# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
英伟达不仅要做显卡领域的领先者,还要在大模型领域逐渐建立起自己的优势。
今天,英伟达又开源了一个性能超级强大的模型 —— Llama-3.1-Nemotron-70B-Instruct,它击败了 OpenAI 的 GPT-4o 和 Anthropic 的 Claude-3.5 Sonnet 等多个开闭源模型。
从命名来看,显然 Llama-3.1-Nemotron-70B-Instruct 是基于 Llama-3.1-70B 打造而成。
从下图中大模型榜单可以看到, Llama-3.1-Nemotron-70B-Instruct 的性能仅次于 OpenAI 最新 o1 大模型了。
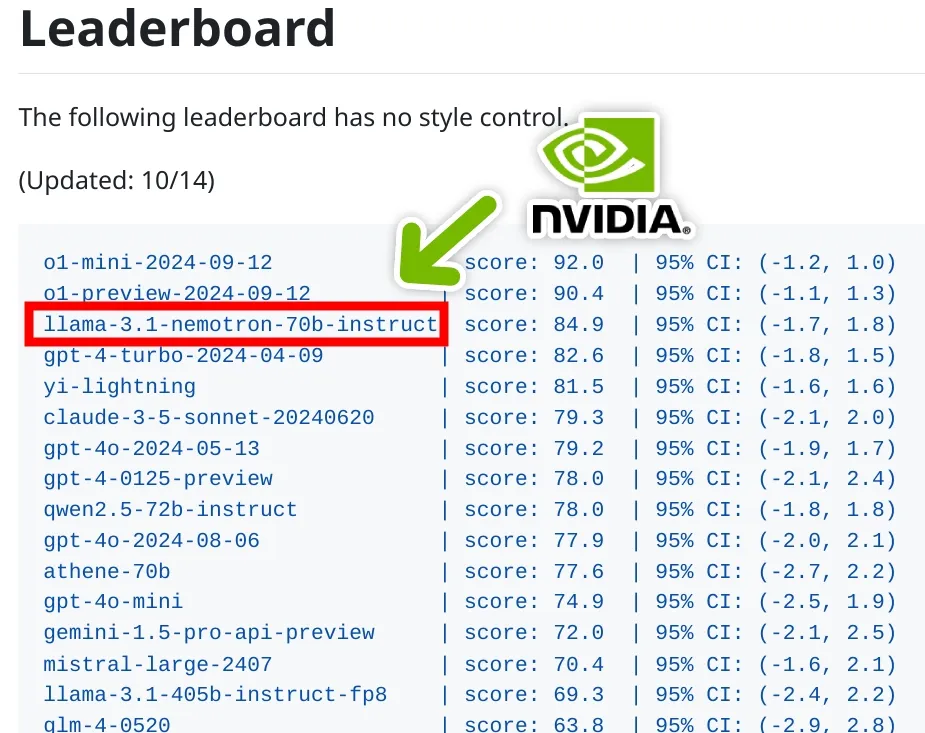
图源:https://x.com/itsPaulAi/status/1846565333240607148
目前,Llama-3.1-Nemotron-70B-Instruct 已经可以在线体验了。Starwberry 中有几个 r 这样的题目难不倒它。
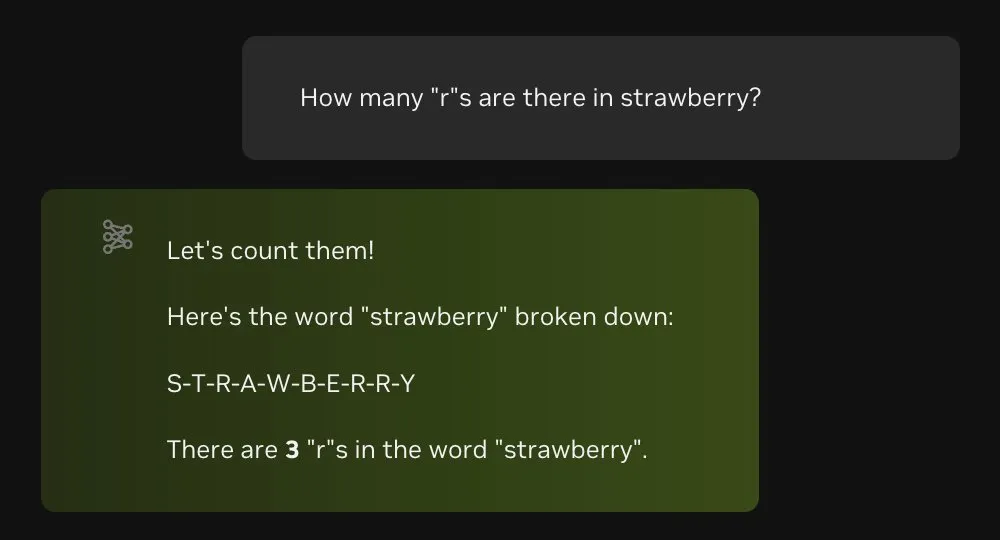
图源:https://x.com/mrsiipa/status/1846551610199273817
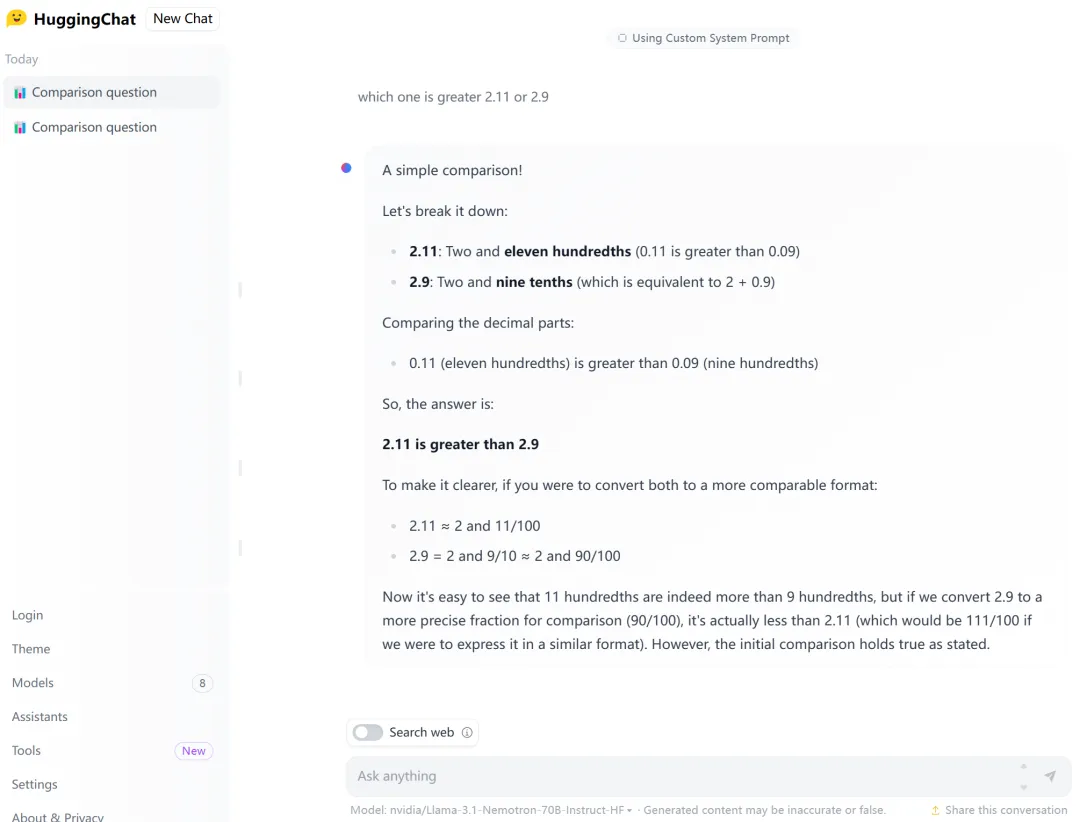
不过有时也一本正经地胡说八道,比如「2.11 和 2.9 哪个大」。
体验地址:https://huggingface.co/chat/
不过英伟达也强调了,他们主要是提高模型在通用领域的性能,尚未针对数学等专业领域的表现进行调优,或许等待一段时间,模型就可以正确回答 2.11 和 2.9 哪个大了。
此外,英伟达还开源了 Nemotron 的训练数据集 HelpSteer2,包括如下:
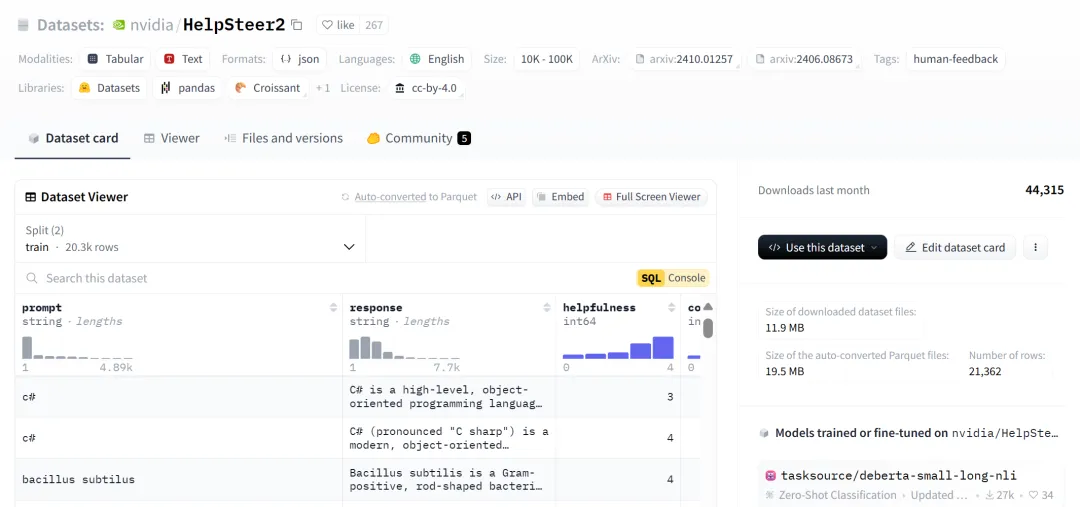
数据集地址:https://huggingface.co/datasets/nvidia/HelpSteer2
除了 Llama-3.1-Nemotron-70B-Instruct 之外,英伟达还开源了另一个 Llama-3.1-Nemotron-70B-Reward 模型。
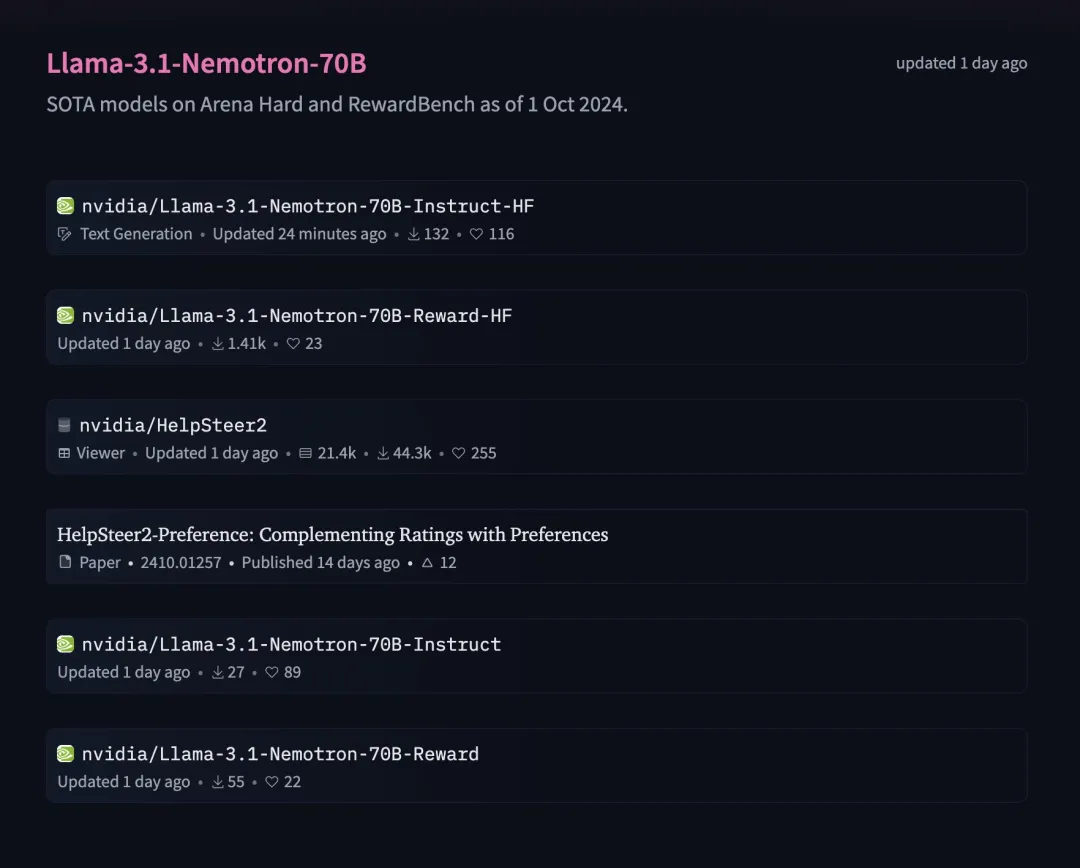
模型合集地址:https://huggingface.co/collections/nvidia/llama-31-nemotron-70b-670e93cd366feea16abc13d8
Llama-3.1-Nemotron-70B-Instruct 是英伟达定制的大型语言模型,旨在提高 LLM 生成的响应的有用性。
Llama-3.1-Nemotron-70B-Instruct 在 Arena Hard 基准上得分为 85.0,在 AlpacaEval 2 LC 基准上得分为 57.6,在 GPT-4-Turbo MT-Bench 基准上得分为 8.98。
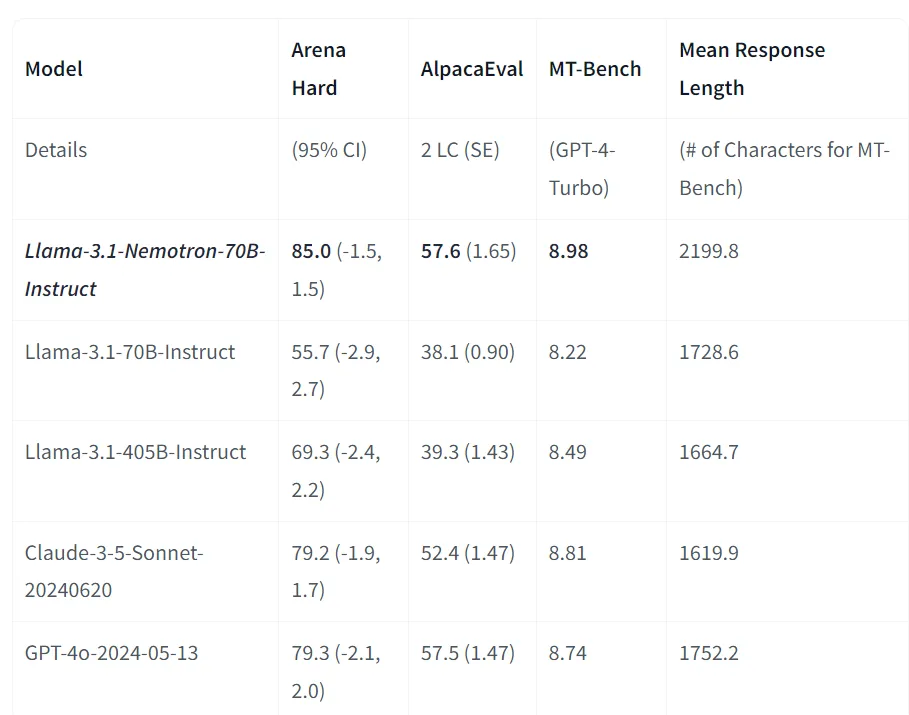
截至 2024 年 10 月 1 日,Llama-3.1-Nemotron-70B-Instruct 在三个自动对齐基准中均排名第一,击败了 GPT-4o 和 Claude 3.5 Sonnet 等强大的前沿模型。
对于这一成绩,有网友表示,在 Arena Hard 基准上拿到 85.0 分,对于一个 70B 的模型来说,确实是件大事。

还有网友讨论说,用相同的提示测试 GPT-4o 和英伟达模型,所有的答案都是英伟达的模型好,并且是好很多的那种。

「加大题目难度,Llama-3.1-Nemotron-70B-Instruct 照样回答的很好。」
在训练细节上,该模型在 Llama-3.1-70B-Instruct 基础上使用了 RLHF 技术(主要是 REINFORCE 算法),并采用了 Llama-3.1-Nemotron-70B-Reward 和 HelpSteer2 偏好提示作为初始训练策略。
此外,Llama-3.1-Nemotron-70B-Reward 是英伟达开发的一个大型语言模型,用于预测 LLM 生成的响应的质量。该模型使用 Llama-3.1-70B-Instruct Base 进行训练,并结合了 Bradley Terry 和 SteerLM 回归奖励模型方法。
Llama-3.1-Nemotron-70B-Reward 在 RewardBench 榜单的 Overall 排名中表现最佳,并在 Chat(聊天)、Safety(安全)和 Reasoning(推理)排名中也有出色表现。
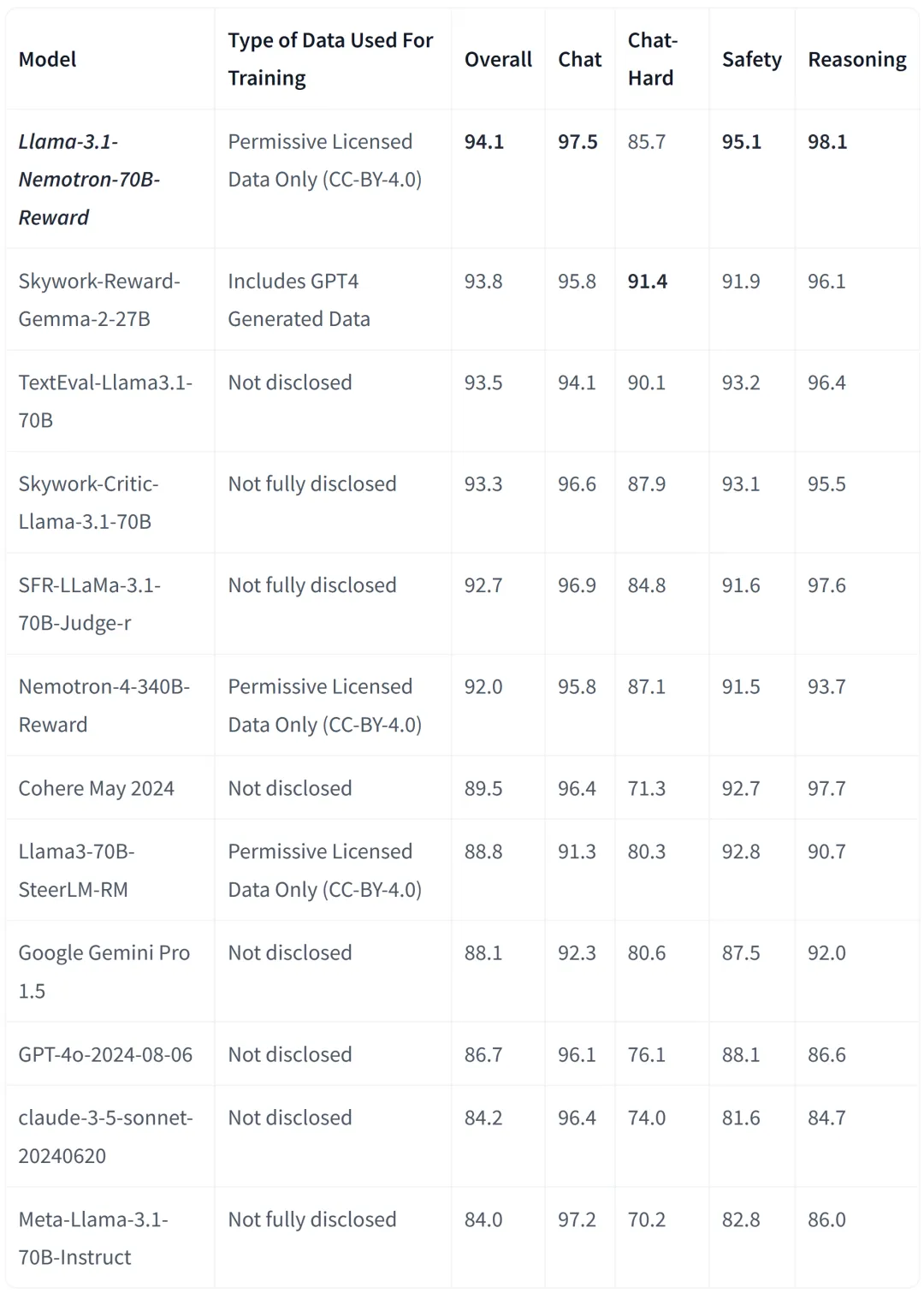
不过,想要部署该模型还需要一些先决条件,至少需要一台带有 4 个 40GB 或 2 个 80GB NVIDIA GPU 的机器,以及 150GB 的可用磁盘空间。想要尝试的小伙伴跟着官方给出的步骤进行部署即可。
参考链接:
https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct
https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Reward
文章来自于“机器之心”,作者“杜伟、陈陈”。




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
