# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
性能不输SOTA模型,计算开销却更低了——
中山大学和360 AI Research联合推出PT-DiT,同参数规模下,计算量仅为DiT的51.4%,Lumina-Next的17.5%。
具体来说,PT-DiT基于Proxy token机制,能用于文生图(Qihoo-T2I)、文生视频(Qihoo-T2V)和文生多视图(Qihoo-T2MV)等多种任务。
(Qihoo-T2X指文本到任意视觉任务)

话不多说,我们直接看几个最终生成效果,文生图be like:

接下来是今年火热的视频生成,prompt如下:
Sunset cityscape with spires, buildings, clouds, warm glow, and trees.(夕阳下的城市景观,有尖塔、建筑物、云朵、温暖的光芒和树木。)

最后是多视图生成,宝剑、小黄鸭等任意素材均可实现转3D效果。

目前该研究已经开放了论文、项目主页和代码仓库,即将开源。
当前,基于Diffusion Transformer的模型(Sora , Vidu, Flux等)能够生成高保真图像或视频,并与文本指令具有强一致性,极大促进了视觉生成的进步。
然而,global self-attention关于序列长度的二次复杂度增加了Diffusion Transformer的计算开销,导致了实际应用时更长的生成时间和更高的训练成本。
这个问题也阻碍了Diffusion Transformer在高质量和长时间视频生成中的应用。
例如,优于2D spatial attention+ 1D temporal attention的3D full attention却由于计算开销的限制而难以进行更高分辨率和更长时间视频生成的探索。
一些视觉理解和识别领域的研究发现,由于视觉信息的稀疏和重复性质,global self-attention具有一定的冗余性。
研究团队通过可视化注意力图发现:
同一窗口内的不同token对于空间上距离较远的token的关注程度是相似的,对于空间上相近的token的关注程度是不同的。
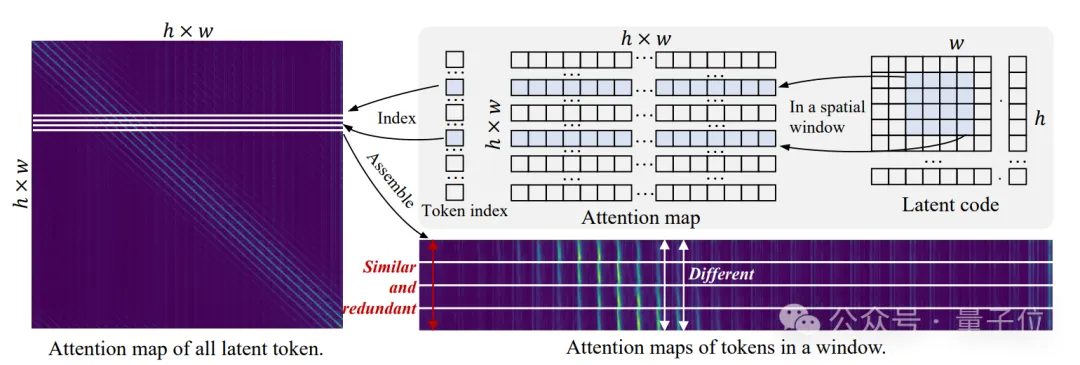
如上图所示,研究团队分析了PixArt-????在分辨率为512x512情况下self-attention中的注意力图。
然后将位于同一个空间窗口token的注意力图组合到一起,如图右侧所示,其中垂直轴表示窗口中的不同token,水平轴表示窗口内token与所有token的关联程度。
很明显,同一窗口内不同token的注意力对于空间上距离较远的token几乎是一致的,即在相同的水平位置,垂直值几乎相同;而空间相邻的token表现出不同的关注。
这表明计算所有token的注意力是冗余的,而对计算空间相邻token的注意力至关重要。
所以,研究团队提出了一种基于proxy token的稀疏注意力策略,从每个窗口采样有限的proxy token来执行自注意力,从而减少冗余并降低复杂性。
如下图所示,研究团队提出的PT-DiT引入了proxy token来减少计算global self-attention所涉及的token数量,高效地建立全局视觉信息的关联。
PT-DiT包含的两个核心模块是:
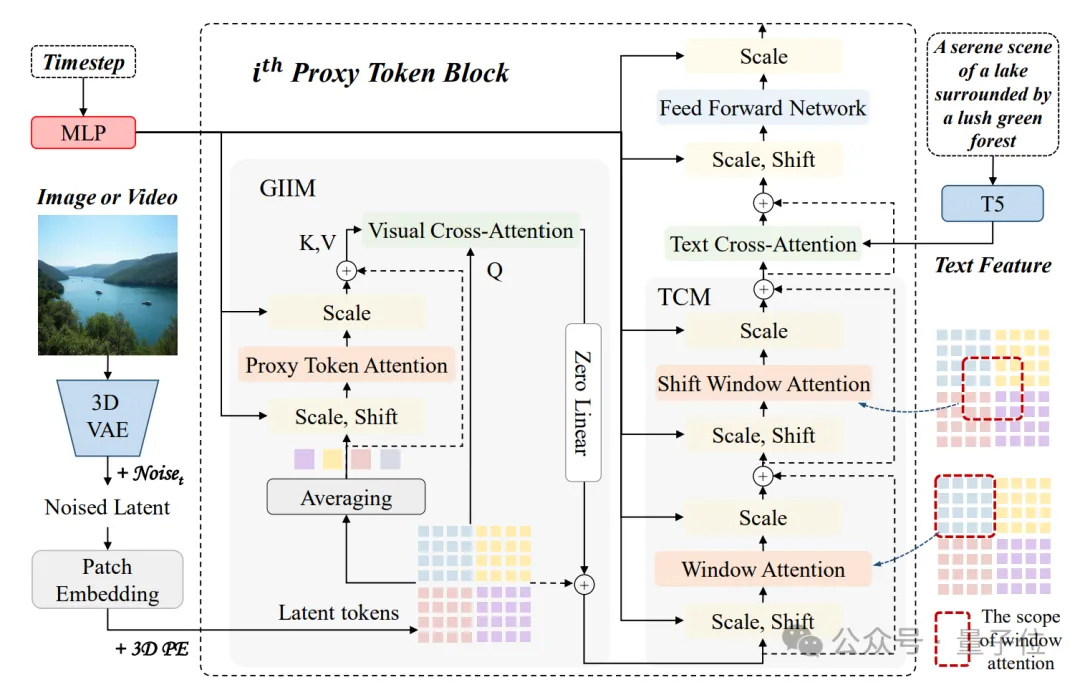
其中,GIIM使用稀疏proxy token机制促进所有潜在代码之间的高效交互,而空间相邻token的关联是不可忽略的,特别是对于细节纹理要求高的图像生成任务。
为此研究团队设计了TCM,其通过window attention和shift window attention进一步细化局部细节。
下面将详细介绍这两个部分:
给定一系列latent token,首先根据空间和时间先验(即位于同一个空间窗口)通过计算平均token得到一系列proxy tokens。
每个proxy token代表图像或视频内的一个局部区域的信息,并与其他局部区域中的proxy token通过self-attention进行交互以建立全局视觉关联。
随后,proxy tokens中蕴含的信息被通过与latent token的cross-attention传播到全部latent token中,从而实现高效的全局视觉信息交互。
由于稀疏proxy tokens交互的特点并且缺乏空间邻近token的相互关联,生成模型对于建模细节纹理的能力有限,难以满足生成任务的高质量需求。
为了解决这个问题,研究团队引入了局部window attention,补充模型的细节建模和平滑能力。
不过仅有window attention会导致窗口间token缺乏联系,导致生成图像格子现象明显。
因此,TCM中还引入了shift window attention,缓解局部window attention引起的问题。

由于计算window attention涉及的token数量较少,所以模型的计算复杂度并没有大规模增加。
对于图像生成任务,研究团队发现在不同分辨率下保持相同数量的窗口对于确保一致的语义层次结构至关重要,这有助于从低分辨率到高分辨率的训练过程。
同时,窗口应该维持较多的数量以防止窗口内的语义信息太过丰富,导致单个token不足以表示局部区域完成全局信息建模。
因此,研究团队将压缩比(????????,????ℎ,????????)设置为(1,2,2)、(1,4,4)、(1,8,8)和(1,16,16)分别在256、512、1024和2048分辨率。
当输入是图像时,????和????????将被设置为1。
对于视频生成任务,研究团队在不同分辨率下均设置????????=4以保持时间压缩一致。
由于帧、高度和宽度维度上的token压缩,PT-DiT可以训练更长视频的生成器。
PT-DiT仅使用少量的代表性token注意力,就降低了原始全token自注意力的计算冗余度。
研究团队进一步从理论上分析PT-DiT在计算复杂度方面的优势。
自注意力的计算复杂度为2N2D,计算如下:
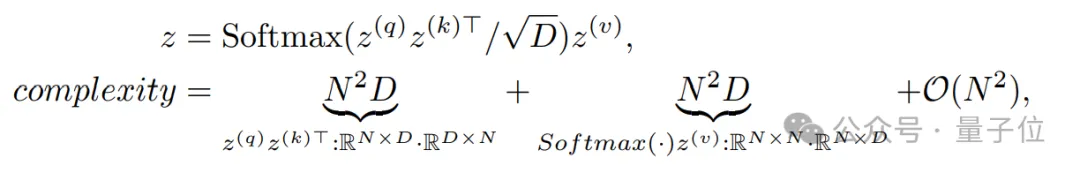
其中N表示潜在标记的长度,D表示特征维度。
类似地,GIIM和TCM的计算复杂度计算如下:
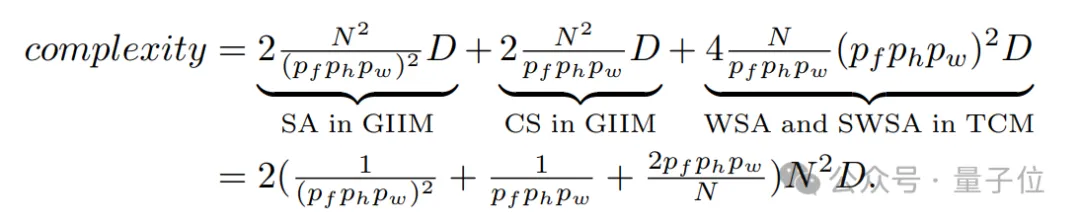
显然,由于代理标记化策略,PT-DiT具有显著的优势,尤其是在压缩比(????????,????ℎ,????????)较大和序列长度(N)较长的情况下。
当(????????,????ℎ,????????)为(1,2,2)、(1,4,4)、(1,8,8)和(1,16,16)且图像分辨率为256(N=256)、512(N=1024) 、1024(N=4096)和2048(N=16384)时,PT-DiT的计算复杂度仅为全局自注意力的34.3%、9.7%、4.7%、2.3%。
此外,PT-DiT对于序列长度较长的视频生成任务提供了更大的好处。
作者在T2I、T2V和T2MV任务上进行了定性和定量实验来评估Qihoo-T2X。
对于Text-to-Image,如图所示,Qihoo-T2I能够生成与提供的文本提示非常匹配的逼真图像。

对于Text-to-Video,研究人员将Qihoo-T2V与最近发布的开源文本转视频模型(即EasyAnimateV4和CogVideoX)在512分辨率下进行了比较,如图取得了更好的效果。

最后,作者进一步探索了PT-DiT在文本到多视图 (T2MV) 任务中的有效性。
经过训练的Qihoo-T2MV能够根据提供的文本指令从各个视点生成512x512x24图像,表现出强空间一致性。

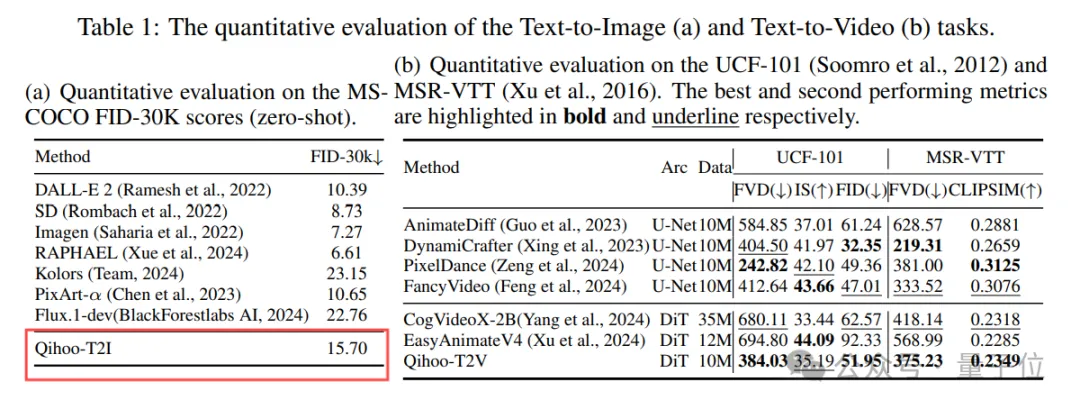
研究团队在MS-COCO FID-30K, UCF-101和MSR-VTT等benchmark上定量评估Qihoo-T2I和Qihoo-T2V。
结果显示,Qihoo-T2I和Qihoo-T2V均能实现有竞争力的性能,证明了PT-DiT的有效性。
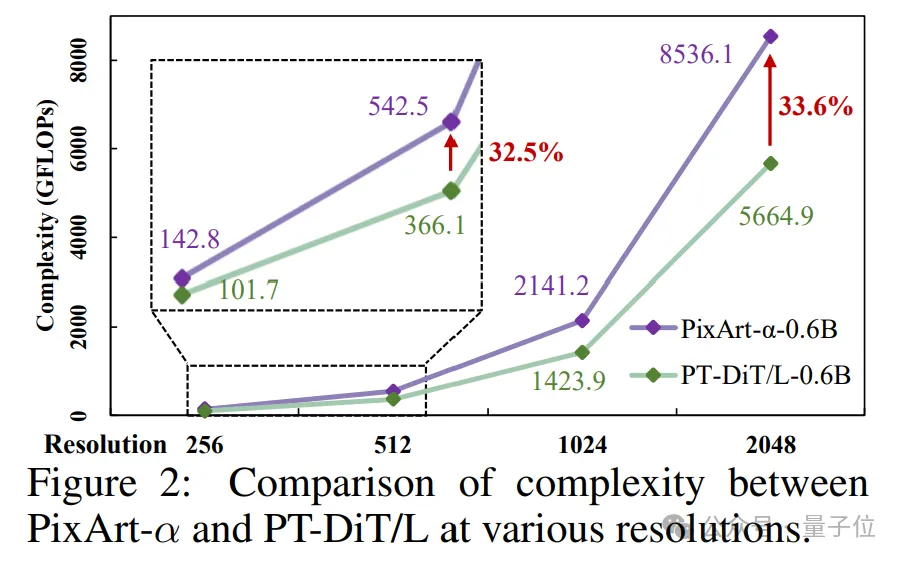
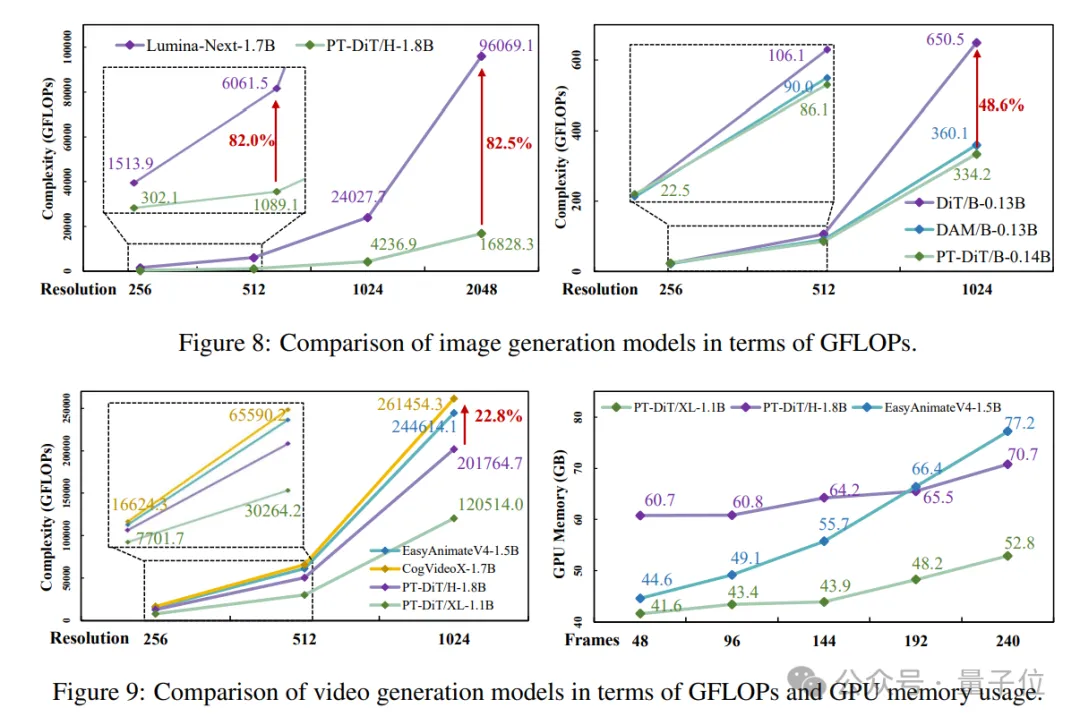
如图所示,无论是图像或视频生成任务,在相同参数规模下,PT-DiT相比现有Diffusion Transformer方法,均有大幅度的计算复杂度优势。
同时对比3D full attention建模的EasyanimateV4,其训练显存随着帧数的增加而爆炸增长,而PT-DiT的显存仅有微弱增长,表明PT-DiT有潜力完成更长时间的视频生成任务。
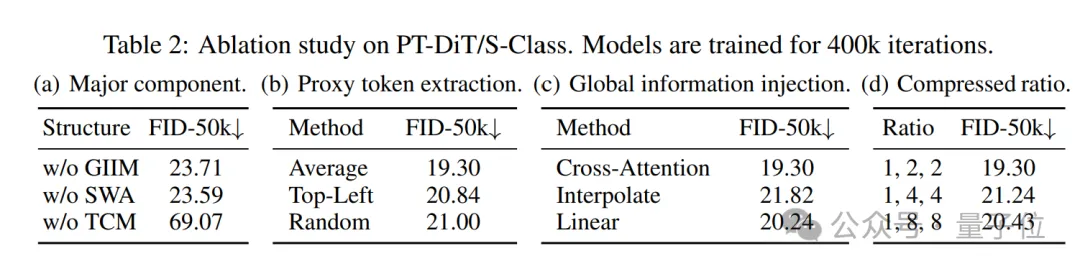
最后的消融实验也验证了PT-DiT中关键设计的合理性。
论文地址:
https://arxiv.org/pdf/2409.04005
项目主页:
https://360cvgroup.github.io/Qihoo-T2X
代码仓库:
https://github.com/360CVGroup/Qihoo-T2X
文章来自于“量子位”,作者“Qihoo-T2X团队”。




【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
