# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Maitrix.org 是由 UC San Diego, John Hopkins University, CMU, MBZUAI 等学术机构学者组成的开源组织,致力于发展大语言模型 (LLM)、世界模型 (World Model)、智能体模型 (Agent Model) 的技术以构建 AI 驱动的现实。Maitrix.org 此前成功开发了 Pandora 视频-语言世界模型、LLM Reasoners,以及 MMToM-QA 评测(ACL 2024 Outstanding Paper Award)。
研究者们已经并陆续构建了成千上万的大规模语言模型(LLM),这些模型的各项能力(如推理和生成)也越来越强。因此,在多样的应用场景中对其进行性能基准测试已成为了一项重大挑战。目前最受欢迎的基准测试是 Chatbot Arena,它通过收集用户对模型输出的偏好来对 LLM 进行综合排名。然而,随着 LLM 逐渐落地于众多应用场景,无论是针对工业生产目标,还是科学场景辅助需求,评估 LLM 在精细化维度上的能力都是至关重要的,例如:
如此大规模且精细化(甚至定制化)的评估对于依赖于人群众包的 Chatbot Arena 或类似的基准测试来说是一大挑战 —— 在成百上千个维度上为数千对模型(或数万对模型)收集足够的用户投票是不切实际的。此外,由于人类查询和投票过程存在噪声以及个人主观因素,评估结果往往难以复现。
最近,研究者们还探索了其他的自动评估方案,通过选择一个(或几个)“最强” 模型(通常是 GPT-4)作为评委来评估所有其他模型。然而,评委模型可能存在偏见,例如更倾向于选择与其自身风格相似的输出。基于这种评估进行模型优化可能会导致所有模型过度拟合 GPT-4 的偏见。
为了结合这两种方案的优势,通过利用 “群体智能”(Chatbot Arena 依赖于人群智慧)来实现更稳健且更少偏见的评估,同时使该过程自动化且可扩展到多维度能力比较,Maitrix.org 发布了 Decentralized Arena。

图 1 展示了这些基准测试范式之间的主要区别。Decentralized Arena 的核心理念是利用所有 LLM 的集体智能进行相互评估和比较。这形成了一个去中心化、民主化的系统,在该系统中,所有被评估的 LLM 同时也是能够评估其他模型的评审者,与依赖于中心化的 “权威” 模型作为评审相比,Decentralized Arena 能够实现更公平的排名。
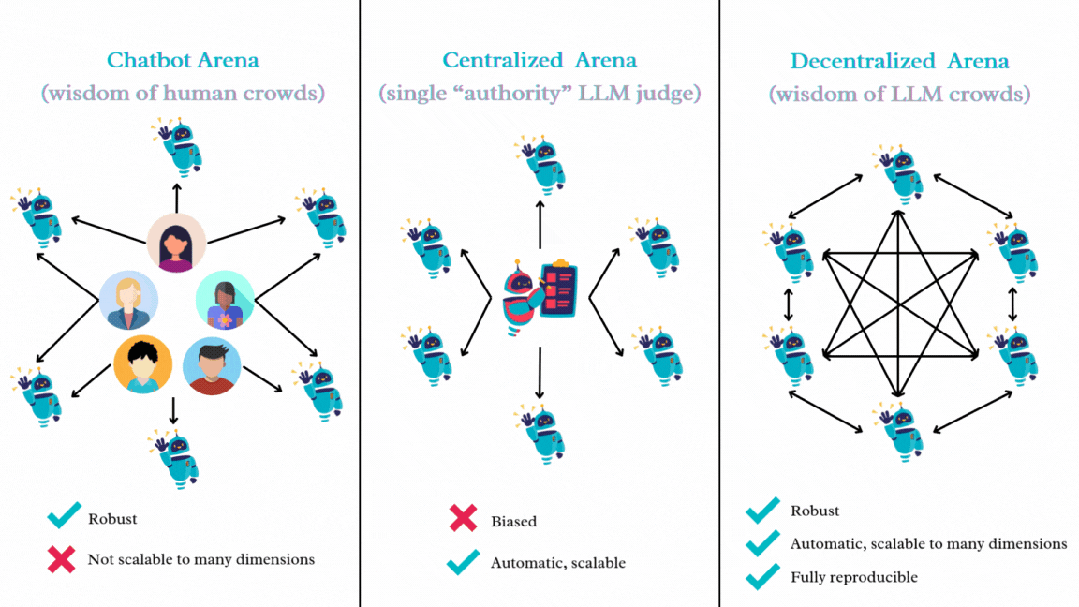
图 1:Open-ended 场景下 LLM 评估的不同范式,Decentralized Arena 结合了两者的优点,即去中心化与自动化。
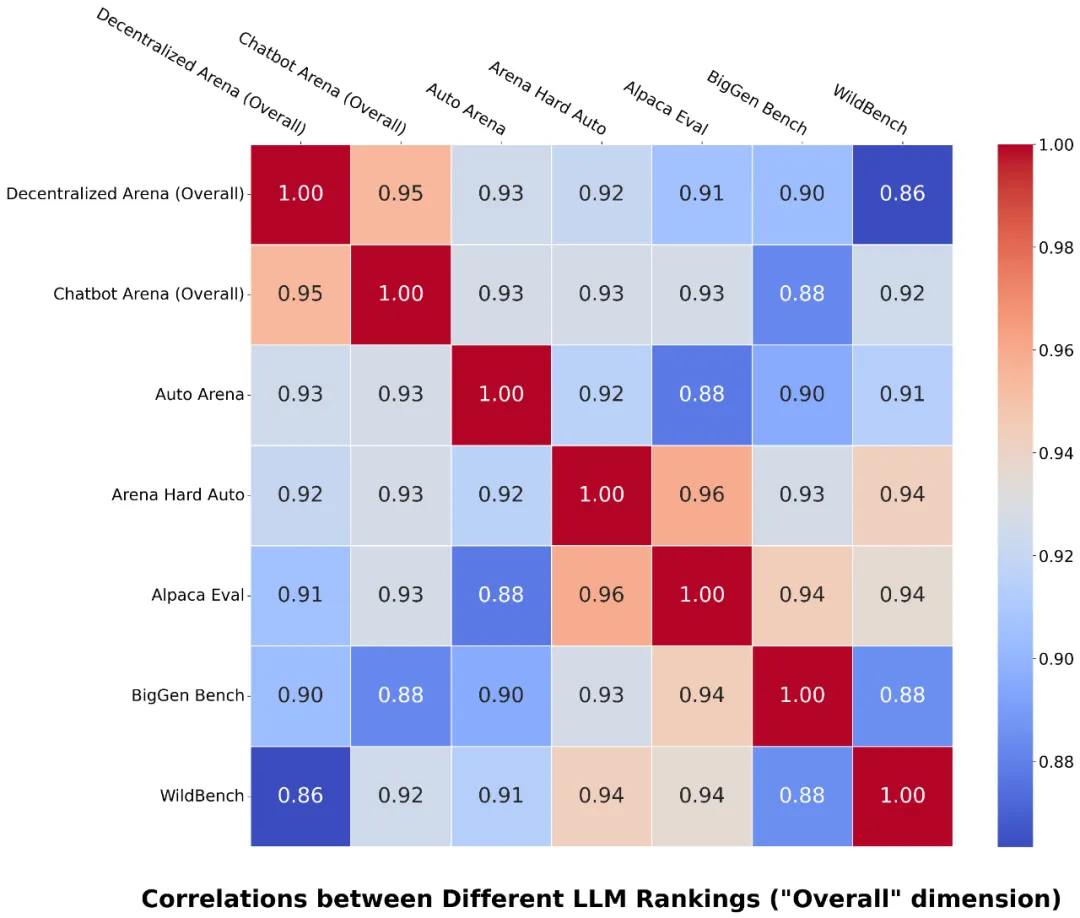
图 2:Decentralized Arena 与 Chatbot Arena 的 “整体” 排名表现出最强的相关性。
Decentralized Arena 的关键优势包括:
图 3 展示了最终排行榜的截图。研究团队正在继续添加更多的模型和维度,欢迎来自社区的贡献和提交!
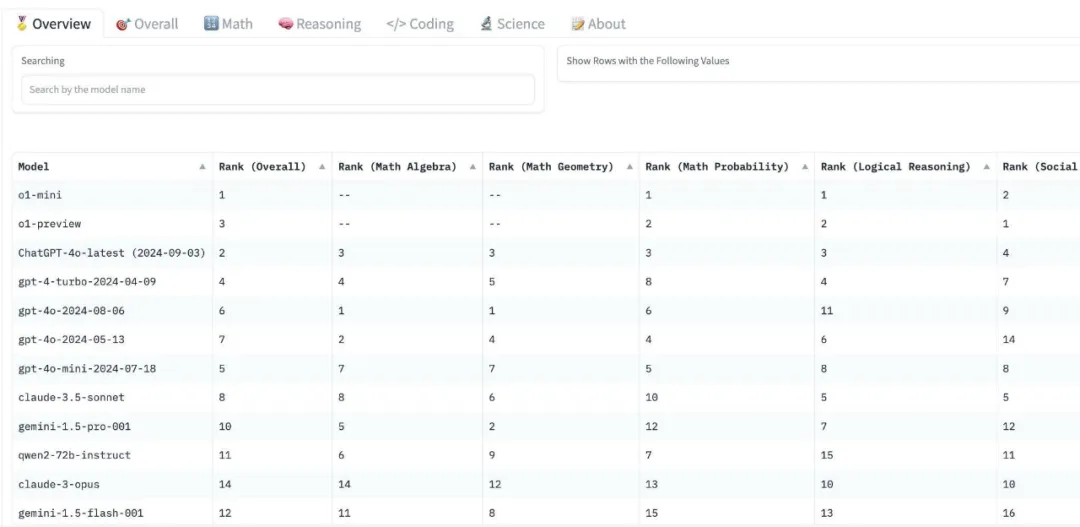
图 3:Decentralized Arena 排行榜,包括不同维度的排名。
去中心化的概念是通过让所有 LLM 充当评审,对每一对模型(即决定哪个模型的输出 “获胜”,类似于 Chatbot Arena 中的人类评审)进行投票。一个简单的做法是让每个模型对所有其他模型对进行投票,其复杂度为 O (n^3*k),其中 n 是模型数量,k 是查询数量。当 n 和 k 都很大时,这种方法的速度会非常慢。因此,研究团队设计了一种基于增量排名、二分搜索插入和由粗到精调整的更高效的方法。
该研究从一小组 “种子” 模型(例如 15 个)开始,利用上述简单方法迅速对它们进行排名。然后,其他模型一个接一个地通过粗筛和精排的步骤被增量插入到排名列表中。排名列表中的所有模型都将作为评审帮助新模型找到其位置。视频 1 说明了这一过程。
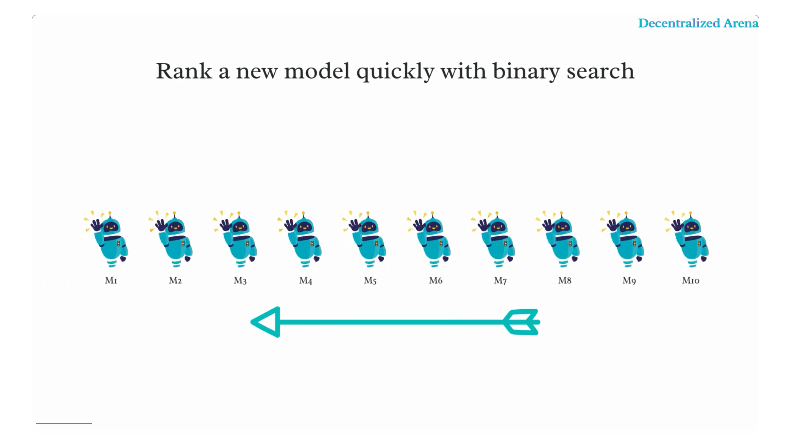
视频 1: 演示大语言模型插入过程。
在上述排名过程中,该研究收集了模型的成对比较结果,然后使用 Bradley-Terry (BT) 方法来估计每个模型在排名中的得分。这些得分用于在模型作为评审时赋予它们不同的权重 —— 得分较高的模型在评估其他模型对时影响更大(该研究还使用了其他简单的加权方法,例如基于模型排名的线性递减权重,这将在即将发布的技术报告中进一步讨论)。这些得分在整个排名过程中会自动调整,最终得分在排名完成时确定。
去中心化评估系统的一个关键优势是,随着更多模型的参与,排名将变得更加稳定,如图 4。
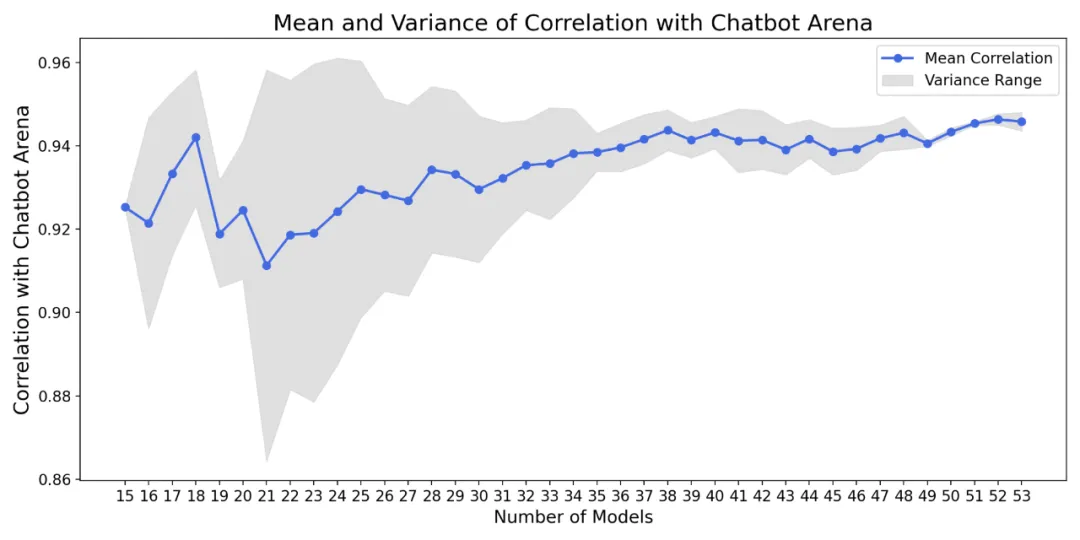
图 4: 随着模型数量的增加,排名中的方差(阴影区域)逐渐减小,表明排名变得越来越稳健。
通过将上述自动化评估方法应用于多个评估维度,以获得流行 LLM 的精细排名 (参见排行榜页面)。
该方法与依赖大量人工评审的 Chatbot Arena 取得了高度的相关性(“整体” 维度的相关性为 95%)。图 2 和图 5 展示了这些相关性,表明 Decentralized Arena 优于其他流行的基准测试,并展示了不同维度的排名之间的关系。
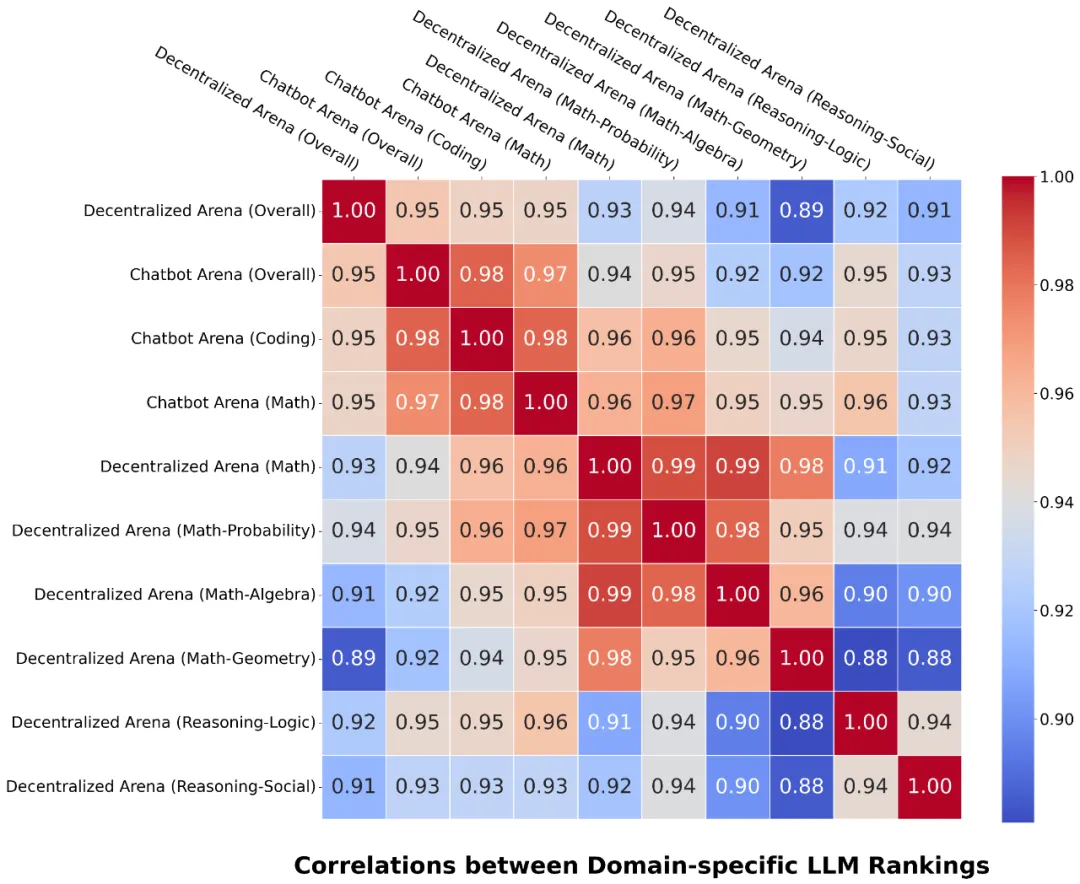
图 5: 不同维度排名之间的相关性 (底部)。
Decentralized Arena 的另一个关键优势是其可扩展性,以便于增加任意新评估维度对 LLM 进行基准测试。用户可以轻松地为自己关心的新维度创建排名。作为演示,该研究为数学、推理、科学和编程等多个维度创建了维度排名 (排行榜)。
要为新维度建立排名,需要为该维度准备一组问题集,然后在此问题集上对 LLM 进行比较。对于某一新维度(例如数学 - 代数),需要先从各种相关的开源数据集中提取并合并了一个大型初始问题集,然后进一步从中抽取少量核心问题以实现高效排名。最简单的方法是从初始问题集中随机抽取问题,其抽取的问题越多,最终排名就越稳定。
为了在较少的问题集下获得稳定的排名(从而提高排名效率),该研究还设计了一种新的自动问题集选择的方法,如图 6 所示。其核心思路是利用 LLM 的群体智能选择出能够在一小组 LLM 上产生一致排名的问题集,研究团队将在即将发布的技术报告中介绍更多细节。
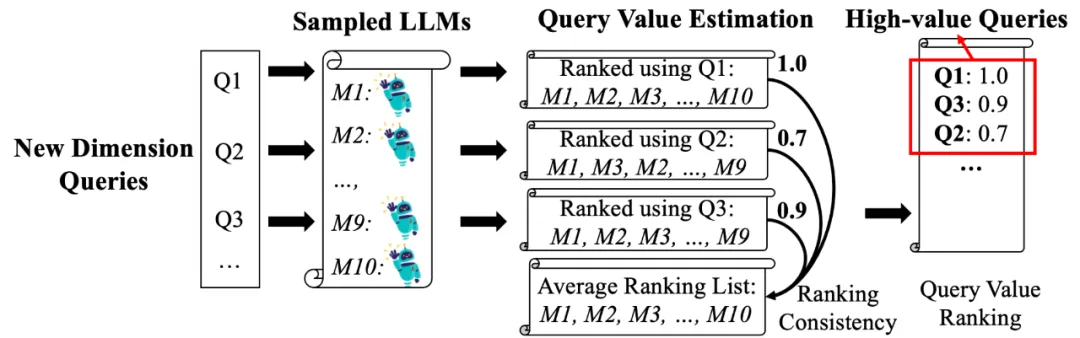
图 6: 新维度的自动查询选择。
图 7 显示,其查询选择方法比随机查询抽样产生了更好且更一致的排名。
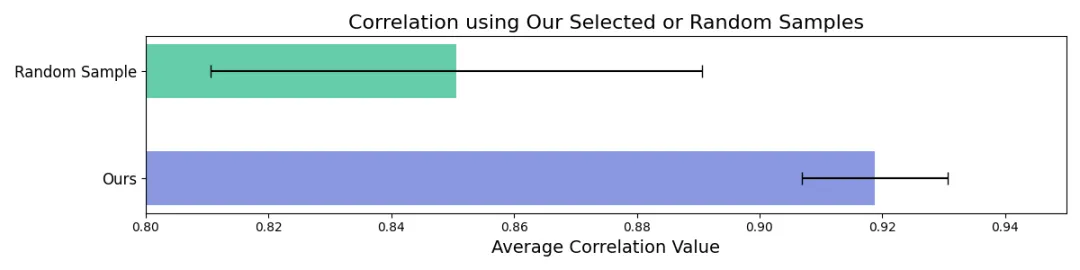
图 7: 使用其方法选择的问题集比随机抽样的问题集实现了更高的相关性和更低的方差。
该研究做了更多的分析来以深入理解 Decentralized Arena 的结果。
图 8 展示了排名中 LLM 的得分及其置信区间。
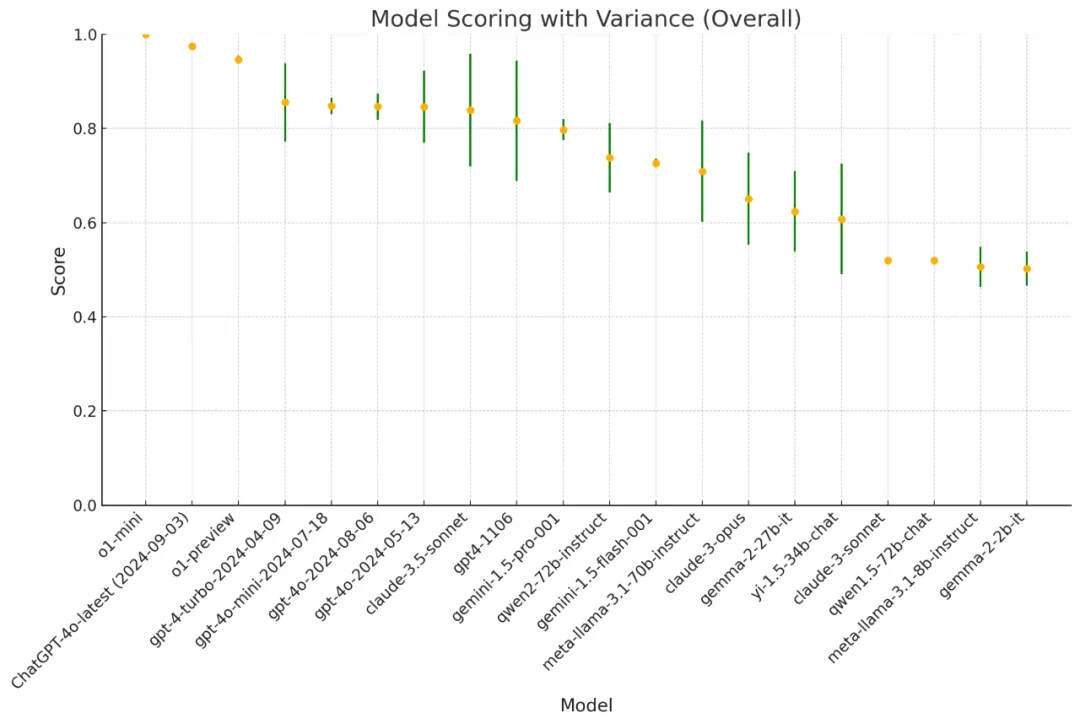
图 8: LLM 的得分和置信区间。
该研究对排名过程中每一对 LLM 的胜率和比较次数分布进行了可视化处理(“Overall” 维度)。
如图 9 和图 10 所示,LLM 的群体智能自动集中在难以区分的邻近 LLM 对上(在图 10 中靠近对角线的模型,或在图 9 中胜率接近 50% 的模型)。相比之下,性能差距较大的 LLM 之间的比较较为稀少(甚至被省略),从而降低了整体计算成本。
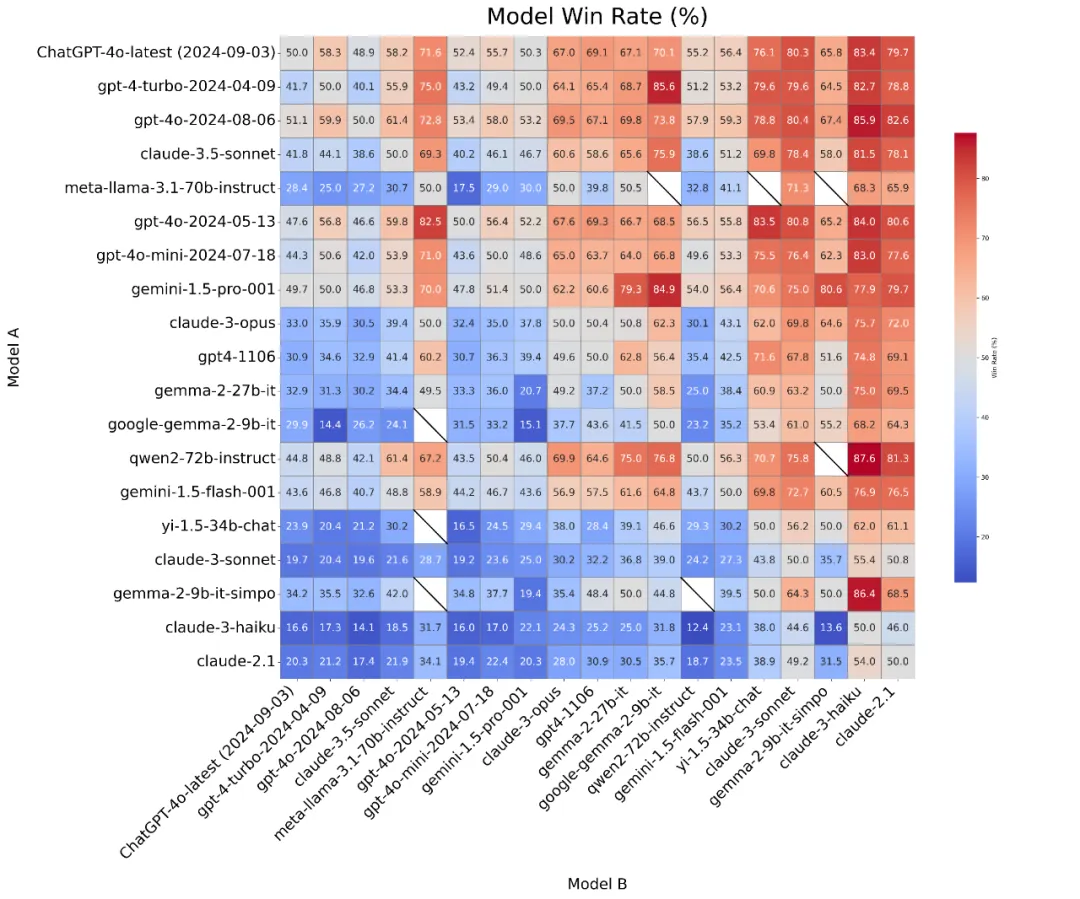
图 9: 胜率分布图。
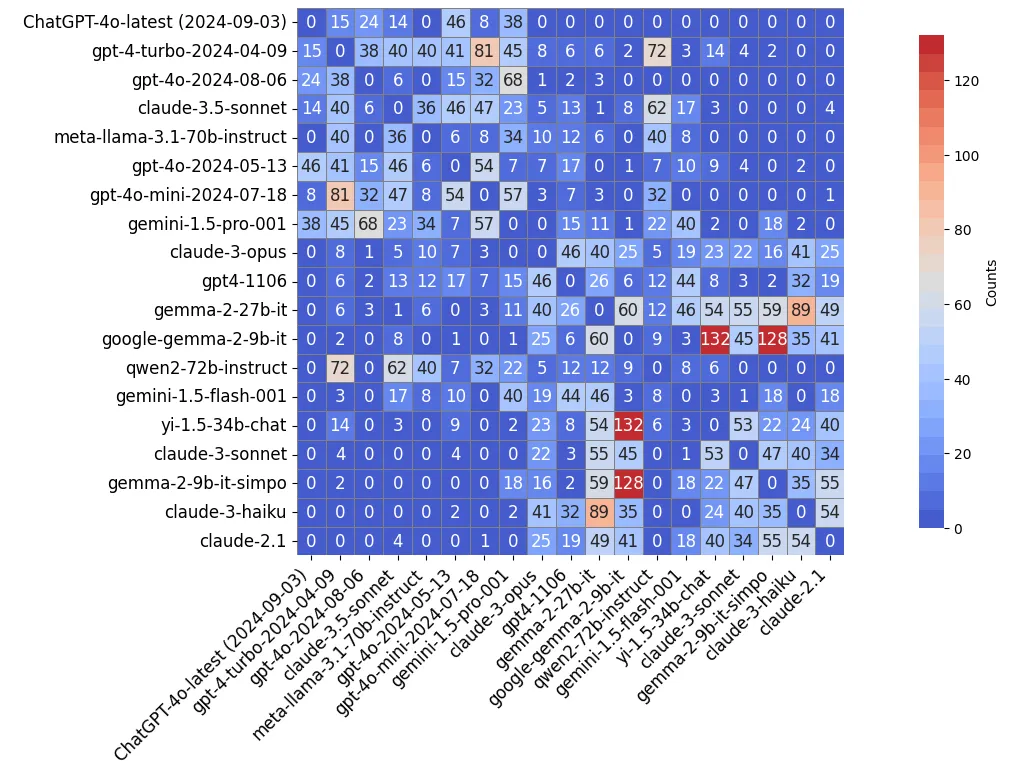
图 10: 对比次数分布图。
文章来自于微信公众号“机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
