# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天,Meta 分享了一系列研究和模型,这些研究和模型支撑 Meta 实现高级机器智能(AMI)目标,同时也致力于开放科学和可复现性。
这些工作侧重于 AMI 的构建模块,包括感知、语音和语言、推理、具身智能和对齐。研究工作包括 SAM 2.1、Spirit LM、Layer Skip、自学习评估器等。

SAM 2 已经被应用于跨学科(包括医学图像、气象学等)研究,并且产生了良好的影响。现在,Meta 宣布推出性能更强的 SAM 2.1。
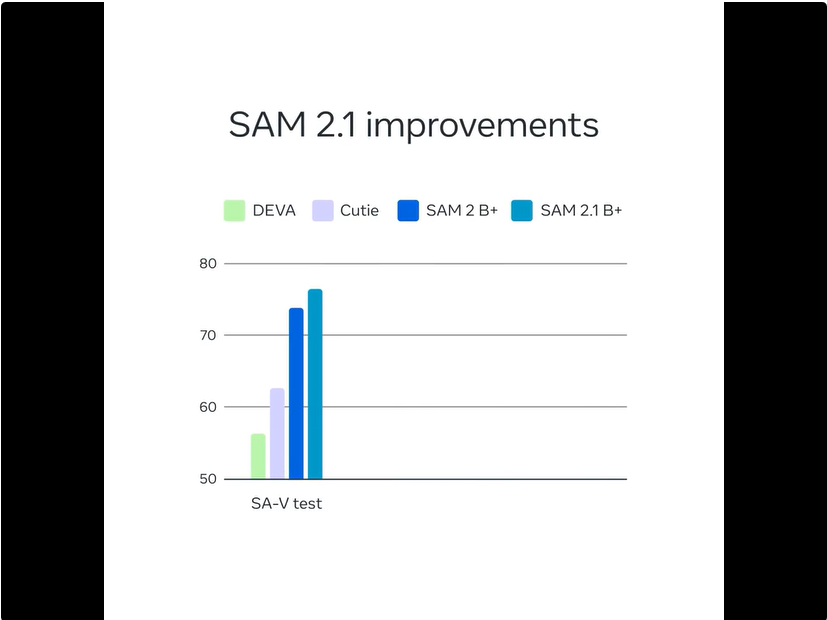
Meta 引入了额外的数据增强技术来模拟 SAM 2 之前遇到的视觉相似物体和小物体的存在,通过在较长的帧序列上训练模型并对空间和物体指针内存的位置编码进行一些调整,提高了 SAM 2 的遮挡处理能力。

大型语言模型经常被用于构建文本到语音 pipeline,其中语音通过自动语音识别 (ASR) 进行转录,然后由 LLM 生成文本,最终使用文本到语音 (TTS) 转换为语音。然而,这个过程损害了语音表达。
为了解决这一限制,Meta 构建了开源多模态语言模型 Spirit LM,实现了语音和文本的无缝集成。
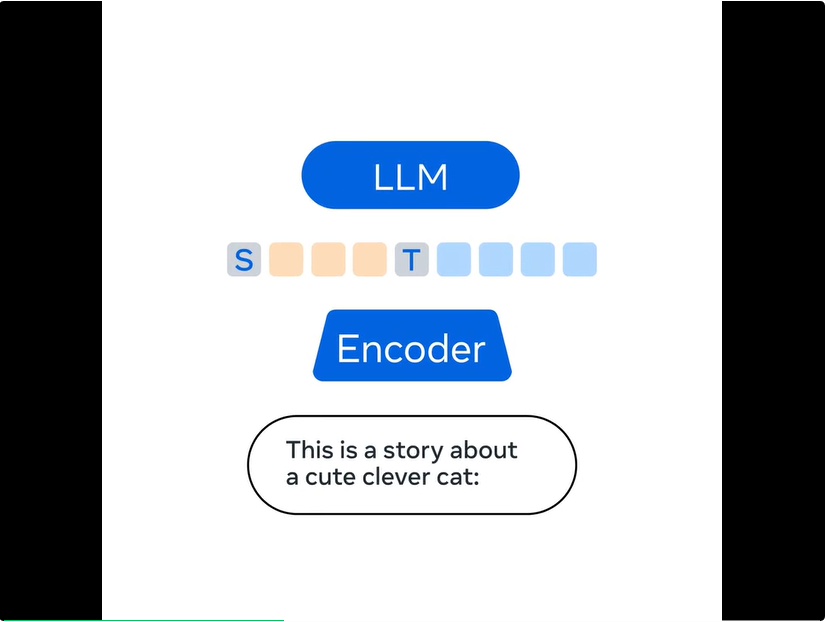
Spirit LM 在语音和文本数据集上使用词级交织方法进行训练,以实现跨模态生成。Meta 开发了两个版本的 Spirit LM,以展示文本模型的语义生成能力和语音模型的表达能力。

大型语言模型已在各个行业中广泛采用,但其高计算和内存要求会消耗大量能源,并且可能带来高昂的经济成本。为了应对这些挑战,Meta 提出了一种端到端解决方案 ——Layer Skip,以加快 LLM 在新数据上的生成时间,而无需依赖专门的硬件或软件。


Layer Skip 通过执行其层的子集并利用后续层进行验证和校正来加速 LLM。现在,Meta 又要发布 Layer Skip 的推理代码和微调检查点。Llama 3、Llama 2 和 Code Llama 等模型已经使用 Layer Skip 进行了优化。Layer Skip 可以将模型性能提升高达 1.7 倍。
Lingua 是一个轻量级且独立的代码库,旨在助力大规模训练语言模型。Lingua 将使人们更容易将概念转化为实际实验,并优先考虑简单性和可复用性以加速研究。高效且可定制的平台还允许研究人员以最少的设置快速测试他们的想法。
MEXMA 是一种新型预训练跨语言句子编码器。在训练过程中,通过结合 token 层级和句子层级的目标,MEXMA 的表现优于以往的方法。
研究团队发现,之前用于训练跨语言句子编码器的方法仅通过句子表征来更新编码器,而通过引入 token 层级的目标,研究者可以更好地更新编码器,从而改进性能。

MEXMA 覆盖了 80 种语言,并且在句子分类等下游任务中表现出色。

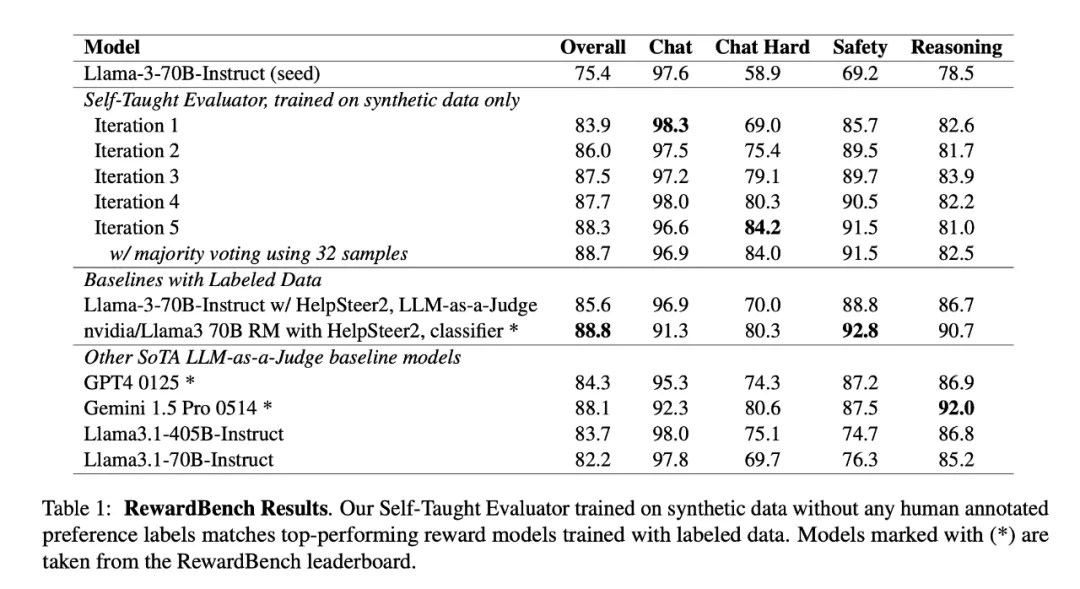
Meta 在 8 月发表了一篇题为《Self-Taught Evaluators》的论文,提出了自学习评估器,用于生成合成偏好数据来训练奖励模型,无需依赖人工标注。

同时,Meta 发布了使用直接偏好优化训练的模型。实验结果表明,在 RewardBench 上,虽然在训练数据创建中未使用任何人工标注,但其表现优于更大的模型或使用人工标注标记的模型,如 GPT-4、Llama-3.1-405B-Instruct 和 Gemini-Pro。
参考链接:
https://ai.meta.com/blog/fair-news-segment-anything-2-1-meta-spirit-lm-layer-skip-salsa-lingua/?utm_source=twitter&utm_medium=organic_social&utm_content=thread&utm_campaign=fair
文章来自于“机器之心”,作者“机器之心编辑部”。




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
