# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
传统的歌声任务,如歌声合成,大多是在利用输入的歌词和乐谱生成高质量的歌声。随着深度学习的发展,人们希望实现可控和能个性化定制的歌声生成。
因此,技巧可控的歌声合成、技巧识别、歌声风格迁移以及语音到歌声的转换等任务应运而生。这些任务逐步发展并在短视频配音和专业音乐创作等现实场景得到应用。
然而,由于缺乏高质量和多任务的开源歌声数据集,这些新兴的歌声任务的发展受到了很大阻碍。
为此,来自浙江大学的研究团队提出了一个全球化、多技巧的大型开源高质量歌声数据集 GTSinger,带有技巧对照组、真实乐谱、配对朗读数据,涵盖了目前所有歌声任务的需求,并在多个歌声任务上提供基准测试。

目前,该论文已被 NeurIPS 2024 Datasets and Benchmarks Track 接收为 Spotlight,并已开源完整数据集和相关代码。
由于录制歌曲和人工标注成本高昂,高质量和多任务的歌声数据集的收集难度很大,这是阻碍 AI 音乐生成任务的的主要瓶颈。
而现有开源歌声数据集的局限性主要包括:
1. 歌声录制和人工标注的质量较低,可能导致模型学习到的歌声跑调或带有噪音。
2. 语言和歌手的多样性有限,限制了模型对多样的音色和风格的学习。
3. 缺乏对多种歌唱技巧(如假声)的对照组和标注,阻碍了模型对技巧的建模和控制。
4. 不配备真实乐谱,因此无法将模型直接应用在实际音乐创作中。
5. 任务适用性较差,缺乏很多新兴的歌声任务需要的标注和配对朗读数据。
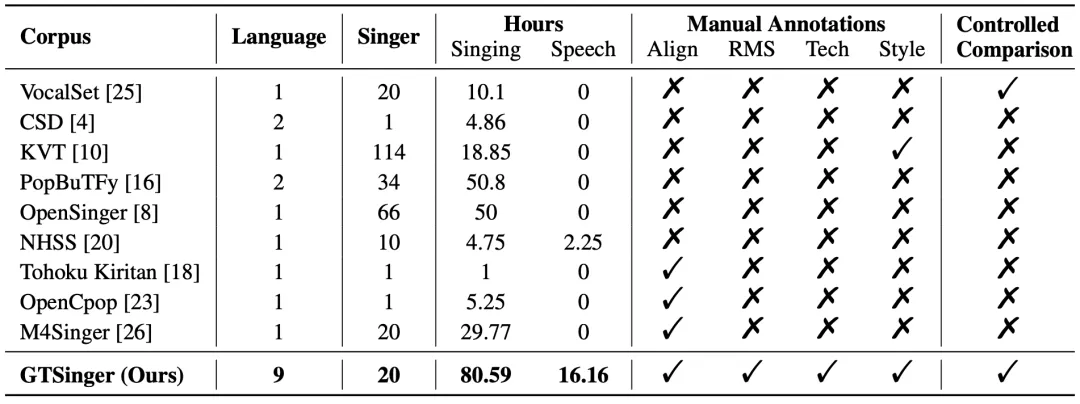
图 1:现有开源歌唱数据集的信息表。Speech 表示配对朗读数据。Align 和 RMS 分别表示人工音素对齐和真实乐谱。Style 表示全局风格标签。
为了解决这些挑战,浙大的研究者们提出了 GTSinger,一个全球化、多技巧的大型开源高质量歌声数据集,包含技巧对照组、真实乐谱、配对朗读数据,涵盖了目前所有的歌声任务的需求。
比起现有开源歌声数据集,GTSinger 主要有以下优势:
1. 专业歌手在专业录音棚中录制了 80.59 小时的歌声,使得 GTSinger 成为目前最大的录制歌声数据集;
2. 20 位专业歌手总共使用了九种世界常用的语言(汉语、英语、日语、韩语、俄语、西班牙语、法语、德语和意大利语),为 GTSinger 带来丰富的风格多样性;
3. GTSinger 为六种常用歌唱技巧(混声、假声、气声、咽音、颤音和滑音)提供了对照组和音素级的技巧标注;
4. 不同于 MIDI 等精细乐谱,GTSinger 提供了可以用于实际音乐创作的真实乐谱;
5. 人工音素对齐、全局风格标签(唱法、情感、音高范围和速度)以及 16.16 小时的配对朗读数据,让 GTSinger 可以适配各种歌声任务。
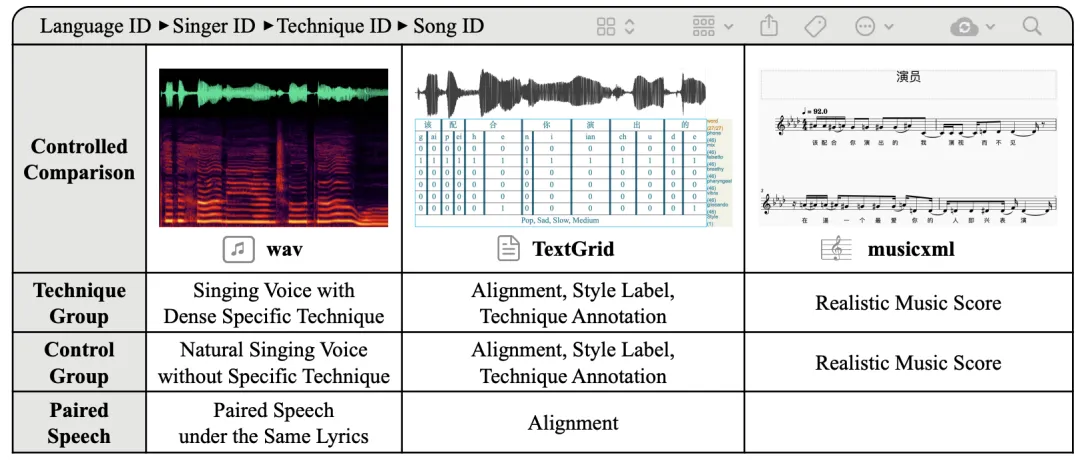
图 2:GTSinger 中每首歌曲的构成。包括技巧组歌声、控制组歌声、配对朗读的音频和标注。
GTSinger 的收集主要包括三个流程:音频录制,人工标注,后续处理。
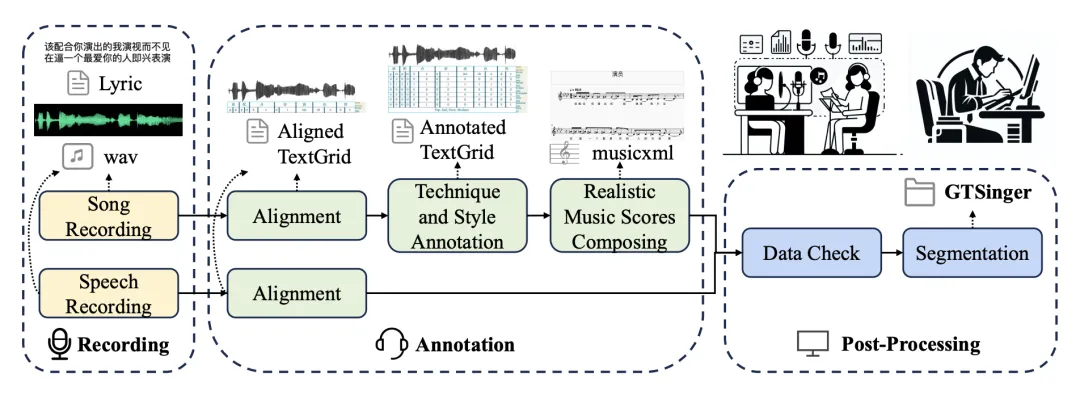
图 3:GTSinger 的数据处理流程。在每一步中都存在人工检查。
在音频录制阶段,音乐专家首先从语言自然度、歌声演唱水平、歌声技巧熟练度等维度严格筛选歌手;接着,专家根据各语言的代表性,技巧的适用度,歌手的音域等因素挑选不同风格和不同情感的歌曲。
之后,歌手在专业录音棚中录制高质量的歌声。在技巧组中,歌手被要求密集使用特定技巧,而对照组则是排除特定技巧的自然演唱。
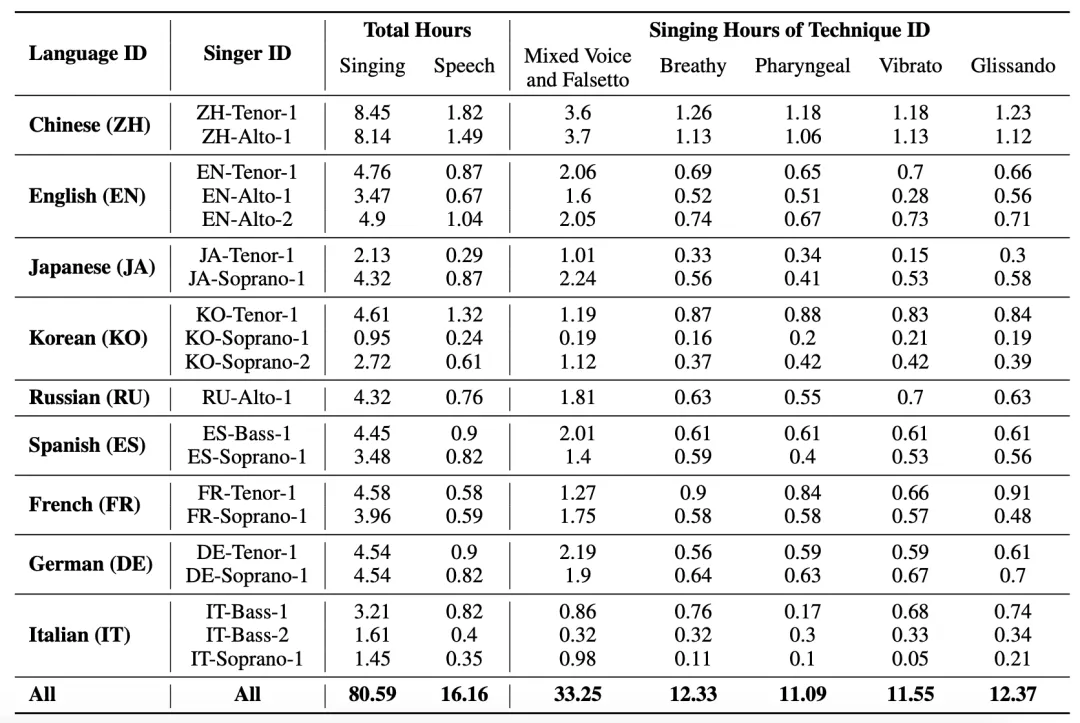
图 4:语言、歌手、技巧和时长的信息表。技巧的时长包括控制组和技巧组中的时长。
人工标注流程主要包括对齐,技巧和风格标注,以及真实乐谱编写。
在对齐阶段,音乐专家首先使用 MFA 完成粗标注,再利用 Praat 来进行对音素边界,错字漏字,无声区域(呼吸或静默)的校对和标注。
对齐完成后,另一组专家根据听感对混声、假声、气声、咽音、颤音和滑音六种技巧进行音素级标注。此外,专家们还为每首歌标记了全局风格标签,包括唱法(流行或美声)、情感(快乐或悲伤)、节奏(慢、中、快)和音高范围(低、中、高)。
接着,为了编写真实乐谱,研究者首先使用 RMVPE 来提取每首歌的 F0,随后使用 ROSVOT 推导出 MIDI 形式的精细乐谱。接着,音乐专家根据录制歌声,并参考原始伴奏进行以下步骤:
1. 确定实际的节奏、谱号和调性;
2. 调整乐谱以匹配真实音符的音高;
3. 根据真实乐谱的规则修改音符时长;
4. 标注音符类型,如休止符、歌词或连音符。
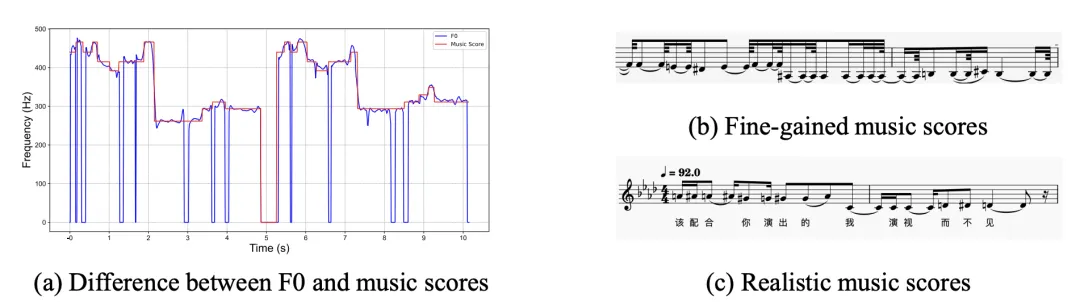
图 5:F0、精细乐谱与真实乐谱之间的对比。精细乐谱会破坏音符时长的规律性,导致音符碎片化,不适合用于实际作曲。
在后续处理中,多个擅长特定语言的音乐专家对标注进行了审核。最后,歌声音频被按语义和无声区域等因素分割为更小的片段,其中超过 95% 的句子时长在 5 到 20 秒之间。
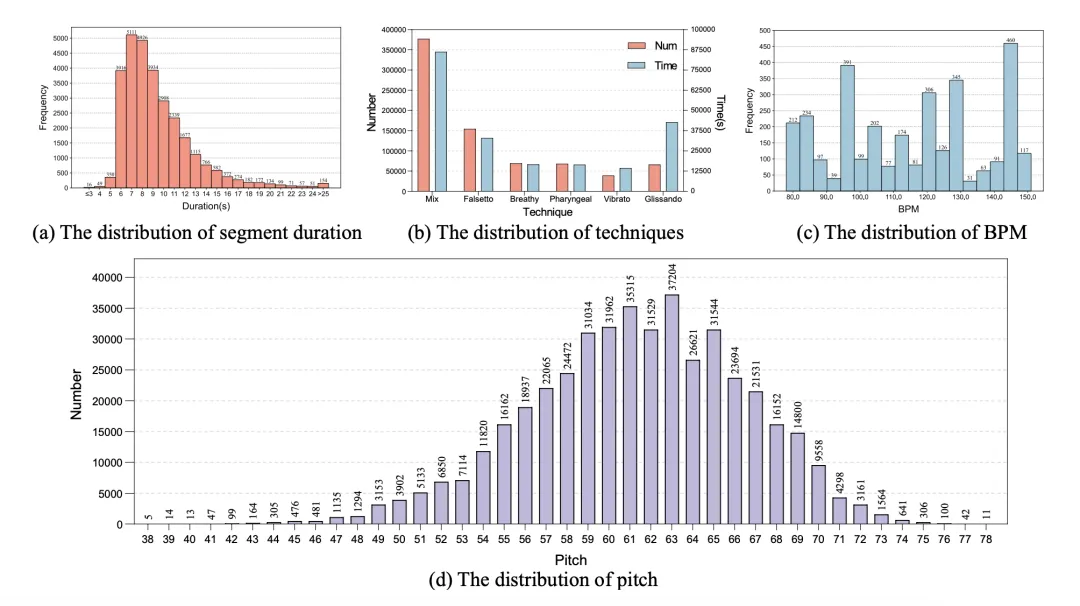
图 6:切句时长、技巧、每分钟节拍数和音符音高的统计。
为了评估数据集质量和任务适用性,GTSinger 在四个歌声任务上进行了全面评估:技巧可控的歌声合成、技巧识别、歌声风格迁移以及语音到歌声的转换。
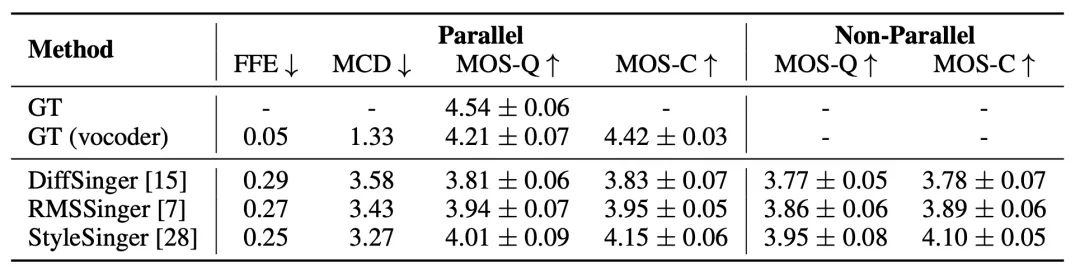
图 7:技巧可控的歌声合成的平行和非平行实验结果。平行实验使用真实技巧序列作为目标。在非平行实验中,六种技巧会随机且适当地分配给每个目标音素。
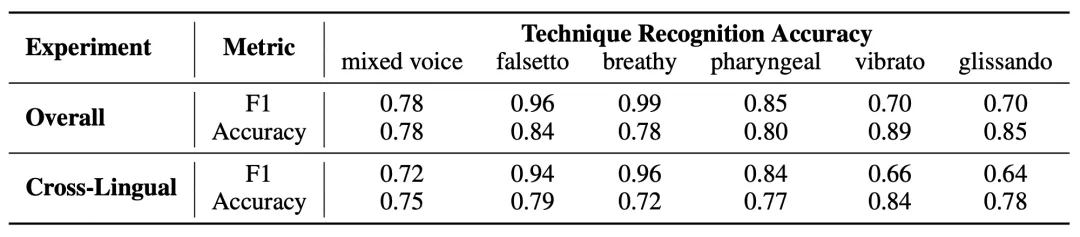
图 8:技巧检测的总体和跨语言实验结果。语言被分类为亚洲语种和欧洲语种,跨语言实验中模型在其中一类语种训练并在另外一类测试。
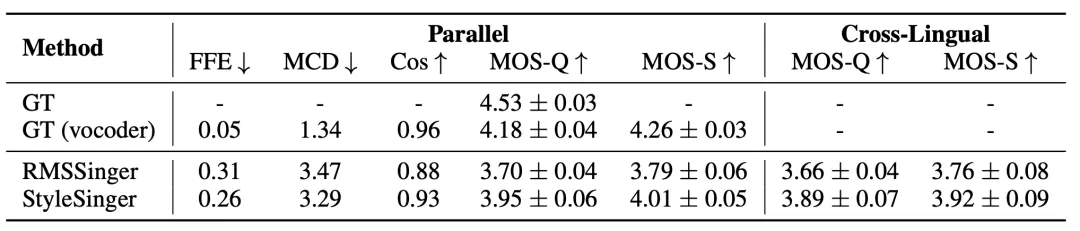
图 9:风格迁移的平行和跨语言实验结果。
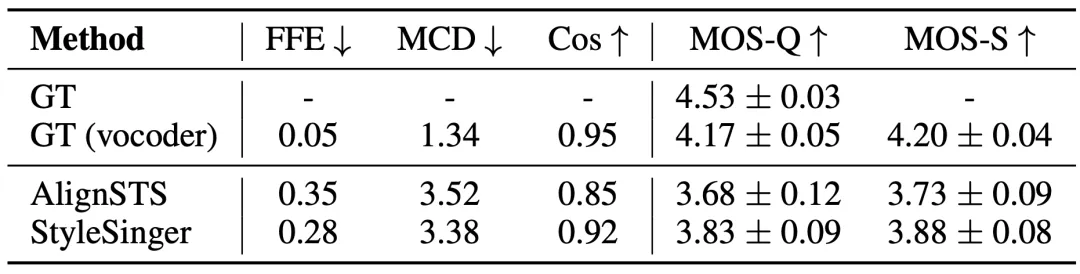
图 10:语音到歌声转换的实验结果。
根据这些实验结果,可以看出 GTSinger 不仅能在广泛的生成任务上应用,也适用于检测任务。
本文提出了 GTSinger,一个全球化、多技巧的大型开源高质量歌声数据集,带有技巧对照组、真实乐谱、配对朗读数据,涵盖了目前所有歌声任务的需求,并在多个任务上提供了基准测试。
未来工作可以进一步扩展数据的多样性,如涵盖阿拉伯语等常用语言以及气泡音等技巧。同时研发基于字级别的模型可能会减少人工标注引入的一些细微错误的影响。最后,制作有伴奏的录制歌声数据集会对音乐领域有更大的帮助。
Demo 1
控制组:

混声组:

假声组:

朗读:

Demo 2
控制组:

气声组:

朗读:

文章来自于“机器之心”,作者“张彧、潘昶皓”。




