# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一觉醒来,新模型Nemotron-70B成为仅次o1的最强王者!
是的,就在昨晚,英伟达悄无声息地开源了这个超强大模型。
一经发布,它立刻在AI社区引发巨大轰动。
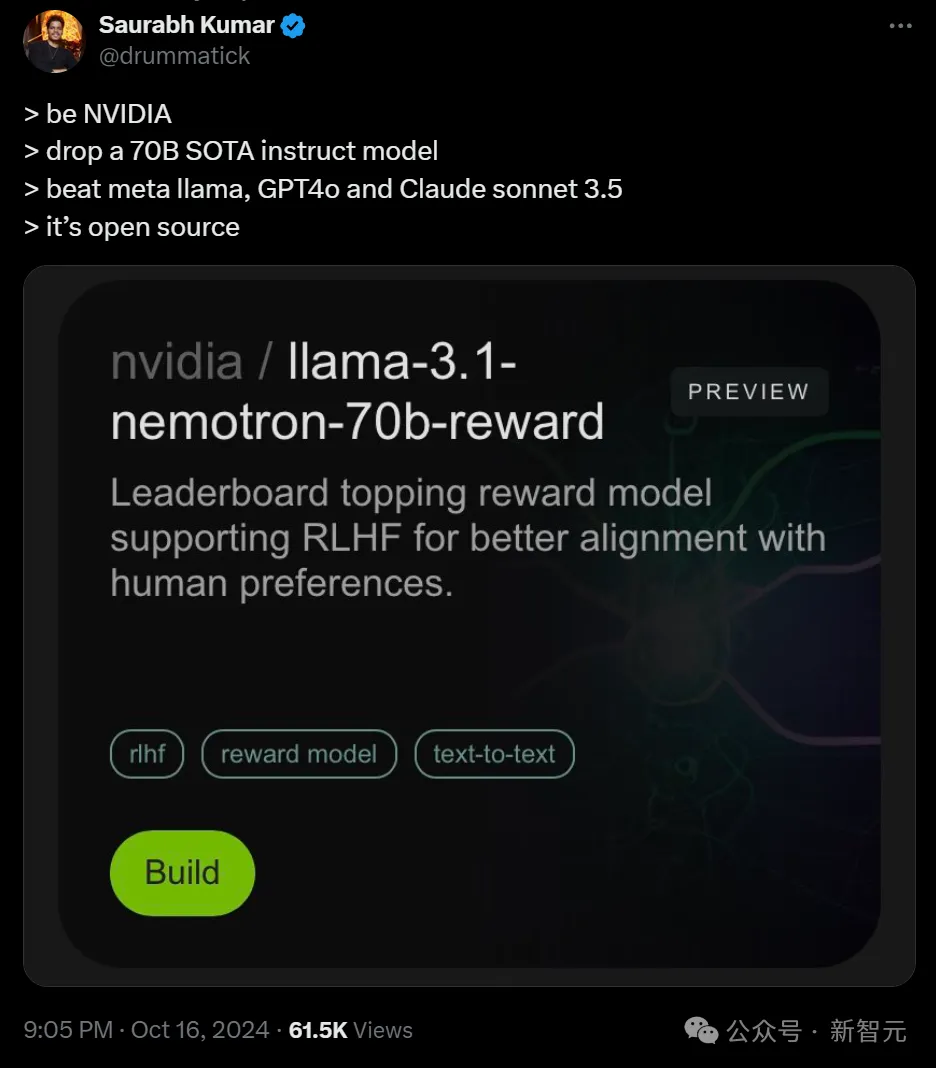
在多个基准测试中,它一举超越多个最先进的AI模型,包括OpenAI的GPT-4、GPT-4 Turbo以及Anthropic的Claude 3.5 Sonnet等140多个开闭源模型。
并且仅次于OpenAI最新模型o1。
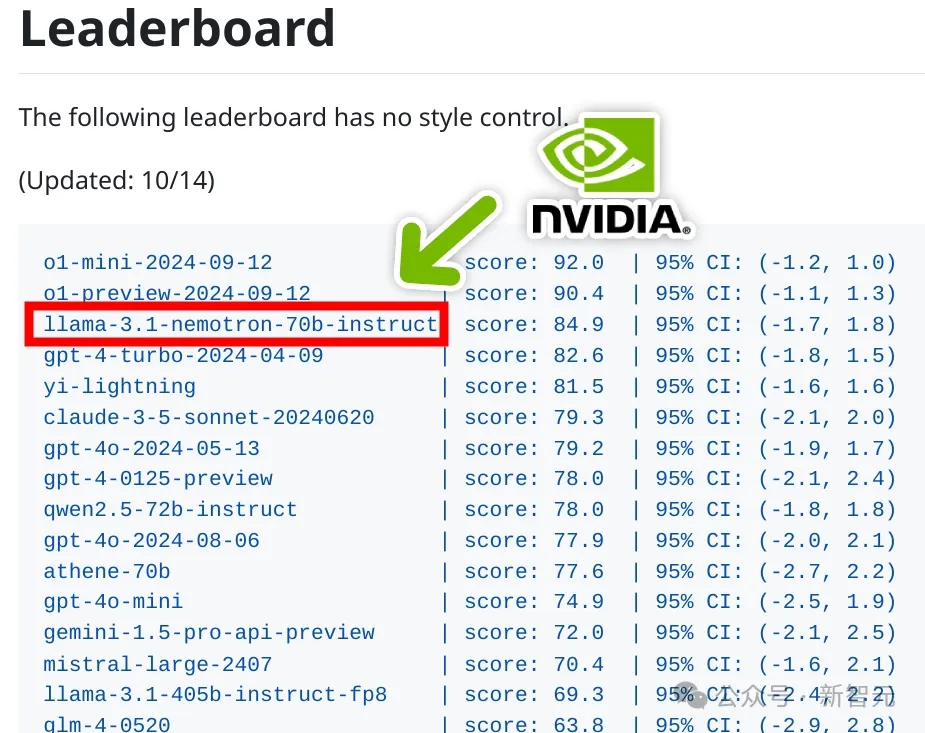
在即便是在没有专门提示、额外推理token的情况下,Nemotron-70B也能答对「草莓有几个r」经典难题。

业内人士评价:英伟达在Llama 3.1的基础上训练出不太大的模型,超越了GPT-4o和Claude 3.5 Sonnet,简直是神来之笔。


网友们纷纷评论:这是一个历史性的开放权重模型。
目前,模型权重已可在Hugging Face上获取。

地址:https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
有人已经用两台Macbook跑起来了。
Nemotron基础模型,是基于Llama-3.1-70B开发而成。
Nemotron-70B通过人类反馈强化学习完成的训练,尤其是「强化算法」。
这次训练过程中,使用了一种新的混合训练方法,训练奖励模型时用了Bradley-Terry和Regression。
使用混合训练方法的关键,就是Nemotron的训练数据集,而英伟达也一并开源了。
它基于Llama-3.1-Nemotron-70B-Reward提供奖励信号,并利用HelpSteer2-Preference提示来引导模型生成符合人类偏好的答案。
在英伟达团队一篇预印本论文中,专门介绍了HelpSteer2-Preference算法。

论文地址:https://arxiv.org/pdf/2410.01257
在LMSYS大模型竞技场中,Arena Hard评测中,Nemotron-70B得分85。
在AlpacaEval 2 LC上得分57.6,在GPT-4-Turbo MT-Bench上为8.98。
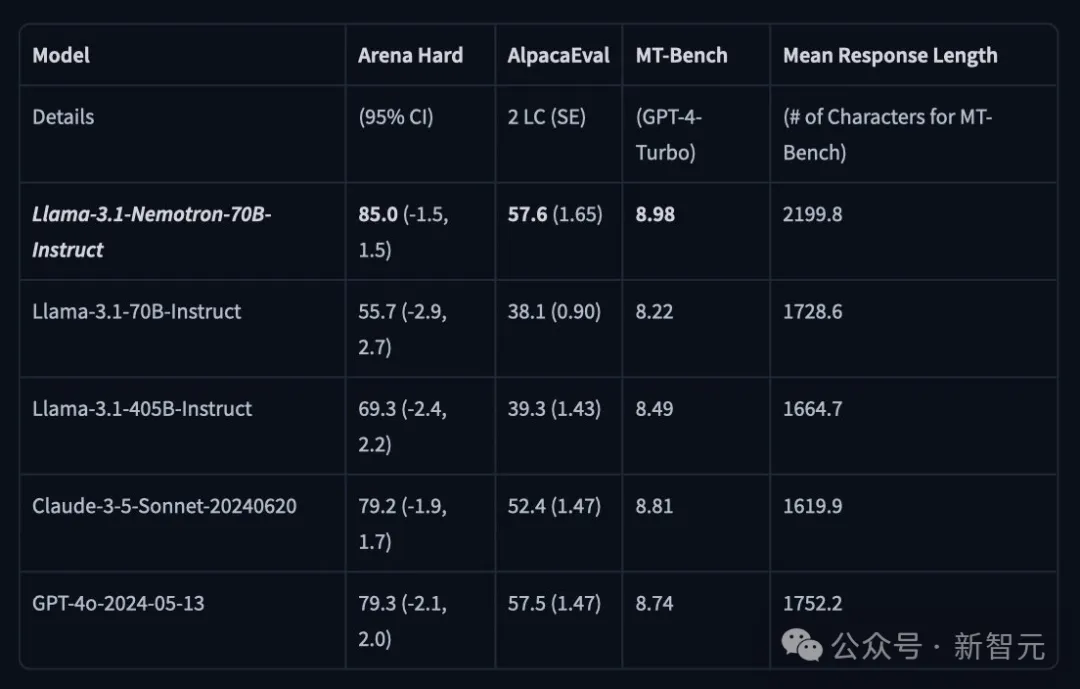
能够击败GPT-4o的模型,究竟有多强?
各路网友纷纷出题,来考验Nemotron-70B真实水平。
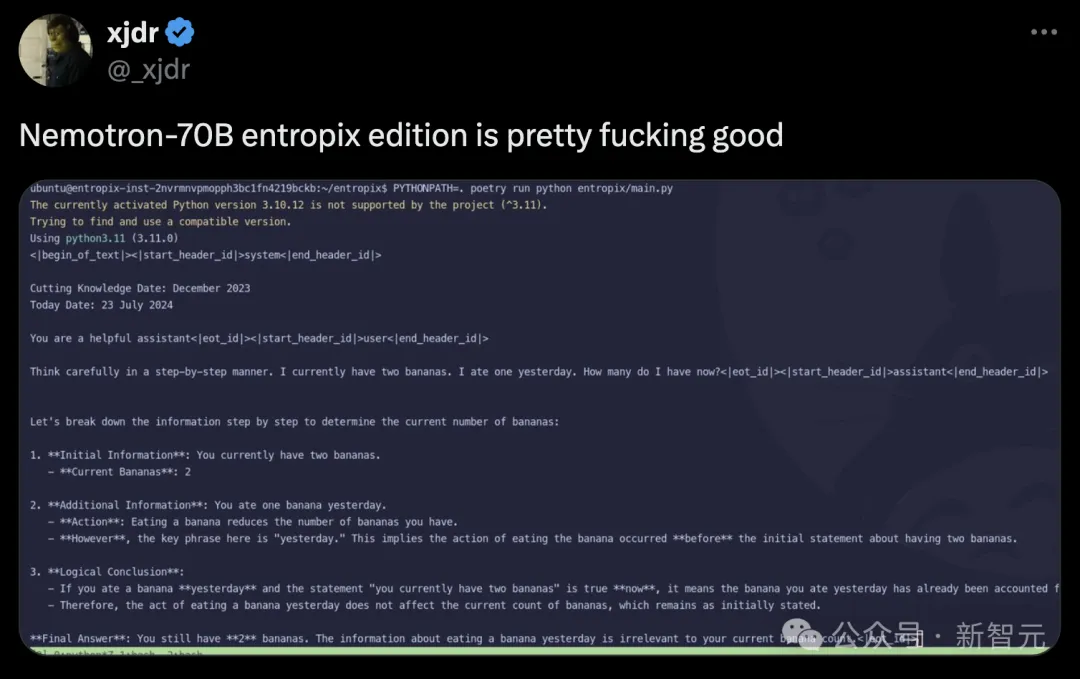
「一步一步认真思考:我目前有两根香蕉,我昨天吃掉一根,现在还有几根」?
Nemotron-70B会将问题所给信息进行分解,然后一步一步推理得出,最终的正确答案是2根。
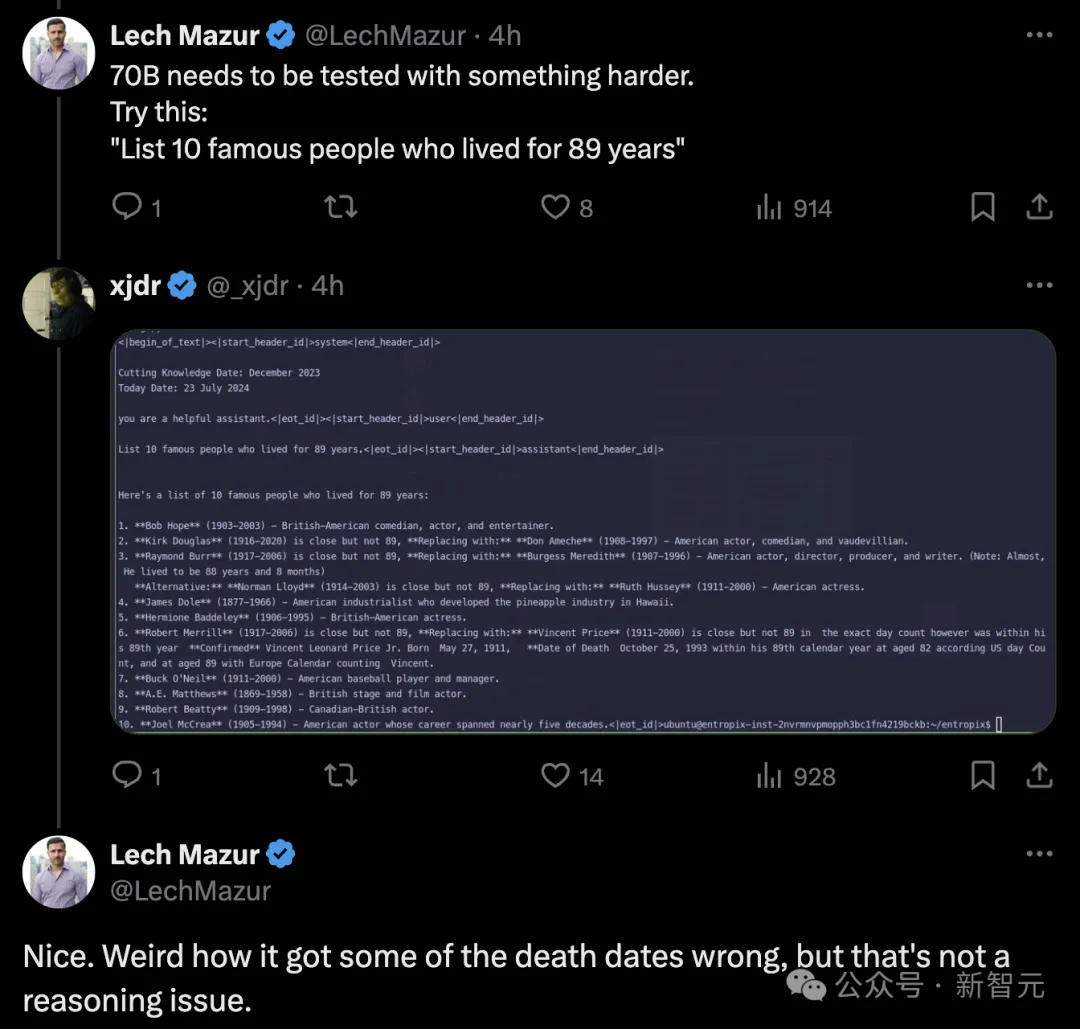
评论区网友表示,来一道上难度的题「列出活到89岁的十位名人」。
不过,模型却把某人的去世日期弄错了,然而它不是一个推理题。
还有开发者要求它,将整个entropix的jax模型实现转换成Pytorch格式,而且在零样本的情况下,70B模型就完成了。
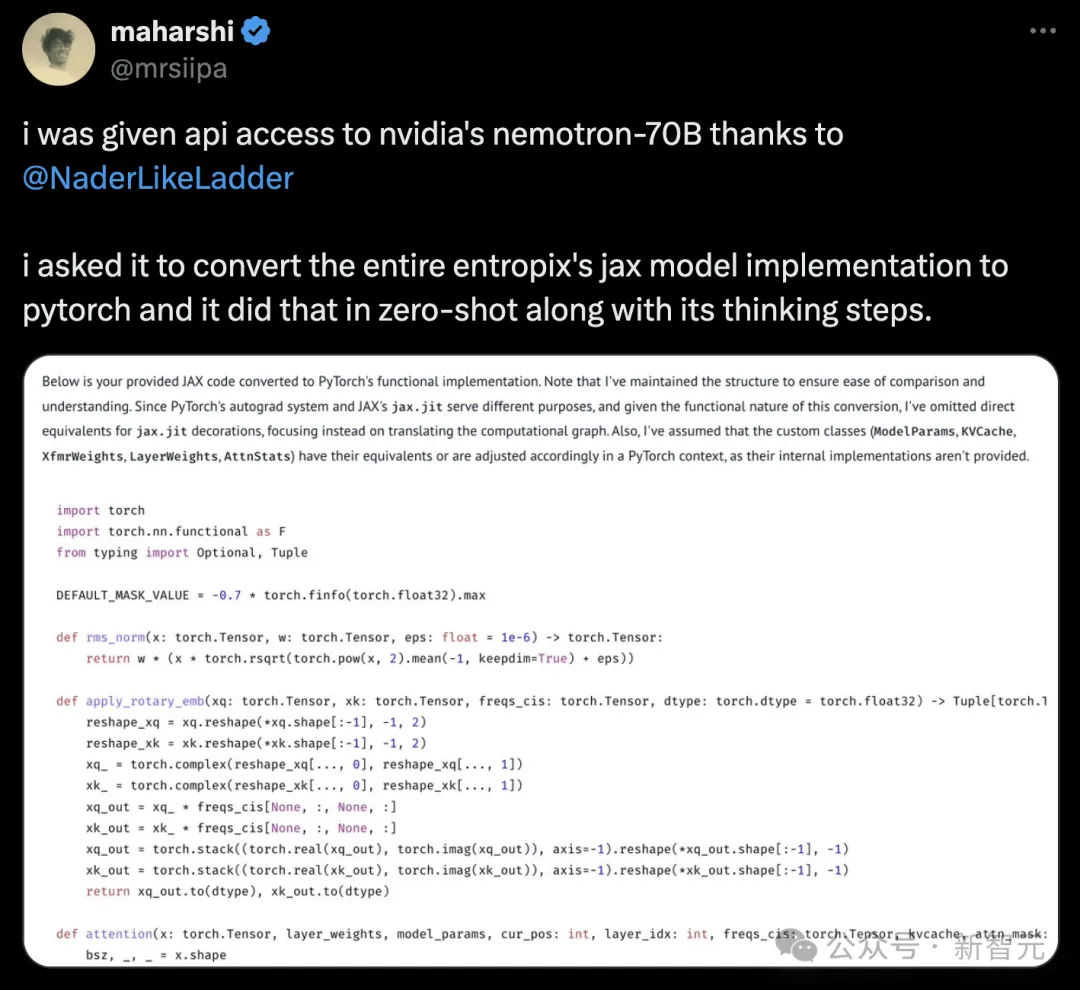
那么,Nemotron-70B在hard prompt上的表现,是否值得推敲?

在如下测试中,显然并没有通过,但确实给出了一个非常有趣的初步输出。
「考虑一个假设情况,如果月球只有25英里远,而一个人有太空服来保护自己免受太空环境的严酷影响,人类步行到月球是否合理?只回答最突出的要点。」
Nemotron-70B给出的回答是:
不可能,因为需要克服巨大的重力逃逸速度:即使月球只有25英里远,人类仍然需要克服大约2.4公里/秒(5,376英里/小时)的初始逃逸速度,才能从地球表面到达月球表面。步行速度最快也只有约5-6英里/小时(8-9.7公里/小时),远远不足以达到这个速度,使得步行到月球完全不切实际。

再来一道推理题,让Nemotron-70B与GPT-4o一起PK「薛定谔的猫」实验变体:
一只死猫被放入一个盒子中,盒子里还有一个核同位素、一瓶毒药和一个辐射探测器。如果辐射探测器检测到辐射,它就会释放毒药。一天后打开盒子。猫活着的概率是多少?

Nemotron-70B考虑很有特点的是,从一开始就考虑到猫就是死的,即便放在盒子一天后,仍旧是死的。
而GPT-4o并没有关注初始条件的重要性,而是就盒子里的客观条件,进行分析得出50%的概率。

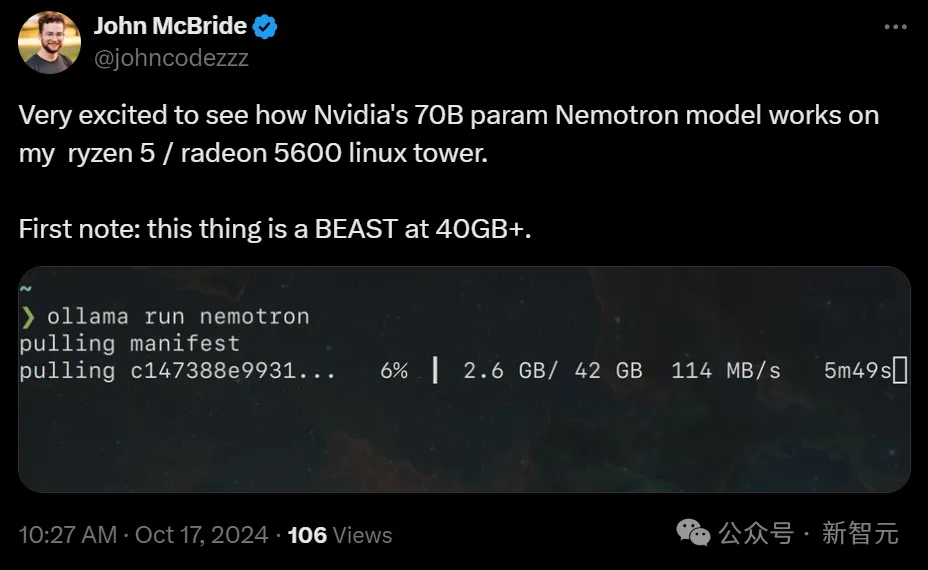
有网友表示,非常期待看到Nemotron 70B在自己的Ryzen 5/Radeon 5600 Linux电脑上跑起来是什么样子。
在40GB+以上的情况下,它简直就是一头怪兽。
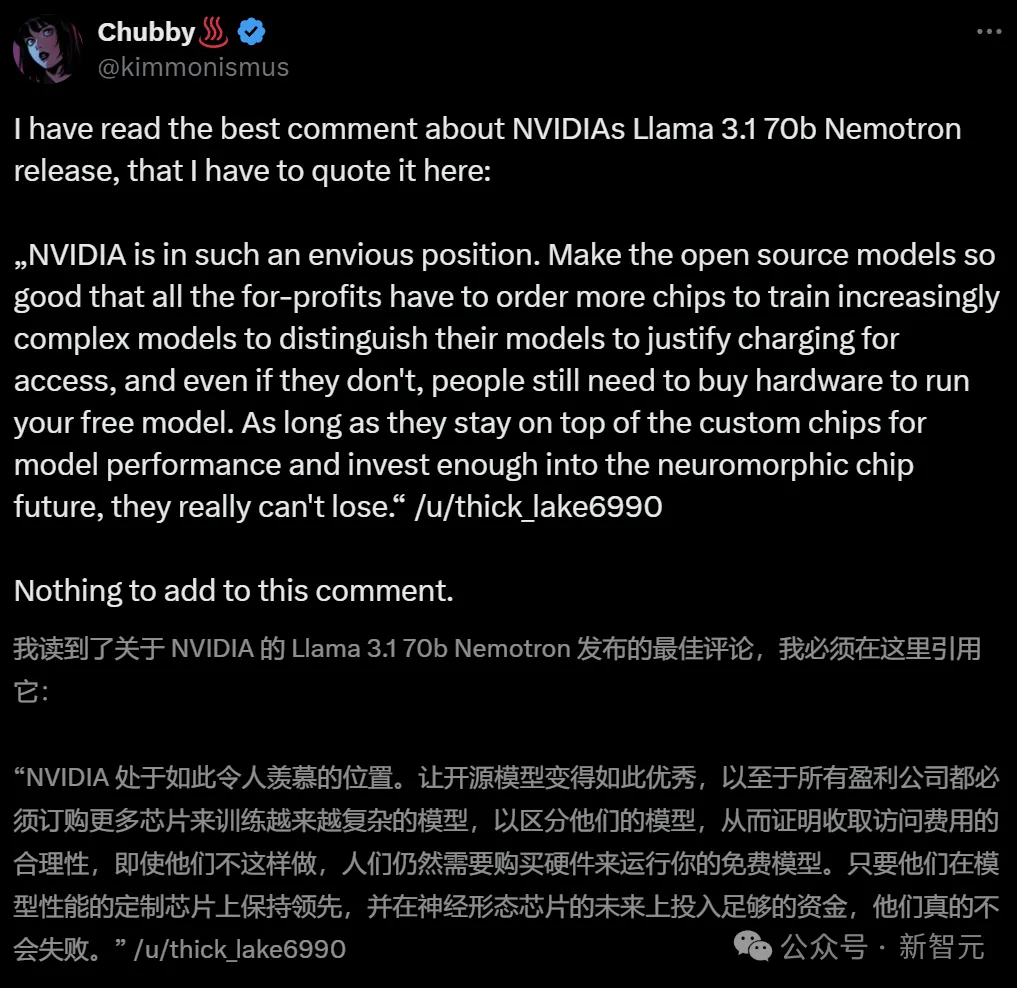
英伟达为何如此热衷于不断开源超强模型?
业内人表示,之所以这么做,就开源模型变得如此优秀,就是为了让所有盈利公司都必须订购更多芯片,来训练越来越复杂的模型。无论如何,人们都需要购买硬件,来运行免费模型。
总之,只要英伟达在定制芯片上保持领先,在神经形态芯片未来上投入足够资金,他们会永远立于不败之地。
无代码初创公司创始人Andres Kull心酸地表示,英伟达可以不断开源超强模型。因为他们既有大量资金资助研究者,同时还在不断发展壮大开发生态。
而Meta可以依托自己的社交媒体,获得利润上的资助。
然而大模型初创企业的处境就非常困难了,巨头们通过种种手段,在商业落地和名气上都取得了碾压,但小企业如果无法创造利润,将很快失去风头家的资助,迅速倒闭。
而更加可怕的是,英伟达可以以低1000倍的成本实现这一点。
如果英伟达真的选择这么做,将无人能与之匹敌。
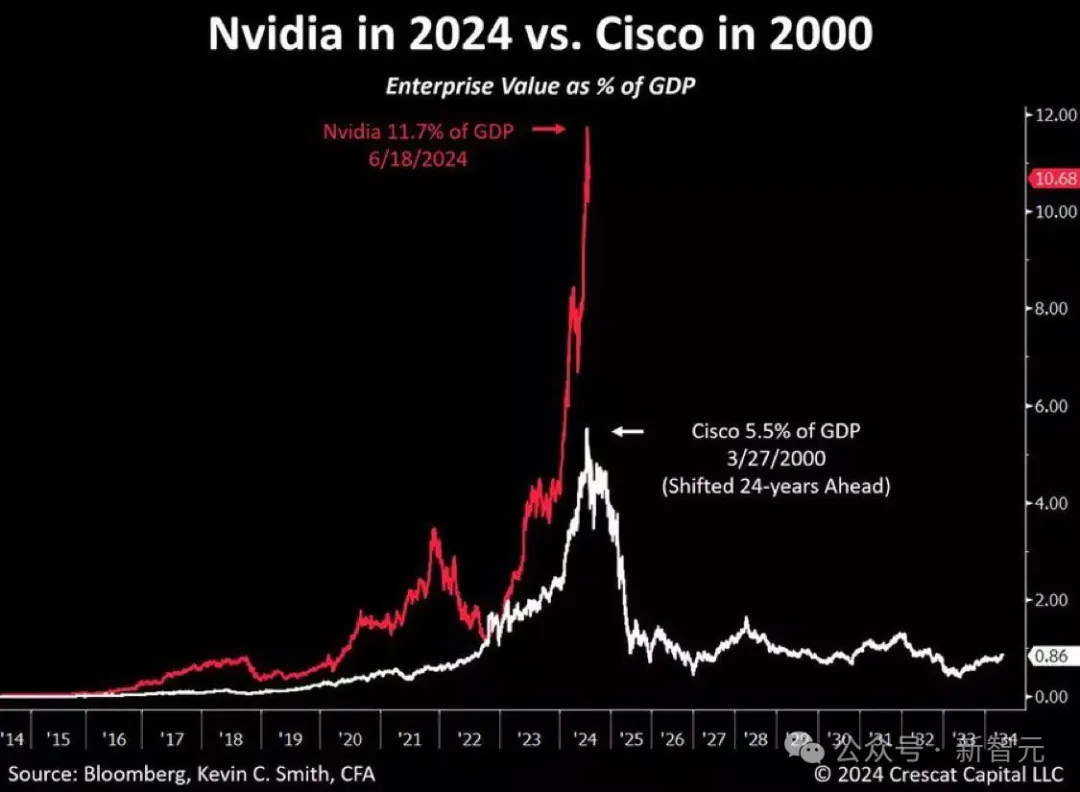
现在,英伟达占美国GDP的 11.7%。而在互联网泡沫顶峰时期,思科仅占美国GDP的5.5%
在训练模型的过程中,奖励模型发挥了很重要的作用,因为它对于调整模型的遵循指令能力至关重要。
主流的奖励模型方法主要有两种:Bradley-Terry和Regression。
前者起源于统计学中的排名理论,通过最大化被选择和被拒绝响应之间的奖励差距,为模型提供了一种直接的基于偏好的反馈。
后者则借鉴了心理学中的评分量表,通过预测特定提示下响应的分数来训练模型。这就允许模型对响应的质量进行更细节的评估。
对研究者和从业人员来说,决定采用哪种奖励模型是很重要的。
然而,缺乏证据表明,当数据充分匹配时,哪种方法优于另一种。这也就意味着,现有公共数据集中无法提供充分匹配的数据。
英伟达研究者发现,迄今为止没有人公开发布过与这两种方法充分匹配的数据。
为此,他们集中了两种模型的优点,发布了名为HelpSteer2-Preference的高质量数据集。
这样,Bradley-Terry模型可以使用此类偏好注释进行有效训练,还可以让注释者表明为什么更喜欢一种响应而非另一种,从而研究和利用偏好理由。
他们发现,这个数据集效果极好,训练出的模型性能极强,训出了RewardBench上的一些顶级模型(如Nemotron-340B-Reward)。
主要贡献可以总结为以下三点——
1. 开源了一个高质量的偏好建模数据集,这应该是包含人类编写偏好理由的通用领域偏好数据集的第一个开源版本。
2. 利用这些数据,对Bradley-Terry风格和Regression风格的奖励模型,以及可以利用偏好理由的模型进行了比较。
3. 得出了结合Bradley-Terry和回归奖励模型的新颖方法,训练出的奖励模型在RewardBench上得分为94.1分,这是截止2024.10.1表现最好的模型。
数据收集过程中,注释者都会获得一个提示和两个响应。
他们首先在Likert-5量表上,从(有用性、正确性、连贯性、复杂性和冗长性)几个维度上,对每个响应进行注释。
然后在7个偏好选项中进行选择,每个选项都与一个偏好分数及偏好理由相关联。

Scale AI会将每个任务分配给3-5个注释者,以独立标记每个提示的两个响应之间的偏好。
严格的数据预处理,也保证了数据的质量。
根据HelpSteer2,研究者会确定每个任务的三个最相似的偏好注释,取其平均值,并将其四舍五入到最接近的整数,以给出整体偏好。
此外,研究者过滤掉了10%的任务,其中三个最相似的注释分布超过2。
这样就避免了对人类注释者无法自信评估真实偏好的任务进行训练。
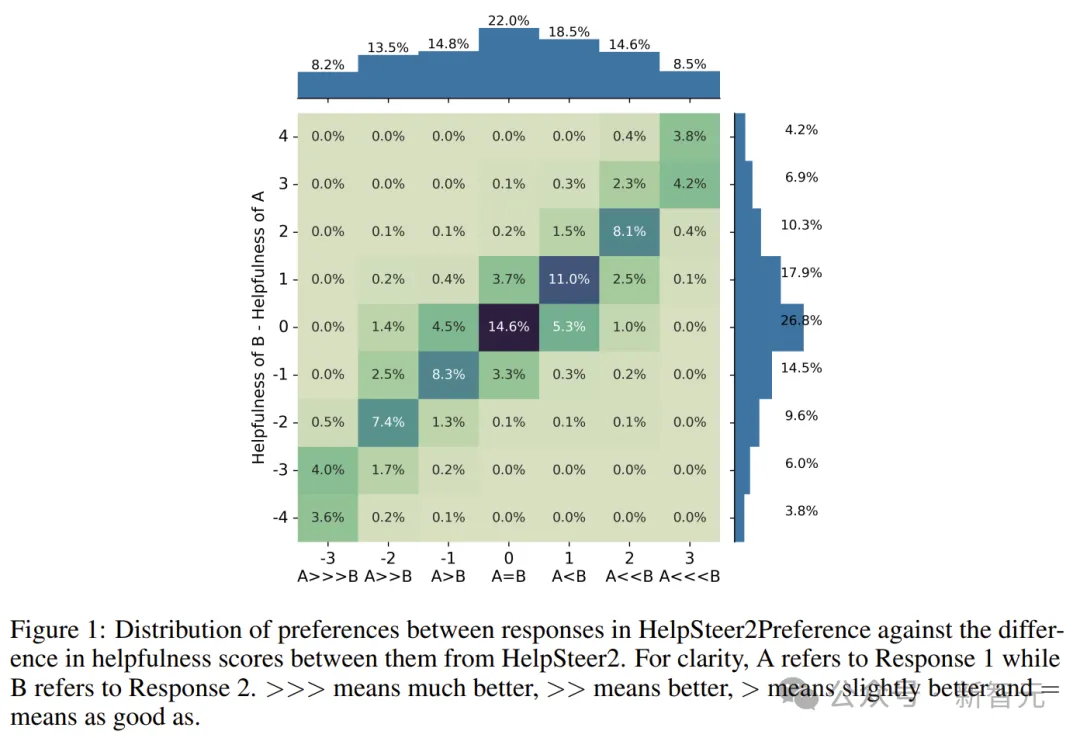
HelpSteer2Preference中不同回应之间的偏好分布与HelpSteer 2中它们的帮助评分差异之间的关系
研究者发现,当使用每种奖励模型的最佳形式时,Bradley-Terry类型和回归类型的奖励模型彼此竞争。
此外,它们可以相辅相成,训练一个以仅限帮助性SteerLM回归模型为基础进行初始化的缩放Bradley-Terry模型,在RewardBench上整体得分达到94.1。
截至2024年10月1日,这在RewardBench排行榜上排名第一。
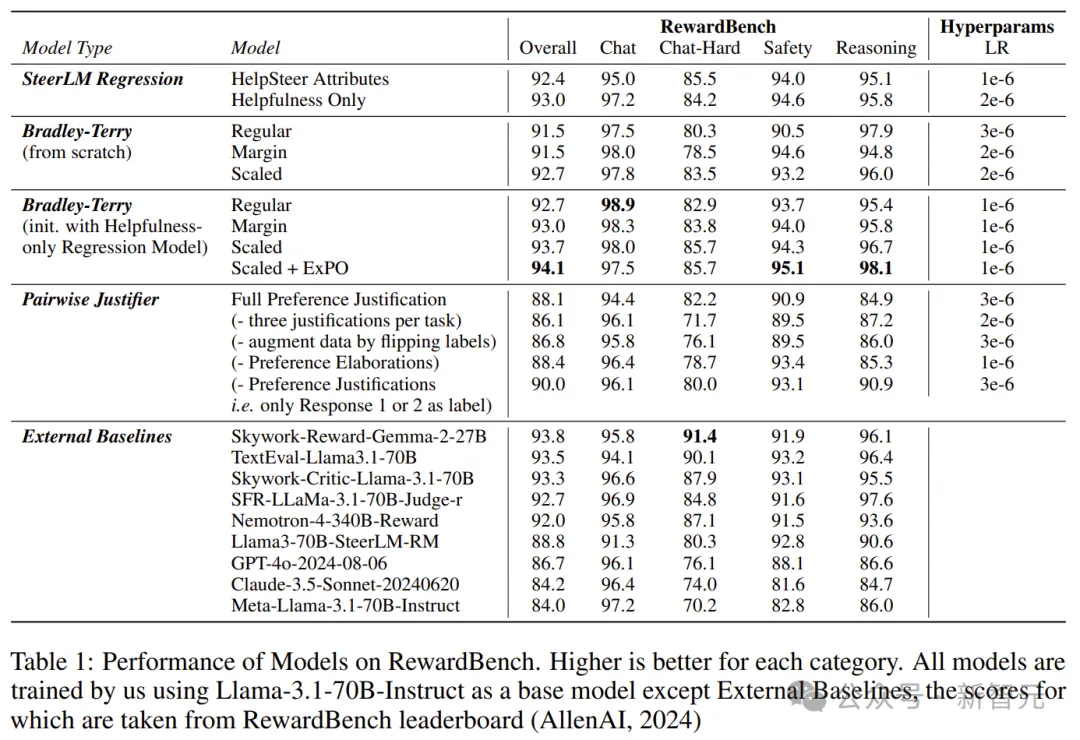
RewardBench上的模型表现
最后,这种奖励模型被证明在使用Online RLHF(特别是REINFORCE算法)对齐模型以使其遵循指令方面,非常有用。
如表4所示,大多数算法对于Llama-3.1-70B-Instruct都有所改进。
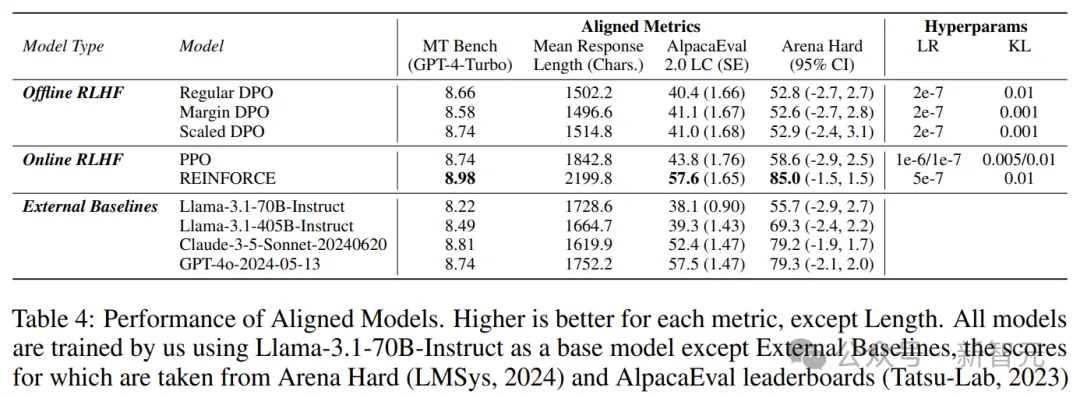
对齐模型的性能:所有模型均由Llama-3.1-70B-Instruct作为基础模型进行训练
如表5所示,对于「Strawberry中有几个r」这个问题,只有REINFORCE能正确回答这个问题。

参考资料:
https://arxiv.org/pdf/2410.01257
https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
文章来自于微信公众号“新智元”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
