# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“这是我听过的黄仁勋最好的采访!”
英伟达CEO黄仁勋的一场炉边谈话再次引起热议:
英伟达从来没有一天谈论过市场份额。
我们所讨论的只是:如何创造下一个东西?如何将过去需要一年才能完成的飞轮缩短到一个月?

面对Azure和AWS等正在自主构建ASIC芯片的云计算大客户,老黄打了个比喻:
公司受到鱼塘大小的限制,唯一的目标是用想象力扩大鱼塘。(指创造新市场)
当然了,除了提及英伟达,老黄还讨论了AGI的智能扩展、机器学习的加速、推理与训练的重要性……

虽然时长感人(近1个半小时),但一大波网友已经看完并交起了作业(开始卷了是吧!)
网友:学起来!学起来!
鉴于视频较长,量子位先直接给大家划重点了,老黄的主要观点包括(省流版):

(以下为重点部分整理)
Q:关于个人AI助理的发展前景,您认为我们何时能在口袋里装上一个无所不知的AI助理?
A:很快就会以某种形式出现。这个助理一开始可能不够完美,但会随着时间推移不断改进,这是技术发展的必然规律。
Q:目前AI领域的发展变化速度是否是您见过最快的?
A:是的,这是因为我们重新发明了计算。在过去10年里,我们将计算的边际成本降低了10万倍,而按照摩尔定律可能只能降低100倍。
我们通过以下方式实现了这一点:
这种快速发展使我们从人工编程转向了机器学习,整个技术栈都在快速创新和进步。
Q:模型规模扩展方面有哪些变化?
A:以前我们主要关注预训练模型的扩展(重点在模型大小和数据规模),这使得所需计算能力每年增加4倍。
现在我们看到后训练(post-training)和推理阶段也在扩展。人类的思维过程不可能是一次性完成的,而是需要快思维、慢思维、推理、反思、迭代和模拟等多个环节。
而且,以前人们认为预训练难,推理简单,但现在都很难了。

Q:与3-4年前相比,您认为NVIDIA今天的优势是更大还是更小?
A:实际上更大了。过去人们认为芯片设计就是追求更多的FLOPS和性能指标,这种想法已经过时。
现在的关键在于整个机器学习系统的数据流水线(flywheel),因为机器学习不仅仅是软件编程,而是涉及整个数据处理流程。从一开始的数据管理就需要AI参与。数据的收集、整理、训练前的准备等每个环节都很复杂,需要大量处理工作。
Q:与Intel等公司相比,Nvidia在芯片制造和设计方面有什么不同的策略?
A:Intel的优势在于制造和设计更快的x86串行处理芯片,而Nvidia采取不同策略:
Q:关于定制ASIC(如Meta的推理加速器、亚马逊的Trainium、Google的TPU)以及供应短缺的情况,这些是否会改变与NVIDIA的合作动态?
A:这些都是在做不同的事情。NVIDIA致力于为这个新的机器学习、生成式AI和智能Agent世界构建计算平台。
在过去60年里,我们重新发明了整个计算技术栈,从编程方式到处理器架构,从软件应用到人工智能,每个层面都发生了变革。我们的目标是创建一个随处可用的计算平台。
Q:NVIDIA作为一家公司的核心目的是什么?
A:构建一个无处不在的架构平台。我们不是在争夺市场份额,而是在创造市场。我们专注于创新和解决下一个问题,让技术进步的速度更快。
Q:NVIDIA对待竞争对手和合作伙伴的态度是什么?
A:我们对竞争很清醒,但这不会改变我们的使命。我们向AWS、Azure等合作伙伴提前分享路线图,保持透明,即使他们在开发自己的芯片。对于开发者和AI初创公司,我们提供CUDA作为统一入口。

Q:对OpenAI的看法如何?如何看待它的崛起?
A: OpenAI是我们这个时代最重要的公司之一。虽然AGI的具体定义和时间点并不是最重要的,但AI能力的发展路线图将会非常壮观。从生物学家到气候研究者,从游戏设计师到制造工程师,AI已经在革新各个领域的工作方式。
我非常欣赏OpenAI推进这一领域的速度和决心,并为可以资助下一代模型感到高兴。
Q:您认为模型层是否正在走向商品化,以及这对模型公司的影响是什么?
A:模型层正在商品化,Llama的出现使得构建模型变得更加便宜。这将导致模型公司的整合,只有那些拥有经济引擎并能够持续投资的公司才能生存。
Q:您如何看待AI模型的未来,以及模型与人工智能之间的区别?
A:模型是人工智能必不可少的组成部分,但人工智能是一种能力,需要应用于不同的领域。我们将看到模型层的发展,但更重要的是人工智能如何应用于各种不同的应用场景。
Q:您如何看待X公司,以及他们建立大型超级集群的成就?
A:他们在19天内(通常需要3年)建造了一个拥有100,000个GPU的超级计算机集群。这展示了我们的平台的力量,以及我们能够将整个生态系统集成在一起的能力。
Q:是否认为分布式计算和推理扩展将会发展到更大规模?
A:是的,我对此非常热情和乐观。推理时计算作为一个全新的智能扩展向量,与仅仅构建更大的模型截然不同。
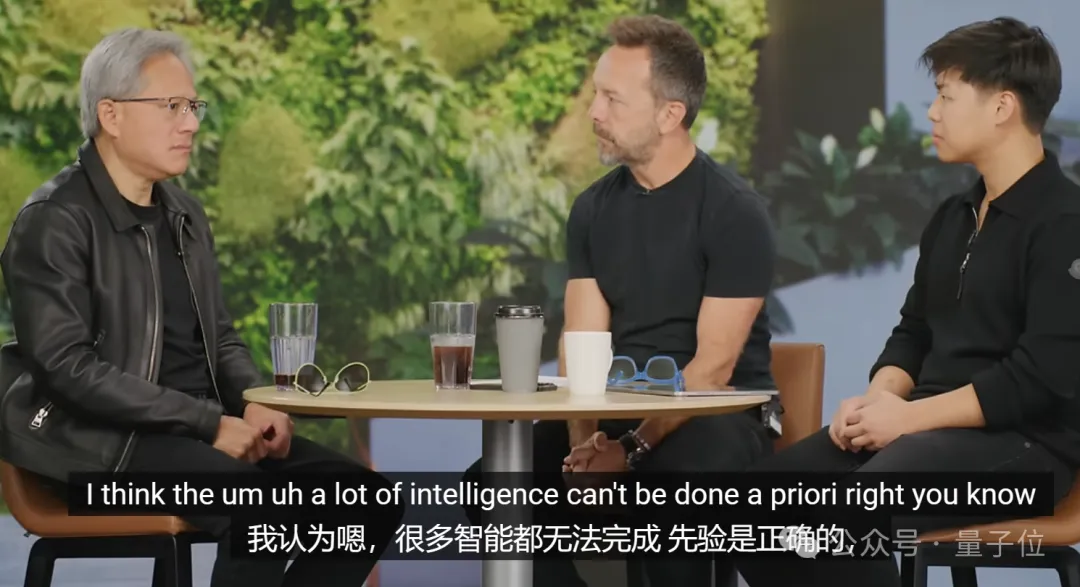
Q:在人工智能中,是否很多事情只能在运行时完成?
A:是的,很多智能工作不能先验地完成,很多事情需要在运行时完成。
Q:您如何看待人工智能的安全性?
A:我们必须构建安全的人工智能,并为此需要与政府机构合作。我们已经在建立许多系统来确保人工智能的安全性,并需要确保人工智能对人类是有益的。
Q:你们公司超过40%的收入来自推理,推理的重要性是否因为推理链而大大增加?
A:没错,推理链让推理的能力提高了十亿倍,这是我们正在经历的工业革命。未来推理的增长将远大于训练的增长。
Q:你们如何看待开源和闭源人工智能模型的未来?
A:开源和闭源模型都将存在,它们对于不同的行业和应用都是必要的。开源模型有助于激活多个行业,而闭源模型则是经济模型创新的引擎。
参考链接:
[1]https://x.com/StartupArchive_/status/1848693280948818070
[2]https://www.youtube.com/watch?v=bUrCR4jQQg8
文章来自于“量子位”,作者“一水”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
