# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

红杉资本的David Cahn关于AI大模型的收支缺口给出了一个模型,其结论是AI大模型泡沫即将到达顶点。
David Cahn的模型很简单:英伟达DC GPU的年化收入是1500亿美元,AIDC总成本是GPU的2倍,那么AIDC年化成本是3000亿美元;AI收入其它费用率50%,那么AI收入必须要达到AIDC年化成本的2倍,即6000亿美元,AI大模型的整体收支才可平衡。
收入端,OpenAI目前的年化40亿美元收入已是唯一的遥遥领先者,Google, Microsoft, Apple与Meta作为收入第二梯队,Oracle, ByteDance, Alibaba, Tencent, X与Tesla作为收入第三梯队,以及把其它AI大模型公司收入都算上,全球AI收入也就1000亿美元。
全球对AI大模型投入所隐含要求的收入是6000亿美元,实际收入仅1000亿美元,存在5000亿美元的收支缺口。5000亿美元的收支缺口能继续撑多久,AI大模型泡沫则能撑多久,收支缺口支撑不住,则AI大模型泡沫破灭。
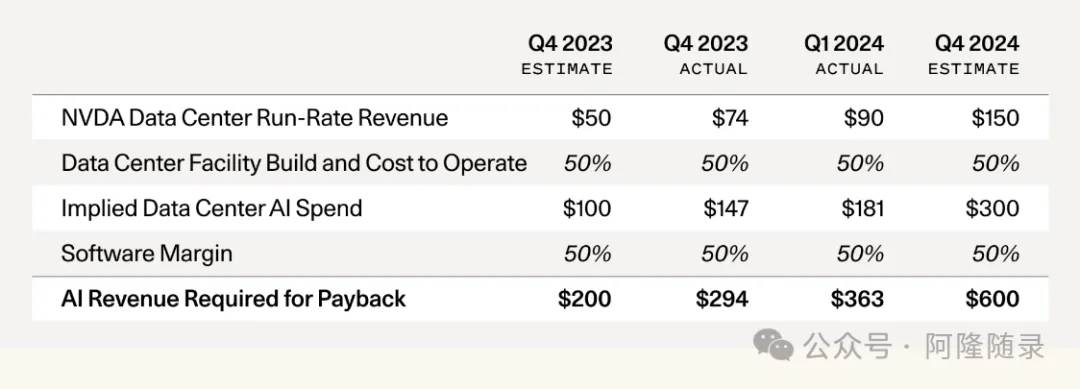
David Cahn模型是“收入减去opex后要覆盖capex”,capex是投资项,并不是成本项,例如,中国移动的模型,中国移动建设5G网络时的capex会特别高,但电信运营商并不会短期关注“收入减去opex后要覆盖capex”,因为来自折旧的成本项变化并不大。但是,中国移动的capex在5G网络建设峰值后会迅速下降,capex长期累加总体上还是等于成本项长期累加,所以,对于AI那样capex持续升高而没有周期的情况,David Cahn模型使用“收入减去opex后要覆盖capex”来分析收支缺口还是有说服力的。
David Cahn模型实际上就是一个“从Nvidia到OpenAI”的模型,用Nvidia收入的4倍去比较OpenAI们的收入。AI大模型的收支缺口5000亿,其实就是在说“OpenAI们的收入实在太少了”以及“Nvidia赚得实在太多了”。
这里不直接评论关于“AI大模型泡沫破灭”的问题,只对David Cahn模型评论几点:
第一,David Cahn模型目前看不到改善的迹象。
如果仔细分析OpenAI的财务模型,OpenAI的收入指数增长,推理费用和训练费用实际上也是指数增长,只是收入的指数更大一点而已。整个AI行业,能够收入指数增长的是凤毛麟角,绝大多数大模型AI企业只是在为GPU企业贡献收入而已。
随着Nvidia性价比更高的下一代GPU芯片B100推出,AI公司收入端整体并不会剧变,但GPU capex端会激增,这会进一步放大David Cahn模型的缺口。
所以,David Cahn模型所显示的收支缺口还会持续并进一步扩大,5000亿缺口的模型是David Cahn在2024年6月提出,David Cahn如果在2025年再更新模型,缺口会接近10000亿美元。
第二,GPU是特殊的capex,囤积GPU算力非常危险。
David Cahn模型与中国移动模型有本质区别,中国移动建设5G网络的capex保值能力较好,因为5G网络并不会短期内就被6G网络替代,等到6G网络capex峰值出现时,5G网络capex已经折旧完毕。
但是,符合摩尔定律的GPU的capex则非常危险,GPU不断加速升级,则意味着原有GPU投资加速贬值,David Cahn模型的capex不断快速提高事实上就包含了这一因素。GPU capex必须和AI公司的运营紧密匹配,投入capex时就要有产出的把握,出于囤积目的的GPU capex在未来会非常危险。
第三,Scaling law让英伟达伟大,但Scaling law本身面临转折。
David Cahn模型里,在收入巨大缺口的情况下,AIDC成本的每年3000亿是实实在在花掉的,其中英伟达实实在在赚取了1500亿,这个“赚钱奇迹”背后是摩尔定律与Scaling law的共振。
当前,预训练的Scaling law趋势已经转折,Scaling law本身也面临着范式转换。Scaling law是不是继续存在?如果继续存在,新的Scaling law会是什么形式?这个底层问题会更快更直接地决定英伟达的未来。

文章来自于微信公众号“阿隆随录”,作者“阿隆随录”




