。
2. 口头语言阶段:随着人类大脑和声带的进化,逐渐发展出更复杂的口头语言系统。大约在数十万年前,人类开始使用有组织的语音来进行交流。这一阶段标志着从简单的声音信号向有结构的语言过渡。口头语言成为人类最基本的交流方式,能够传递更复杂和抽象的信息。
3. 早期符号和图画阶段:这个阶段可以追溯到大约 8000 年前,也被一些语言学家称之为前文字阶段。在文字发明之前,人类开始使用简单的符号和图画来辅助口头语言。这些符号和图画可能被刻在石头、骨头或绘制在洞穴墙壁上,用于记录和传递信息。
然而,文字最早出现是作为一种记录工具被发明出来。目前发现最早的文字记载是 5400 年前两河流域苏美尔人在泥板上写下的财务账本,来记忆数字,解决真实的记账需求。
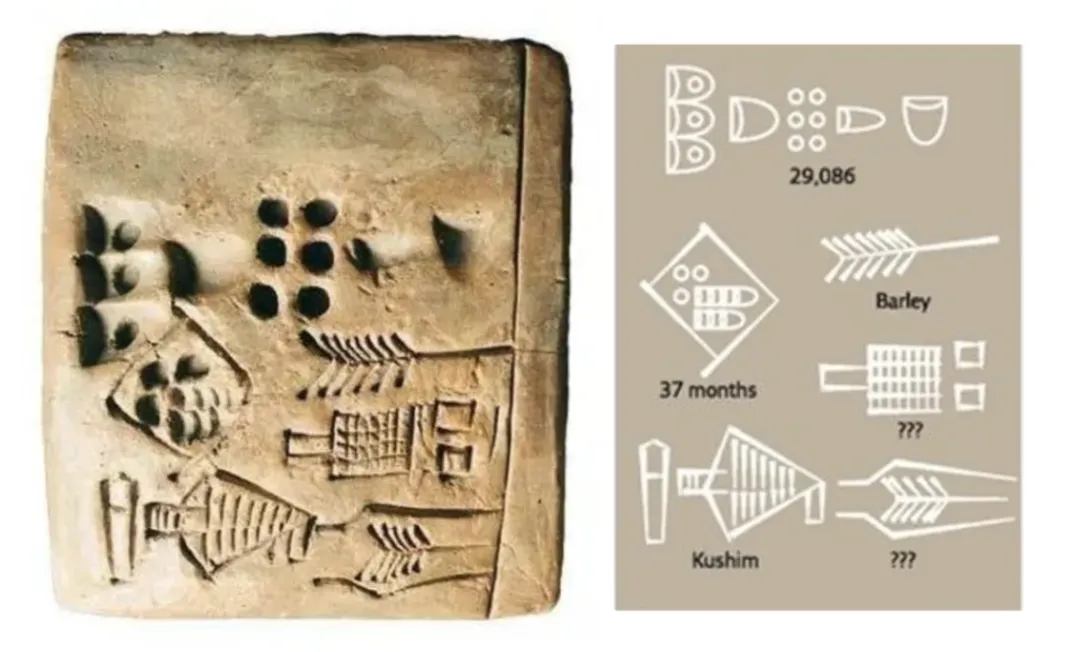
库辛石板:最早的文字记载
一直到公元前 3500 年,在美索不达米亚的乌鲁克文化时期出现了楔形文字的雏形,那是最早出现的基于图画的文字形态。随后文字发展出现了象形文字(古埃及文字、甲骨文)、表意文字(汉字),和表音文字(英语、发育等字母构成的文字系统)。
汉字,是目前唯一仍在使用的表意文字。
语音作为第一输入方式能够让我们与产品的对话,
即“人-机”的交互,
回归到“人-人”之间最自然的交流方式。
Voice is a big thing. 语音产品是我个人认为 AI 在 C 端领域的核心变革点。
去年年底出现的两个语音类产品到如今依旧是自己非常喜欢也经常玩的 AI 产品。
- 语音社交产品 Airchat:语音为人与人唯一的沟通方式, 实现互联网上真正人与人之间的“交流”
- 音乐生成产品 Suno:第一个内容生成领域实现“创作者”和“生产者”在同一个平台的产品
一般在一种创新的技术或者是创新的体验里面,市场是很难计算的,或者说是很难估量的,因为新的体验会带来新的市场的爆发。
相比于文字,对话式语音作为一种产品的内容形态有怎样的特点?有哪些可以适配的产品场景?我将语音类产品总结为以下四个特点:
1. 语音的交互方式自然简单:声音,即对话,是人类之间最早的交流方式。声音作为输入方式能够让我们与产品的对话,即“人-机”的交互,回归到“人-人”之间最自然的交流方式。交互门槛的降低带来的是用户人群的极大拓展。图形界面交互(GUI)是触摸屏手机出现后的人-机交互方式,但如今仍然未被教育完全,比如如今依旧有许多不会“玩手机”,只会打电话、在微信发语音消息和上划快手短视频的老年人。
→ 日常生活、简单场景
2. 语音交互不依赖屏幕,天然适配多任务场景,提高了产品的使用上限:用户可以在开车、做家务等手部不便的情况下使用语音交互。一个人使用手机观看屏幕的时间是有限的,而人们“听”和“说”解放了用户的眼睛,提高了产品使用的时间上限。
→ 娱乐、效率工具
3. 语音有更高的信息传递效率:语音的信息传递速度通常快于打字,同时口语表达是最原始的交流和指令传达方式。但要注意的是,并非所有任务场景都适合语音输入,下文我会根据场景的不同而具体分析。
→ 沟通,效率工具
4. 语音有更丰富的信息,包括更真实的情感:相比文字,语音可以通过识别语调、语速、音量等传递说话者的情感和语境信息。产品也可通过输出更具情感的语音而增加用户的产品体验。这也是纳瓦尔做 Airchat 的初衷,让语音成为人与人之间唯一的交流方式而获得在互联网上和人真正交流的真实感。
→ 社交、健康
由此进一步推演语音类产品的形态,可能会出现以下两个产品趋势:
新的内容创作新的媒介,硬件可以成为新的媒介。
语音的流式交互同时意味着需要对应的硬件进行承载。目前手机屏幕承载的信息因为屏幕尺寸的限制而受限,同时语音这种实时对话的流式信息模态在相同时间内产生的信息则更多,长期可关注 AR、VR 、眼镜等借助大屏幕来实现信息传递的硬件产品。

Curio:让宠物玩具走进你的生活
另一方面,手机之外的硬件产品似乎天然适配语音交互,比如毛绒玩具和汽车两种场景。马斯克前女友创办的 Curio 是最近备受欢迎的一系列宠物+AI 产品之一,通过把模型搭载在玩具之上而让 toys come to life。在车辆驾驶过程中,驾驶员和乘客也可以轻松使用语音交互来调控汽车各项设置、播放音乐、查询导航信息等等。因此,语音交互让用户不依赖于手机屏幕而与产品互动,从而扩展了用户使用产品的物理媒介。
语音交互,或许不仅仅是音频
视频对比文字和音频,毫无疑问是信息传递效率最高的信息媒介。人们在看完视频后会记得 70% 的信息,而单纯看图片记忆的信息之后 30%,在听完一段音频后会记得 20% 的信息。语音交互或许并不意味着内容模态一定为音频,视频同样可以做为信息模态,通过音频可视化的方式辅助呈现音频内容,以提高信息传播效率。

视频到底是最高效的信息传递模态
两个技术基础和三个市场趋势:
1. 目前人-机对话能够实现人与人的正常对话速度,即延迟降低到 500ms 左右。现阶段大多实时语音对话技术通过 STT→LLM→TTS 三个部分实现,延迟可以降低到 500ms 左右,而人与人之间对话的正常时间间隔在 500ms~1s 之间。
2. 端到端 S2S 模型发展:OpenAI 公布但尚未完全开放的 GPT-4o 语音模型采用语音输入→语音输出的端到端架构,近一步降低了对话延迟。
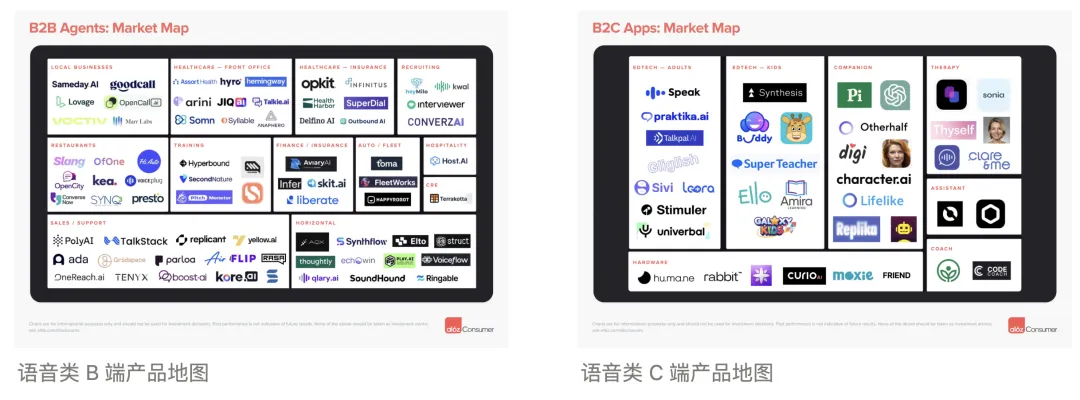
3. 从市场的表现看,以 AI call center 为主的 B 端产品最近逐渐宣布完成新一轮融资,如 Bland.ai 自称作为最快的语音交流产品这周宣布完成 1600 万美元 A 轮融资。Voice AI Agent 也是 A16z 重点关注的 AI 应用方向,之前的一篇报告专门 mapping 了 Voice AI 目前在 B 端 和 C 端的应用场景和发展机会。
同时,LLM 能够很好地处理多语言翻译场景,跨语言实时对话不再是问题。
不论是 B 端的客服、销售等场景,还是 C 端的疗愈、教练、陪伴场景,语音这种交互方式的拓展会为产品带来更广的扩展空间。
最近看到的语音方向的几个市场信号:
1. 做 AI call centor 的 Bland.ai 今天宣布完成了2200万美金A轮融资,YC、Paypal 和 Twillo 创始人、11labs CTO参与投资。
2. 最喜欢的 Suno 也成为了 a16z 公布的近半年增长最快的 ai 产品。在过去六个月中,从第 36 位增长至第 5 位。
3. Superwhisper 是最近看到最喜欢的一个产品,Voice to text for any tasks,通过语音输入进行转写来嵌入到各种桌面和手机端流程。
4. Apple Intelligence 和 Gemini Live 发布,他们会让 40 亿人和“Siri”语音聊天。
Now is the time to reinvent the phone call,现在是时候重塑传统的电话体验了。
LUI 指以自然语言交互界面,应用程序的界面以对话的形式展开。GUI 为图形交互界面,应用程序通过预先定义需要的信息,更结构化、规则话化的让用户选择或输入完成此任务需要的信息。
LUI 具有的特征:结果导向:对话的方式用户可以直接说出他们希望达成的目标,更直观直接。
优势:
1. 更自然:符合人与人之间本身的交流习惯
2. 更懂用户:可以从和用户的对话中抽取用户的相关信息,作为“资产”被存储下来,形成对用户的理解和认知
劣势:
1. 交流是线性的,不利于特定场景的任务完成
GUI 具有的特点:过程导向,需要将目标拆解成多部步骤
优势
1. 具有较为清晰的能力边界,每一个组件是在完成什么操作。
2. 产品流程更加直接、高效。并非所有场景中 LUI 的方式都是高效的。如果完成一件事情的、有太多的选择、有太多分岔的流程,那么 GUI 的交互方式是更高效的。比如推荐一下周边的餐馆,共有 7 个选择,通过语音逐个读出的效率是很低的,都很麻烦,反倒不如一起呈现在屏幕上,用户只需界面点击一下其中之一便可选中某个目标。
劣势
对于部分任务,会拆解为多部步骤,流程较长。
那么,如何判断产品场景来判断应当采用什么界面形式?
并不是所有的产品都适合采用 LUI 的交互方式,参考 Google 做语音助手的经验,我根据 LUI 和 GUI 的特点将判断方式总结为以下 5 个自测问题:
1. 目前用户解决这个问题的方式是怎样的,是否本身就是对话交流的输入方式?
2. 用户是否必须多次点击才能完成 带有屏幕的任务?
3. 用户是否可以在多任务处理时执行此任务?
4. 用户是否可以比较自在轻松地说出此相关的内容?
具体判别依据和对应的适配场景见下表:

举两个例子:
“问一下飞往苏黎世的航班价格是多少?”
适合交互方式:对话,因为它使用起来直观,节省了用户的时间和精力,允许用户进行多任务处理,并且可能在用户可以自由发言的环境中完成。
满足的判断条件:
✅用户已经有了人与人之间的对话关于此任务或主题。
用户已经有了一个与旅行社讨论航班费用的心智模型。
✅互动是简短的,只有最小的来回对话。
用户已经熟悉必要的信息(出发地、目的地、日期、航空公司等),并且可以在几个回合内提供这些最重要的信息。
✅用户必须多次点击才能完成带有屏幕的任务。
用户必须 1) 解锁手机 2) 访问搜索应用程序、小部件或浏览器,以及 3) 输入有关起源、目的地、日期等的所有详细信息,4) 浏览结果。
✅用户可以在多任务处理时执行此任务。
不需要用户的全神贯注。
✅用户可以在手或眼睛忙时进行操作。
用户可以免眼或免提完成此任务。
✅用户在谈论或输入有关此内容时感到很自在主题。航班费用不属于敏感个人信息。用户很可能正在与家人、朋友或同事协调旅行,因此,如果有人无意中听到对话也没关系
未满足的判断条件
◉用户可能需要浏览多个应用,或者 小部件以通过屏幕完成任务。
◉用户可以在单个航班聚合器网站或应用程序上执行此任务。
◉该功能很难找到或很麻烦。用户可以从简单的 Google 搜索开始。他们不太可能需要努力工作才能找到应用程序或网站来开始使用
“为我的家人购买访问苏黎世的门票”
适合交互方式:图形,对话使用起来并不直观,不会节省用户的时间和精力,并且不允许用户进行多任务处理。
满足的判断条件:
✅用户必须多次点击才能完成带有屏幕的任务。
用户必须 1) 解锁手机才能 2) 访问搜索应用程序、小部件或浏览器,以及 3) 输入有关出发地、目的地、日期等的所有详细信息,4) 浏览结果,5) 选择航班,6) 输入个人信息,7) 输入付款信息,8) 完成交易。
✅用户可能需要浏览多个应用,或者小部件以通过屏幕完成任务。用户必须使用特定航空公司的网站进行预订,并且他们可能会使用一些比价平台来比较选项
未满足的判断条件
◉用户已经有了人与人之间的对话关于此任务或主题。在目前的购买流程中,用户通常会在手机端输入或输入购买航班所需的个人信息。
◉互动是简短的,只有最小的来回对话。用户必须提供几种不同类型的信息,这些信息可能并非都易于访问,例如护照或其他身份证明、付款详细信息等。
◉该功能很难找到或很麻烦。用户可以从简单的 Google 搜索开始,或者直接访问他们喜欢的航空公司的网站。他们不太可能需要努力才能找到应用程序或网站来开始使用。
◉用户可以在多任务处理时执行此任务。购买门票这件事需要用户的全神贯注,因为单项任务价值高。
◉完成这件事必须占用用户的手和眼,因为用户可能需要找到必要的信息(例如,护照、信用卡)并输入。
◉用户并不会在公开场合说出这种个人信息。用户正在输入的是相对私人的信息,不会很方便地说出来,比如他们的姓名、出生日期、护照或其他身份证明、信用卡等。对于这种需要个人信息的事情,采用口语输入的场景是非常受限的。
就像 a16z 所说,不论是 B 端还是 C 端,语音都会给 AI 应用带来全新的机会和想象。从目前的融资动态和产品发展来看,“语音”或者“Voice-first”已经成为一个正在被资本市场和用户接受的方式浮出水面,包括但不限于 B 端的客服、销售领域,和 C 端的疗愈、Coach、陪伴等领域。
文章来自于“Founder Park”,作者“la Vela”。




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
