# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
明明都是人,怎么美国的博士就人手十篇AI顶会,还有五篇是一作?
最近,欧洲博士的一篇质疑,在机器学习社区火了!

他表示,自己正在欧洲大学攻读博士学位,研究方向是AI/机器学习/CV领域。
自己的博士学业为期4年。
第一年,主要就是学习怎样真正地搞研究,了解整个的学术运作机制。
第二年,自己就已经作为共同作者,在顶会CVPR上发表了首篇论文。
第三年,他已经能够管理研究项目,了解了如何申请资助,掌握了资金运作机制和其中的各种细节。
此时,他的简历中新增了两篇论文,一篇是期刊论文,一篇是会议论文,都是以一作身份发表的。
在此期间,他深度参与了产业界的事务,为和自己实验室有合作的公司写了大量跟AI、系统架构、后端、云计算、部署等相关的生产级代码。
看起来,自己应该算比较成功的博士了对不对?
然而,当他看到美国同背景的博士履历时,直接惊呆了!
他们几乎人手十篇顶会论文,全是CVPR、ICML、ICLR、NeurIPS级别的顶会,而且还有五篇是一作!

这位欧洲博士表示,自己受到相当大的冲击——
这些人究竟是怎么做到完成这么多工作,还能每年在A类期刊上发3篇论文的?他们难道不需要睡觉吗?
这位博士表示,我并不认为这些人比我聪明。
每当自己有了新idea,就会去查找是否已经有人研究过。
他时常发现,某个斯坦福或者DeepMind的博士生刚好在一个月前发表了类似的研究,这就证明自己的思路是很前沿的,并不落伍。
然而如果要深入理解这些论文中的概念,就要需要投入的努力,再加上有获取所有必要资源的过程,会耗费大量时间,绝不可能是2-3个月的项目就能搞定的。
最后,这位博士发出了心底的疑问——
我真的很困惑,这帮人是如何做到这么高效的?他们是不是有什么特殊的研究方法和资源,让他们如此迅速高产高质量研究?
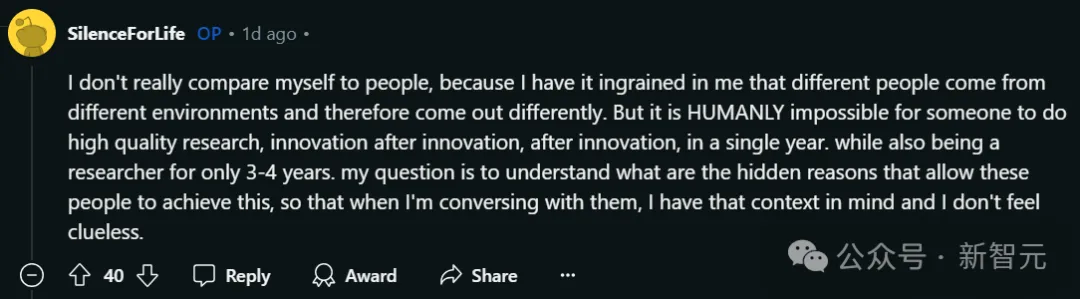
面对网友们的各种反应,他也澄清道:自己并不是喜欢拿自己和别人比较的人,因为每个人所处环境不同。
但是,对于仅有3-4年研究经验的人来说,短短一年内就源源不断地产出高质量研究和创新成果,这从人类角度来看是不可能的事!自己仿佛完全被蒙在鼓里。
背后到底有什么因素,导致了人和人之间的这种巨大差别?
有人现身说法表示,这是因为,美国大学里充满了卷王!
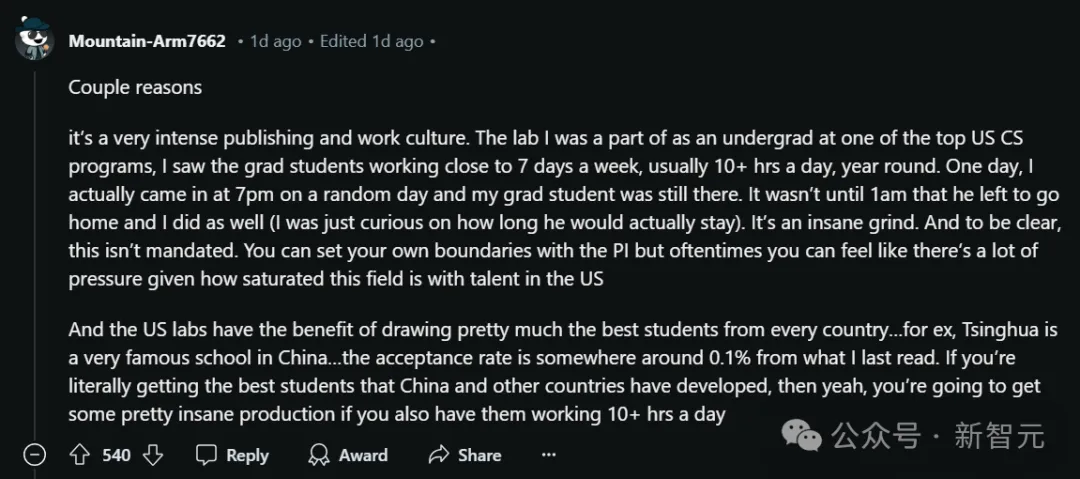
首先,美国学术界存在一种很卷的发表和工作文化。
曾在美国顶尖CS项目之一的实验室做过本科生的层主表示,自己亲眼目睹了研究生们的工作节奏——
一周七天都在工作,每天超过10小时,全年无休。
有一次,他无意中晚上7点去实验室,发现自己的研究生同学还在那里。
因为好奇他究竟会工作到多晚,层主干脆在实验室等他,结果是——直到凌晨1点,他才回家!
当然,这并非实验室的强制要求,每个人都可以和项目负责人约定自己的工作界限。
但在美国这个人才竞争如此激烈的领域,每个人都会感受到巨大的压力,没有谁能不受影响。
第二点,美国实验室的显著优势,就是吸引了来自世界各国都顶尖人才。
这里层主特意拿清华举了例子,据悉这个顶尖项目对于清华学生的录取率仅有0.1%……
如果能吸引到中国和其他国家的顶尖人才,还让他们每天工作10小时,那你很难不产生一些疯狂的成果。
总之,全球顶尖人才,汇聚在了一个高强度的工作环境里,这就造成了美国研究生惊人的学术产出。
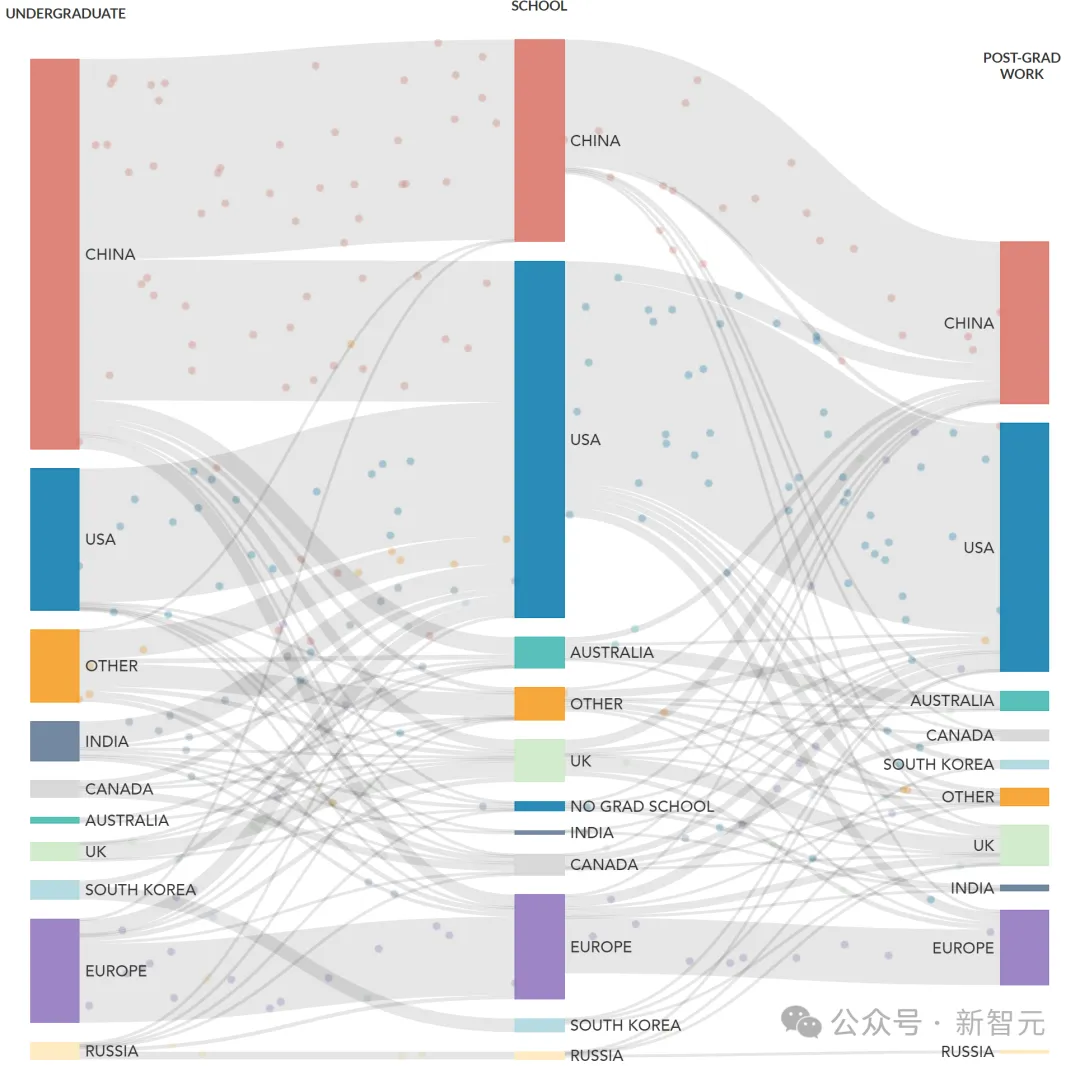
基于NeurIPS 2022被接收论文作者数据
的确,立马有人证实了他的说法。
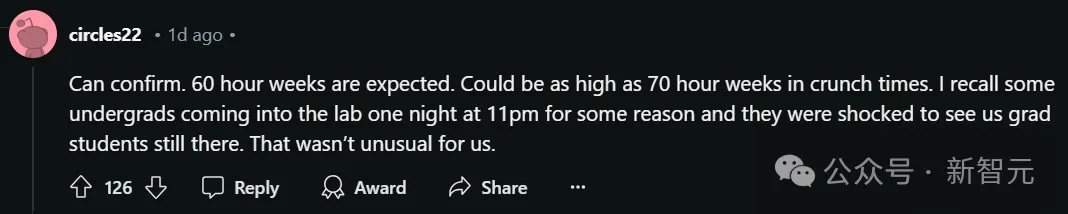
他表示,在自己的实验室,每周工作六十小时简直是家常便饭。
在紧急时期,甚至可能飙到每周七十小时。
有一次几个本科生因为在晚上十一点来到实验室。当他们看到我们这些研究生还在埋头工作时,一个个满脸震惊。但说实话,对我们来说,这种情况再平常不过了。
另一位博士说,每天工作超过10小时,7天无休是很常见的,很多博士都是这样的。
不过他也指出,研究团队的规模也是造成这种情况的一个因素。
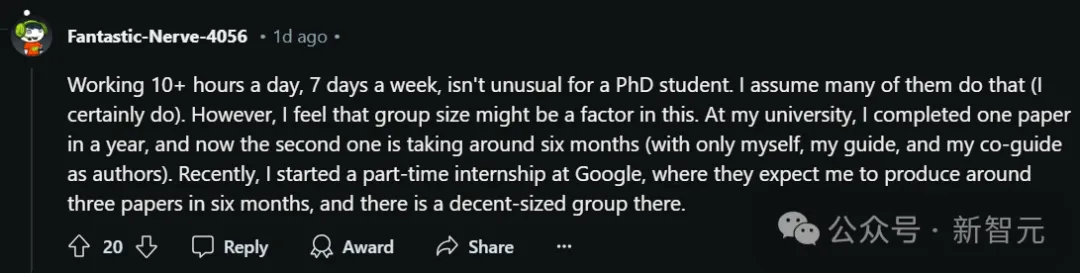
在大学里,自己花了一年时间才完成一篇论文,而第二篇论文用了6个月,作者只有自己、导师和联合导师。
但最近,当自己在谷歌兼职实习时,那里的期望是让他6个月写出三篇论文……
因为那里有一个规模不小的研究团队,所以这种要求应该是常态。
总之,简单概括就是两点原因:
1. 他们很卷,卷到不可思议。
2. 全世界最顶尖的学生都去了美国,而不是欧洲。

而且,这种情况绝不仅仅是在AI领域存在,几乎所有的STEM(科学、技术、工程和数学)领域都是如此!
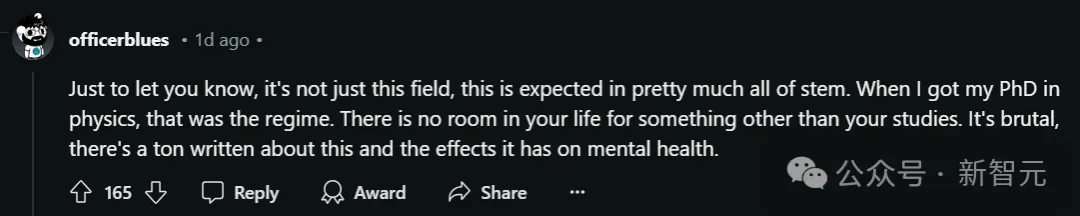
有人说,自己在读物理学博士的时候,也是这种状态:生活里根本没有除了学习以外的东西。
这种影响其实很残酷,不少在读博士的心理健康状态都不太好,已经有大量文章讨论这一现象了。
此外,帖子中还有人一语道破:大家都没提的一个重要因素,就是资源。
可能和大多数人一样,楼主也是「GPU穷人」。而那些顶尖博士项目的资源,可是有着天壤之别!
他们拥有极其昂贵的GPU集群,因此能够快速训练或微调几乎所有的模型,甚至是超过千亿参数的大模型。
这种资源优势让他们能够大幅提升迭代速度,从而开展一些对其他人来说根本无法想象的研究。

的确,即使在美国的不同高校,手握GPU的资源也差别巨大。
之前就有全美TOP 5的机器学习博士痛心发帖自曝:实验室里H100数量是0,同实验室博士之间得靠抢。

他表示在自己读博期间,计算资源是主要瓶颈。如果能有更多高性能的GPU,计算时间会显著缩短,研究进度也会快很多。

普林斯顿、哈佛这样的「GPU豪门」,手上的H100至少以三四百块打底,但是连AI教母李飞飞的斯坦福自然语言处理(NLP)小组,也只有64块A100 GPU。
在这种巨大的差异面前,出成果的速度自然也是一个天上,一个地下。
有人提到,知名机构的title,就是很有分量的隐形资产。
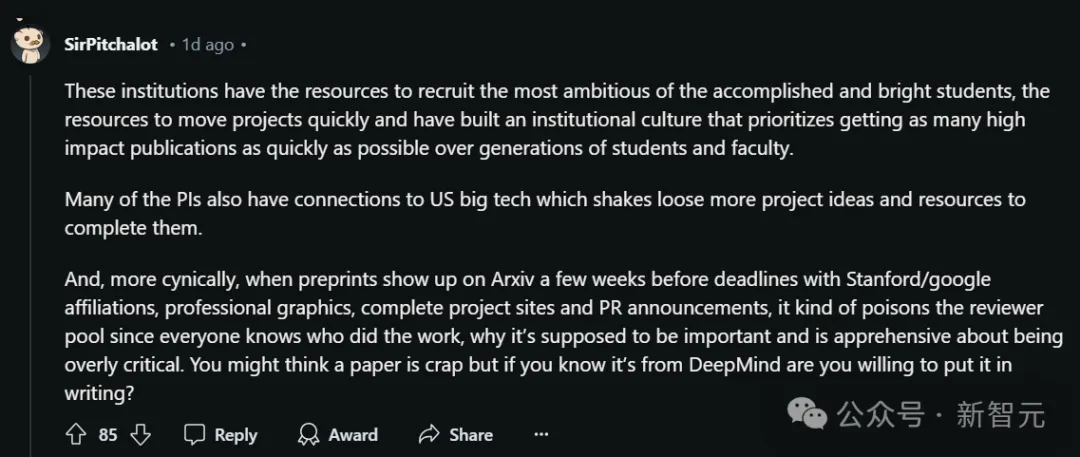
首先,很多知名机构和美国的大型科技公司保持着密切联系。
这种关系不仅会激发出创新项目的灵感,还能提供额外的资源支持。
另外,斯坦福大学或者谷歌等知名机构的title,也无形中起了很大作用。
当你看到标有这些机构的logo的预印本论文在截止日期前几周出现在arXiv上时,情况就复杂了。
这些论文,通常都配有专业的图表、完整的项目网站和精心策划的公关宣传。

这篇文章,就被大佬戏称为「PR工作的典范」
这种情况下,每个人都知道是谁的工作,为什么这项工作很重要。
你敢说审稿人不会受此影响吗?
这种情况下,他们很可能不敢给出过于严厉的批评。
即使他们认为论文质量很差,但这是DeepMind论文,谁敢在评审意见中直接开麦diss呢?
总之,这些顶尖机构拥有雄厚的资源,自然而然就吸引了最有抱负、最优秀的学生,可以快速推进各种项目。
而在这些机构中,也就培养出了一种跨越好几代学生和教师的机构文化——优先考虑如何在最短时间内,发表尽可能多的高影响力论文。
稍显安慰的是,也有人对欧洲博士表示,其实这就是幸存者偏差。
可能他关注的都是美国顶尖的机器学习项目,他们的成果自然也是世界一流的。
但如果去了解一下普通大学里博士生的情况,就会发现他们作为一作在顶会上发论文的情况并不常见。

当然也有不那么成功,或者干脆转行了的人。
有些人可能费了老劲也就发表了一篇论文,然而选择去私营企业上班,不混学术圈了。

有人对这位博士表示,你所观察到的样本,并不具有统计学意义上的随机性和代表性。
被偶然看到的美国博士生的论文或简历,几乎可以肯定地说,代表了学术成就分布中最为top的那一波。
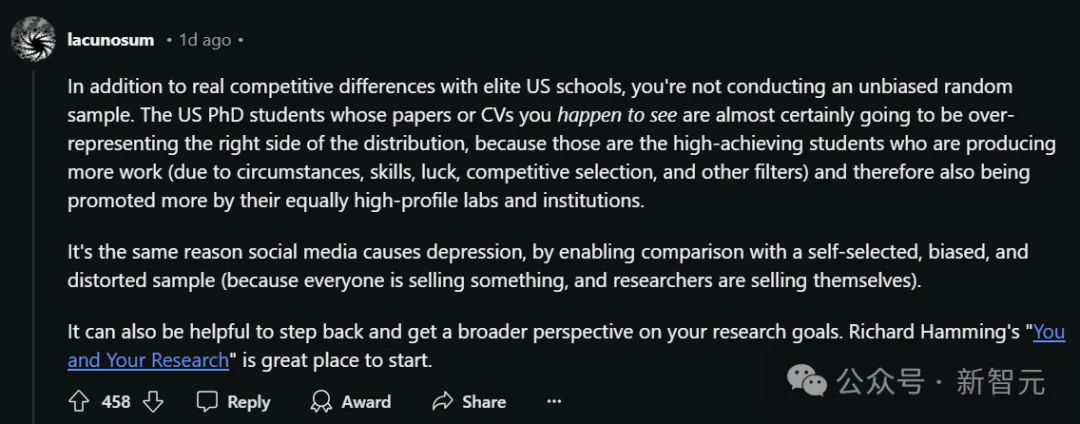
这些高产出的学生,往往会被他们所在的知名实验室和机构更多地推广。他们的成功可能源于良好的科研环境、出色的个人能力、一定的运气成分、严格的竞争性选拔以及其他因素。
其实这就类似于社交媒体会导致人们焦虑和抑郁。
在社交平台上,人们倾向于展示自己最好的一面,这导致我们常常将自己与一个经过筛选、存在偏差且被美化过的样本进行比较。
在学术界也是如此,每个研究者都在某种程度上「推销」自己的研究成果,而那些最引人注目的成果,自然会得到更多关注。
在这种情况下,退一步、获得更广阔的研究视角,会很有帮助。他强烈推荐这位博士去读一下阅读Richard Hamming的经典演讲稿「你和你的研究」(You and Your Research)。

也有人指出,虽然楼主的描述有些夸大了,但的确存在一个临界点,超过这个点之后,单纯增加数量和投入时间并不能等同于提高质量。

参考资料:
https://www.reddit.com/r/MachineLearning/comments/1g7dzkp/d_why_do_phd_students_in_the_us_seem_like/
文章来自于“新智元”,作者“Aeneas 好困”。




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
