# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
具有强大泛化能力
本研究所提出的全新去噪蛋白质语言模型 (DePLM) 不仅显著提升了蛋白质优化性能,而且保持了强大的泛化能力。
作为生物功能的主要载体,蛋白质结构和功能在数十亿年的进化中所展示出的多样性,为药物发现和材料科学等领域的进步提供了重要机遇,然而,现有蛋白质的固有特性(如热稳定性)在许多情况下往往无法满足实际需求。因此,研究人员致力于通过优化蛋白质来增强其特性。
传统的深度突变扫描 (DMS) 和定向进化 (DE) 依赖于昂贵的湿实验技术,与之相比,基于机器学习的方法能够快速评估突变效果,对高效的蛋白质优化至关重要。其中,一种应用广泛的研究途径是利用进化信息 (Evolution Information) 来检验突变效果。进化信息可以通过氨基酸在蛋白质序列中某一位置出现的可能性来推断突变效果。为了计算将一种氨基酸突变为另一种的相关概率,主流方法使用训练在数百万蛋白质序列上的蛋白质语言模型 (PLMs),以自监督的方式捕捉进化信息。
然而,现有的方法通常有 2 个关键方面被忽视——首先,现有方法未能去除无关的进化信息,进化是为了满足生存需求而同时优化多个特性,这往往会掩盖目标特性的优化;其次,目前主流的学习目标包含数据集特定的信息,这些信息往往过度拟合于当前的训练数据,限制了模型对新蛋白质的泛化能力。
为了解决这些挑战,浙江大学计算机科学与技术学院、浙江大学国际联合学院、浙江大学杭州国际科创中心陈华钧教授、张强博士等人,共同提出了一种针对蛋白质优化的全新去噪蛋白质语言模型 (DePLM),核心在于将蛋白质语言模型捕捉到的进化信息 EI 视为与特性相关和无关信息的混合体,其中无关信息类似于目标特性的「噪音」,因此需要消除这些「噪音」。大量实验表明,本研究所提出的基于排序的去噪过程显著提高了蛋白质优化性能,并同时保持了强大的泛化能力。
相关成果以「DePLM: Denoising Protein Language Models for Property Optimization」为题,入选了顶会 NeurIPS 24。
研究亮点:
* DePLM 能够有效过滤无关信息,通过优化 PLM 中包含的进化信息来改善蛋白质优化
* 本研究设计了去噪扩散框架中的基于排序的前向过程,将扩散过程扩展到突变可能性的排序空间,同时将学习目标从最小化数值误差转变为最大化排序相关性,促进数据集无关的学习并确保强大的泛化能力
* 大量实验结果表明,DePLM 不仅在突变效应预测方面优于当前最先进的模型,还展现出对新蛋白质的强大泛化能力
ProteinGym 是一个广泛的深度突变筛选 (DMS) 实验集合,包含 217 个数据集。由于 PLM 的长度限制,研究人员排除了包含长度超过 1,024 的野生型蛋白质的数据集,最终保留了 201 个 DMS 数据集。ProteinGym 将 DMS 分类为 5 个粗略类别:66 个用于稳定性,69 个用于适应性,16 个用于表达,12 个用于结合,38 个用于活性。
* 性能比较实验:研究人员采用了随机交叉验证方法,在该方法中,数据集中的每个突变会随机分配到 5 个折叠中的一个,然后通过对这 5 个折叠的结果进行平均来评估模型的性能。
* 泛化能力实验:给定一个测试数据集,研究人员随机选择多达 40 个与其优化目标(例如热稳定性)一致的数据集作为训练数据,需确保训练蛋白质与测试蛋白质之间的序列相似性低于 50%,以避免数据泄漏。
如前文所述,DePLM 的核心在于将蛋白质语言模型 PLM 捕捉到的进化信息 EI 视为与特性相关和无关信息的混合体,其中无关信息类似于目标特性的「噪音」,并消除这些「噪音」。为实现这一目标,研究人员从去噪扩散模型中获得灵感,该模型通过精炼含噪输入以生成期望的输出。
具体而言,研究人员设计了一个基于排序信息的前向过程来扩展扩散模型以去噪进化信息,如下图所示。在下图左侧,DePLM 使用从 PLM 中得出的进化似然 (Evolution Likelihood) 作为输入,并生成针对特定属性的去噪似然 (Denoised Likelihood),用于预测突变的影响;在下图中间和右侧,去噪模块 (Denoising Module) 利用特征编码器 (Feature Encoder) 生成蛋白质的表征,考虑一级和三级结构,这些表征随后通过去噪模块用于过滤似然中的噪声。
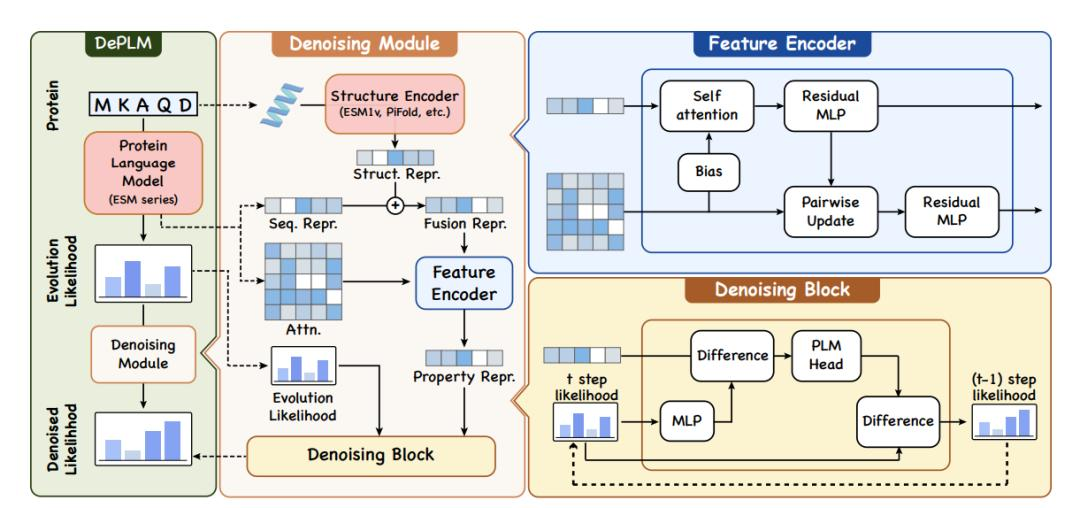
DePLM 架构概览
去噪扩散模型 (Denoising diffusion models) 包含 2 个主要过程:正向的扩散过程和需要学习的反向去噪过程。在正向扩散过程中,少量噪声逐步添加到真实值中;然后,反向去噪过程学习通过逐步消除积累的噪声来恢复真实值。
然而,在将这些模型应用于蛋白质优化中的突变概率进行去噪时,存在 2 个主要挑战——首先,实际特性值与实验测量之间的关系通常表现出非线性,这源于实验方法的多样性,因此,仅依赖于最小化预测值和观测值之间的差异进行去噪,可能会导致模型过拟合到特定数据集,从而降低模型的泛化能力;其次,与传统的去噪扩散模型不同,研究人员要求累积的噪声收敛。
为了解决这些挑战,研究人员提出了基于排序的去噪扩散过程 (a rank-based denoising diffusion process),重点在于最大化排序相关性,如下图所示。在下图左侧,DePLM 的训练涉及 2 个主要步骤:正向加噪过程 (a forward corruption process) 和反向去噪过程 (a learned reverse denoising process)。
在加噪步骤中,研究人员使用排序算法 (sorting algorithm) 生成轨迹,从属性特异性似然 (Property-specific Likelihood) 的排序转变为进化似然 (Evolution Likelihood) 的排序,DePLM 被训练来模拟这一反向过程。在下图右侧,研究人员展示了从进化似然 (Evolution Likelihood) 向属性特异性似然 (Property-specific Likelihood) 转变过程中 Spearman 系数的变化。
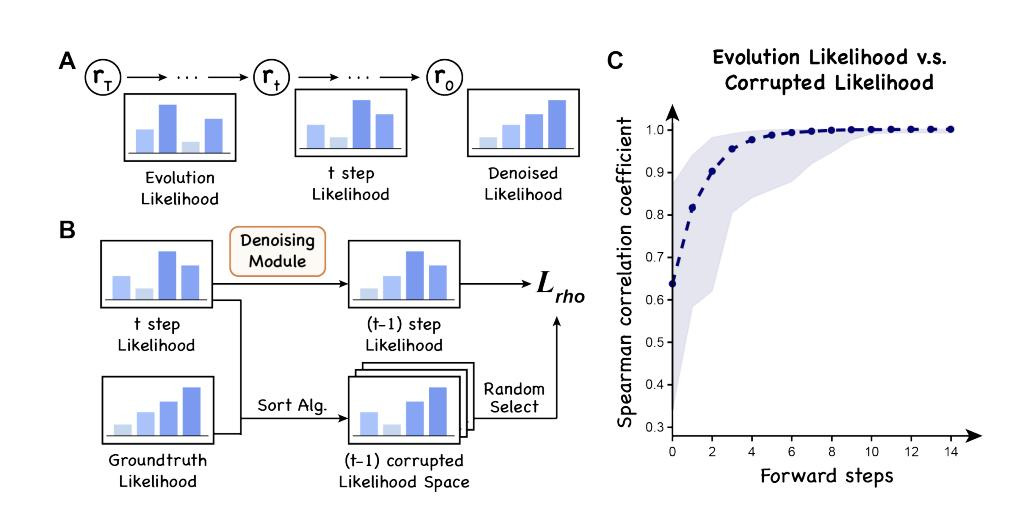
DePLM 的训练过程
最后,为了实现与数据集无关的学习和强大的模型泛化能力,研究人员在特性值的排序空间中进行扩散过程,并将传统的最小化数值误差目标替换为最大化排序相关性。
首先,为了评估 DePLM 在蛋白质工程任务中的性能,研究人员将其与 9 个基准进行了比较,包括 4 个从零开始训练的蛋白质序列编码器 (CNN、ResNet、LSTM 和 Transformer),5 个自监督模型 (OHE、ESM-1v 的微调版本、ESM-MSA、Tranception 以及 ProteinNPT)。
结果如下表所示,最佳结果和次优结果在表中分别用粗体和下划线标出。整体来看,DePLM 的表现优于基线模型,从而确认了将进化信息与实验数据相结合在蛋白质工程任务中的优势。
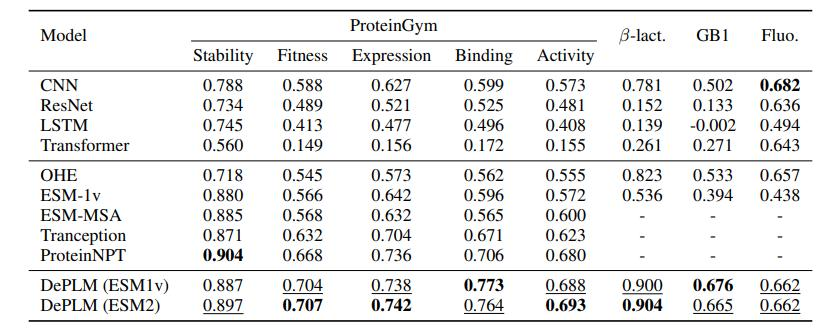
DePLM 与基线模型在蛋白质工程任务中的表现
值得注意的是,ESM-MSA 和 Tranception 由于引入了多序列比对 (MSA),表现出比 ESM-1v 更强的进化信息,通过比较它们的结果,研究人员证明了高质量的进化信息显著改善了微调后的结果。然而,即使在这些改进的情况下,它们的表现仍然未能达到 DePLM 的水平。研究人员还注意到,DePLM 的表现优于 ProteinNPT,强调了所提出的去噪训练过程的有效性。
接着,为了进一步评估 DePLM 的泛化能力,研究人员将其与 4 个自监督基线 (ESM-1v、ESM-2 和 TranceptEVE)、2 个基于结构的基线 (ESM-IF 和 ProteinMPNN) 以及 3 个监督基线 (CNN、ESM-1v 和 ESM-2 的微调版本)进行比较。
结果如下表所示,最佳结果和次优结果在表中分别用粗体和下划线标出,可以观察到,DePLM 始终优于所有基线模型——这进一步展示了仅依赖未过滤进化信息的模型存在不足,其往往由于同时优化多个目标而稀释了目标属性。通过消除无关因素的影响,DePLM 显著提高了性能。
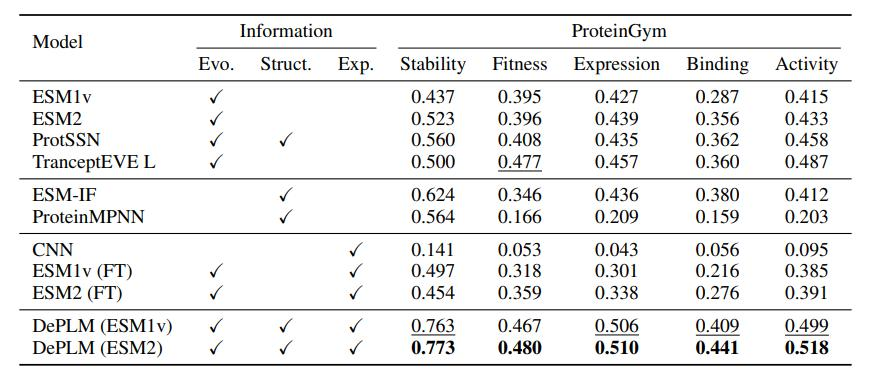
泛化能力评估
此外,为了最小化预测分数与实验分数之间的差异而训练的基线模型 ESM1v (FT) 和 ESM2 (FT) 的表现远远低于 DePLM。这一结果表明,在排序空间中优化模型降低了来自特定数据集的偏差,从而实现了更优的泛化。此外,研究人员还观察到,蛋白质结构信息有助于稳定性和结合性的提升,而进化信息则增强了适应性和活性属性。
总而言之,大量实验结果表明,DePLM 不仅在突变效应预测方面优于当前最先进的模型,还展现出对新蛋白质的强大泛化能力。
蛋白质大语言模型具有准确预测蛋白质结构、功能和相互作用的能力,代表了 AI 技术在生物学中的前沿应用,其通过学习蛋白质序列的模式和结构,能够预测蛋白质的功能和形态,对于新药开发、疾病治疗和基础生物学研究具有重大意义。
面对这一富有前景的新兴领域,浙江大学团队近年来持续深耕,取得了多项创新科研成果。
2023 年 3 月,陈华钧教授、张强博士和其所在的 AI 交叉中心研究团队开发了一种针对蛋白质语言的预训练模型,该模型的相关研究以「 Multi-level Protein Structure Pre-training with Prompt Learning」 为题发表在 2023 年 ICLR 国际机器学习表征会议上。值得一提的是,ICLR 会议是深度学习领域最顶尖的会议之一,由两位图灵奖得主 Yoshua Bengio 和 Yann LeCun 领衔创办。
在这项工作中,研究团队在国际上率先提出了面向蛋白质的提示学习机制,并构建了 PromptProtein 模型,设计了 3 个预训练任务,将蛋白质的第一、三、四级结构信息注入到模型中。为了灵活使用结构信息,受到自然语言处理中的提示技术的启发,研究人员提出了提示符引导下的预训练和微调框架。在蛋白质功能预测任务和蛋白质工程任务上的实验结果表明,成果提出的方法比传统模型具有更好的性能。
时间来到 2024 年,该团队的研究取得了进一步进展。为了解决 PLMs 在理解氨基酸序列方面表现出色,但无法理解人类语言的挑战,浙江大学陈华钧、张强团队提出 InstructProtein 模型,利用知识指令对齐蛋白质语言与人类语言,探索了在蛋白质语言和人类语言间的双向生成能力,有效弥补了两种语言之间的差距,展示了将生物序列整合到大型语言模型的能力。
该研究以「InstructProtein: Aligning Human and Protein Language via Knowledge Instruction」为题,被 ACL 2024 主会录用。大量双向蛋白质-文本生成任务的实验表明,InstructProtein 在性能上优于现有的最先进 LLMs。

论文地址:
https://arxiv.org/abs/2310.03269
实际上,这些文章仅仅还只是团队正在开展工作的一个方面。据报道,在浙江大学 AI 交叉中心研究人员更希望实现的是怎样利用蛋白质或分子语言大模型来驱动像 iBioFoundry 和 iChemFoundry 这样的科学实验机器人,将真实世界的传感器信号、蛋白质、人类语言相结合,建立语言和感知的链接。

未来,该团队期待将自己的研究成果进一步产业化,为新药研发、生命健康领域做更多有价值的探索和支撑。
参考资料:
1.https://neurips.cc/virtual/2024/poster/95517
2.https://hic.zju.edu.cn/2023/0328/c56130a2733579/page.htm
文章来自于“超神经HyperAI”,作者“梅菜”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
