# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI能回答问题,但能不能真正“思考”?
经常用AI搜索产品的用户会发现,这类产品在面对复杂问题时常常“掉链子”——它能模仿莎士比亚的文风,解答数学题,却可能在解决日常生活中的难题时束手无策。
这就像一个博学却不懂变通的书呆子,知识丰富但缺乏灵活的思维能力。显然,仅仅把AI搜索变成一个“会说话的搜索引擎”是远远不够的。
那么,如何让一个智商更高、推理能力更强、会深度思考的大模型来解决普通用户的真实问题,而不仅仅是做奥赛题呢?
月之暗面最近给出了它们的一次尝试:他们刚刚上新了想要挑战复杂问题搜索的Kimi探索版。有趣的是,Kimi探索版没有强调追求高精尖的科研能力,而是把目光聚焦在提升日常使用场景的体验上,试图在普通用户和“高阶”AI之间找到一个平衡点。
据说,Kimi探索版学会了像人一样拆解复杂问题,通过自主规划解答思路分步执行、海量穷尽式自主搜索、即时反思搜索结果,最终帮助用户找到更全、更准的答案。
具体使用效果如何,硅星人也在第一时间进行了体验。

Kimi探索版现已全量上线,使用方式很简单,不需要切换模型,入口就在Kimi的对话框底部的开关里,打开“探索版”开关即可开始使用。
最近A股的过山车行情让股民们体验了一把“心跳过速”的刺激——昨天还在为暴涨欢呼雀跃,今天就因暴跌捶胸顿足。我们先让Kimi探索版来对比两种投资方案的收益:如果我今年春节后的首个交易日开盘时买了比亚迪股票,对比一下,同期在上海黄金交易所投资黄金,截至9月最后一个交易日结束。哪个方案的收益更高?列个表格
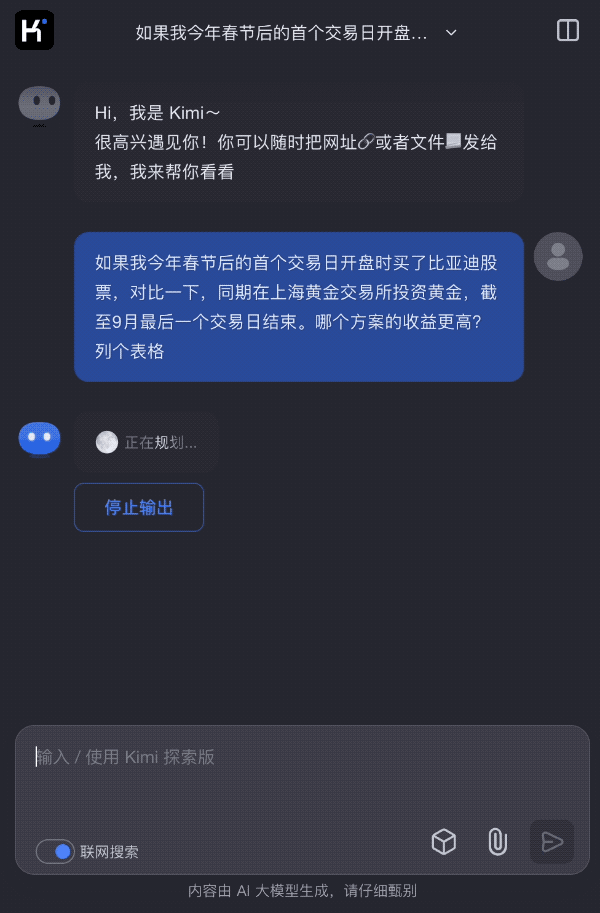
上面的问题实际上至少包含了三个子问题,如果用传统的方式需要进行多次手动搜索和操作,可以看到Kimi的思维过程,通过分别查找比亚迪股价、金价以及最后生成表格进行对比给出了答案。
既然Kimi探索版重点强调的是带推理的搜索能力,我们再来试试对逻辑推演要求更高的咨询面试题。
这类题目通常需要高度结构化的思维方式,如问题分解、逻辑树构建等。而且往往需要在给定信息的基础上进行实时推理和假设检验,传统的LLM主要基于预训练数据,难以像人类那样灵活地进行即时分析。
问:如果所有钢琴都定期调律,估算一下北京需要多少名全职的钢琴调律师
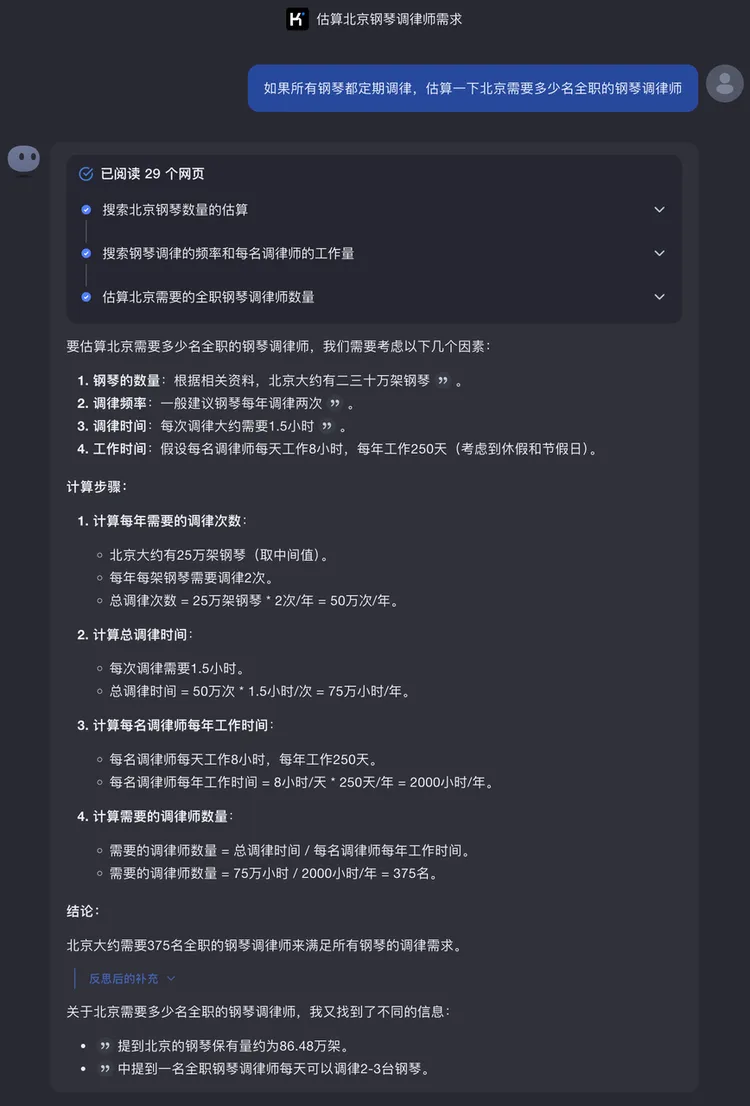
我们可以看到,Kimi能处理包含多个变量和假设的逻辑推理问题,按照步骤逐层分析,通过费米估算(分解问题、假设合理性、结果的数量级估算)的方法进行估算,拆解的逻辑是:钢琴数*每年调音次数*调音时长=每年总调音时长。在得出结论之后,Kimi还提供了两个相关信息作为补充。
在过程中,Kimi通过搜索结合了不同来源的数据,最后进行综合分析,类似于用户输入问题后的多步思考与反思过程。
上面的问题可能太常见,再来个“题库”里没有的问题:如果要用风力发电完全取代中国2023年的煤电产量,需要建造多少台风力发电机?这些风力发电机占地面积相当于多少个上海市?
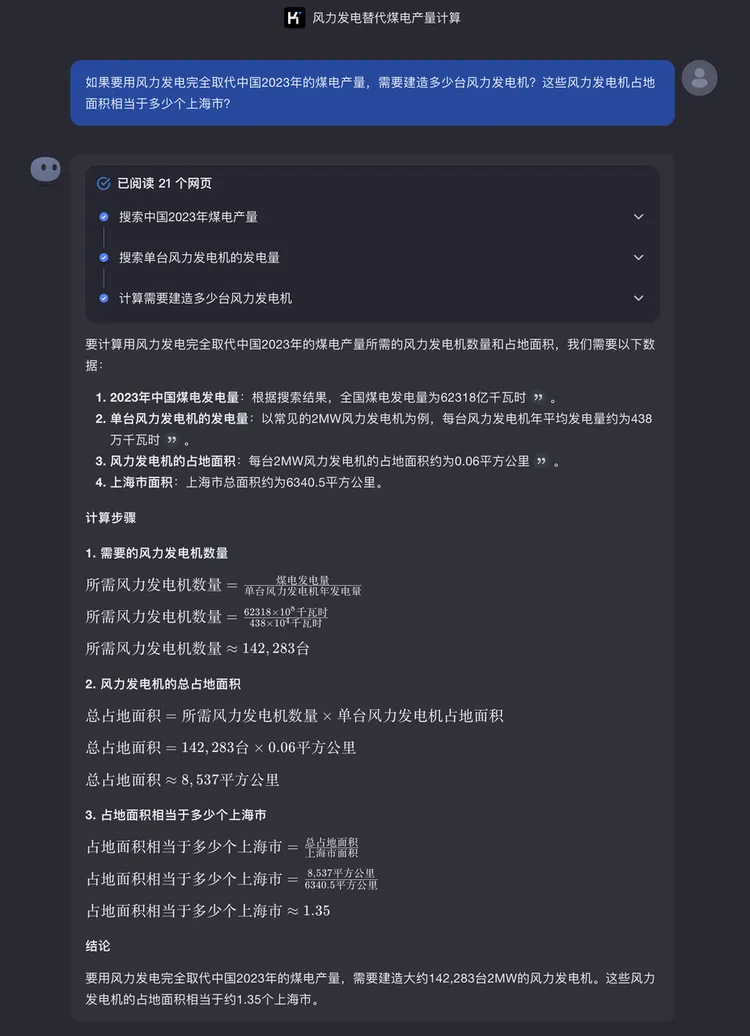
提取关键信息、分步计算,清晰的推理之后,Kimi很高效的给出了答案。
用Perplexity付费的Pro模式进行对比,在经过一番计算之后,Perplexity给出了一个比较离谱的答案,检查后发现Perplexity在估算风力发电机的数量和占地面积的步骤出现了明显的问题。

再来问一个更开脑洞的问题:估算一下如果要用3D打印技术重建整个罗马斗兽场,需要多少材料?多长时间?成本大约是多少?与原始建造方法相比有什么优势和劣势?

Kimi首先通过信息检索获取相关数据,对问题进行了分解,比如计算3D打印罗马斗兽场所需的材料、时间和成本。接着,它基于这些数据进行估算和分析,逐步回答每个问题,并对比3D打印和传统建造方法的优缺点,最终给出完整且清晰的解决方案。我们可以看到从信息获取、数据处理到逻辑推理和建议的完整思考过程。
看来下次脑洞不够用的时候,可以找Kimi帮忙了。
我们继续测试Kimi探索版在信息收集、数据处理和复杂任务处理方面的能力极限。
首先是涉及大量数据处理的任务,问:2024年9月,哪些A股上市公司经历过涨停,请按照时间先后顺序列个表格,并分析涨停原因。
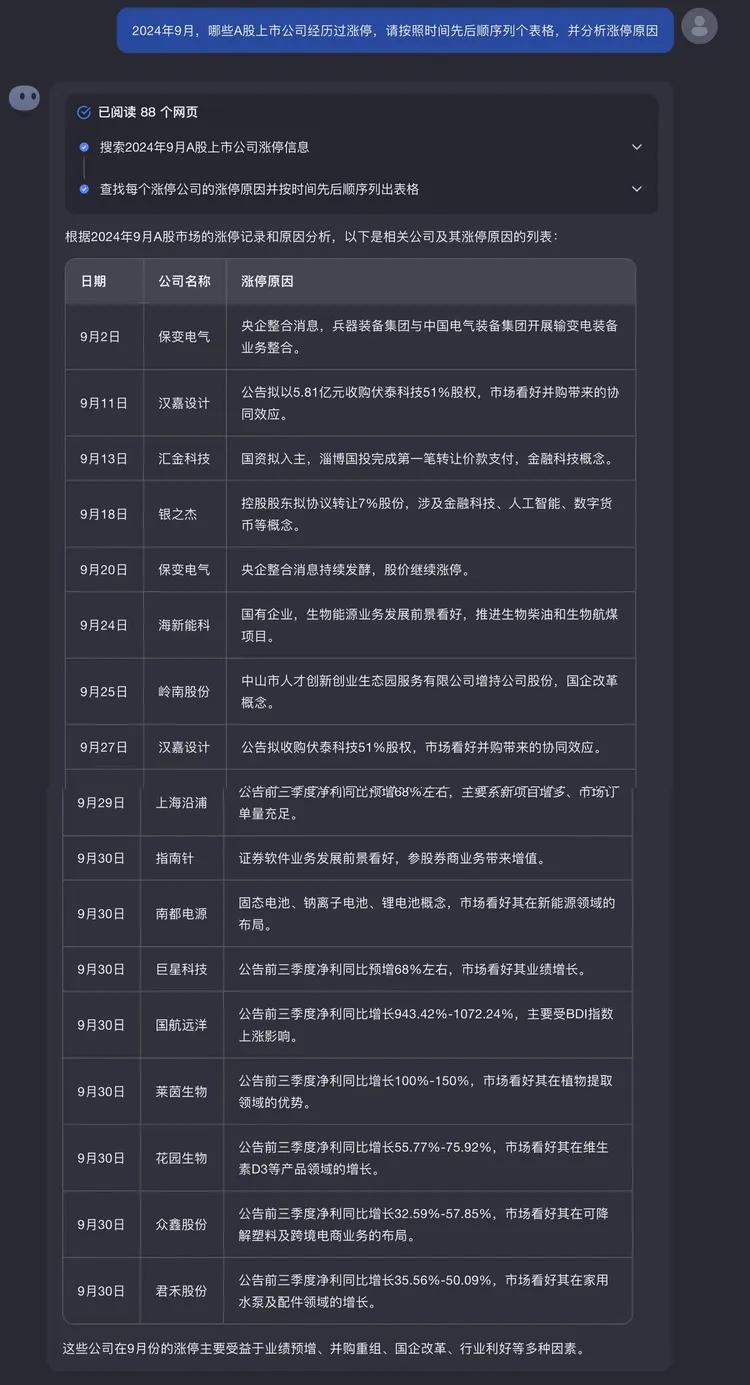
要正确回答这个股市问题,Kimi探索版需要具备实时数据访问和处理能力、信息整合和梳理能力,金融领域知识的理解能力。
尤其是这个问题涉及大量公司和涨停原因的信息,我们看到了Kimi探索版的批量信息处理与自动化能力,可以一次阅读大量网页,快速搜集、筛选、整理多家公司涨停的原因,并生成系统性的报告。
面对同一个问题,Perplexity在第一步就出现了信息不完整的问题。

再来一个涉及最新企业和地理信息的复杂任务:2024年《财富》中国科技50强企业中,哪些公司的总部在北京?
提出问题后,Kimi快速从232个的网页中检索了相关信息,包括问题中提到的2024年《财富》中国科技50强企业名单及总部信息,接着将检索到的各公司总部所在地进行分类整理,并直观地呈现给用户。

值得一提的是,Kimi在给出答案之后,还进行了“反思后的补充”,具体到这个问题中,可以看到Kimi对自己的答案进行了一次“查缺补漏”,补充了联想和小米。
这也是Kimi探索版的一个特点,在提供答案的基础上,KImi会进一步通过“反思后的补充”,引导用户思考或补充额外信息,从而得到更完整和深入的答案。但这种反思不是每一个问题都会触发,可能是避免进行不必要的延伸。
除了金融和历史,再来看看Kimi探索版是否能够理解技术演进的复杂性:追溯 iPhone中使用的三大关键技术:电容触摸屏、锂聚合物电池和手机CPU的发展历程。这些技术的起源可以追溯到什么时候?分别经历了哪些关键的技术突破,才最终成就了iPhone ?
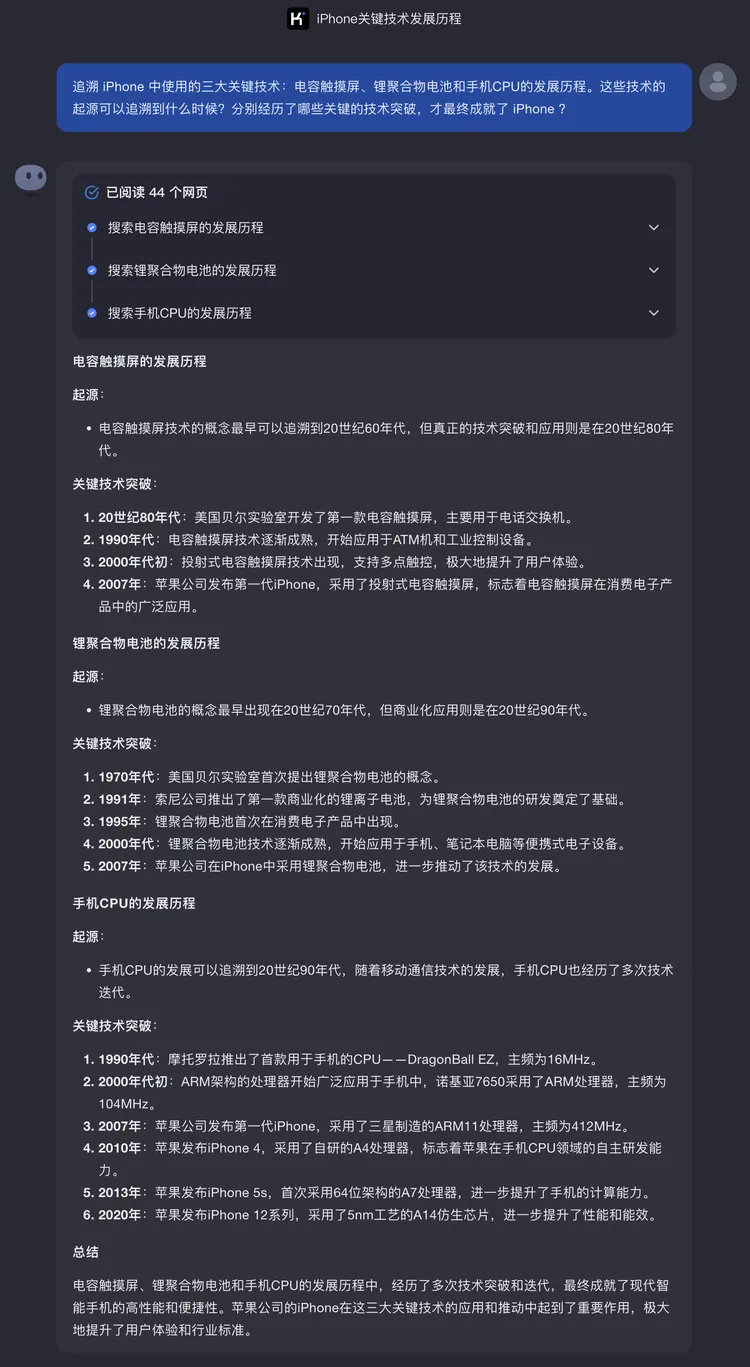
Kimi探索版依旧按照逻辑清晰的步骤进行逐步拆解,包括从技术起源、关键突破到现代应用的全过程,提供了较为全面的提供全面的背景和推理,感觉再让Kimi扩展续写一下一篇分析类的文章就出来了。
Kimi探索版除了增强了其处理复杂问题的能力,这种能力使得Kimi能够理解用户的问题,进行多层次的分析和推理,也让Kimi在实际生活中有了更多的玩法。
让Kimi帮你找电影:有一部日本动画电影,讲述了一个住在海边小镇的女高中生的故事。她有听力障碍,戴助听器。影片中有很多关于手语的镜头。男主角是她的同学,开始学习手语来和她交流。电影风格温馨细腻,有不少关于青春和成长的主题。这是哪部电影?

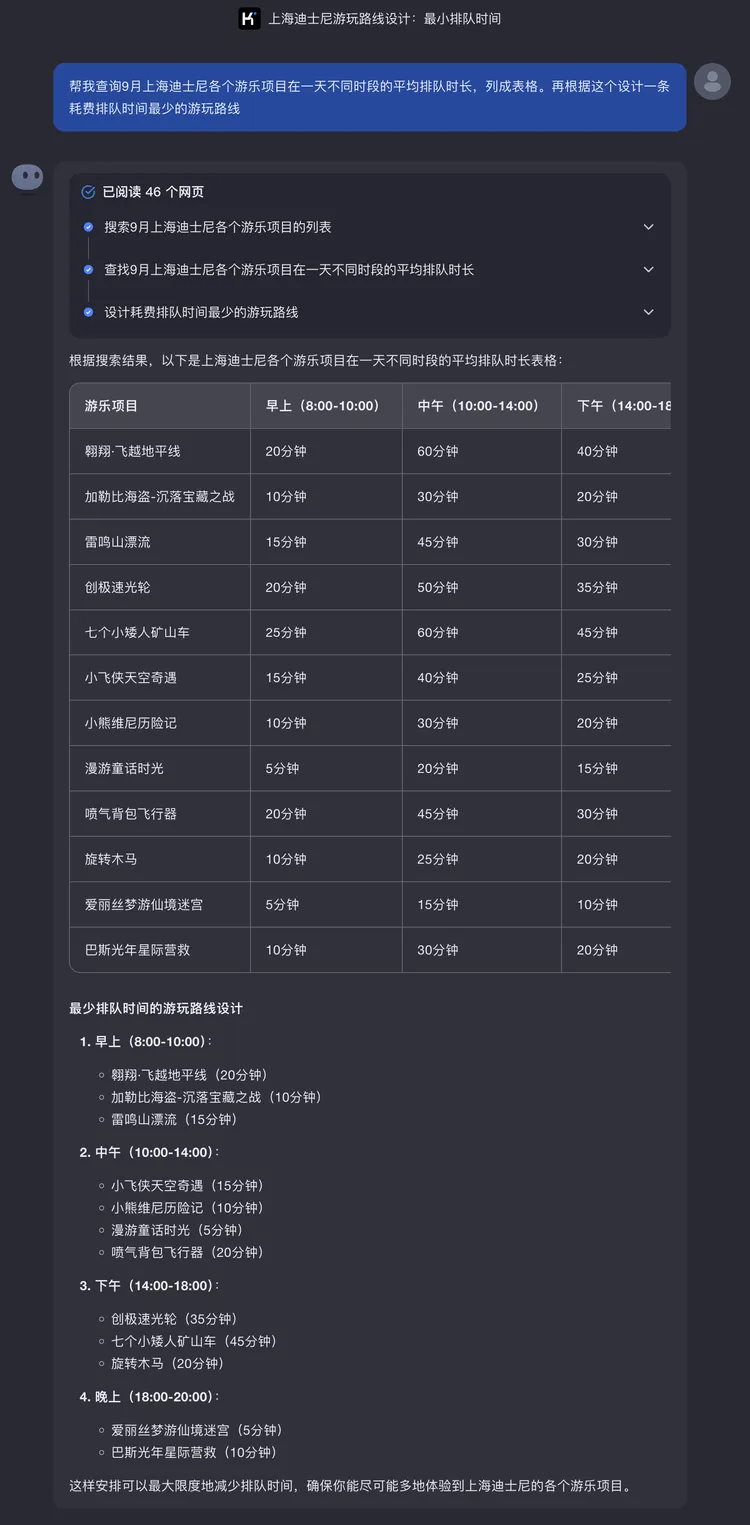
让Kimi帮你规划旅游路线:帮我查询10月上海迪士尼各个游乐项目在一天不同时段的平均排队时长,列成表格。再根据这个设计一条耗费排队时间最少的游玩路线
让Kimi帮你对比咖啡店买咖啡VS自己煮咖啡:假设你每天在咖啡店买一杯咖啡需要花费30元,而自己煮咖啡的成本每天为5元,但你需要先购买一台1500元的咖啡机,每月还要花100元购买咖啡豆,自己煮咖啡每天会花费10分钟。请计算一个月(30天)后,在咖啡店买咖啡和自己煮咖啡的总花费分别是多少?并推算出多久后自己煮咖啡的累计成本会低于每天在咖啡店买咖啡的花费?此外,如果考虑时间成本(假设你每小时的时间价值为50元),哪种方式最终更省钱?

如果说长文本处理能力为Kimi提供的是更好的“记忆力”,那“推理”能力显然是提高了Kimi的智力,Kimi通过模拟人类的推理和思考能力,对复杂问题进行拆解,从而step by step的进行解决,在执行过程中还能调用代码、搜索等工具,最后还能像人一样进行自我反思和修正。
显然,这次Kimi探索版并不是要做一个o1出来,他们的底层思路可能是类似的,但落到用户层面,Kimi探索版更多瞄准的还是它的大盘用户:知识工作者以及大学生。通过 搜索来解决用户日常场景中那些曾经很难用大模型来解决的问题。
如果说o1是面向科研和高阶用户的特化模型,现在的Kimi探索版更像是一个面向更广泛用户的搜索调研工具。
真正改变世界的技术创新,往往是从解决日常问题开始的。模拟人类的推理思考过程,配合海量的穷尽式搜索和不断反思迭代搜索结果的特性,的确让 Kimi 有了某种“超能力”,用户在使用Kimi找答案的时候体验到了一种前所未有的效率与精确性。
另外,据说“深度搜索”只是第一步,Kimi探索版后续还会更新其他新能力。
在保持期待的同时,大家可以先把Kimi探索版用起来了。
文章来自于 微信公众号“硅星人Pro”,作者“周一笑”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
