# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前几天那个AI应用爆炸之夜,除了Claude、Genmo、Ideogram 等等一群明星AI应用发布更新之外,Runway其实也发布了一个很酷的功能,只是被淹没在了信息的大爆炸里。
这个功能,叫Act-One。
简单的说,就是你可以上传一段人物表演视频,来驱动一个角色跟你做一样的面部表情。
我直接放一段视频,你们就明白是什么效果了。

把AI视频的人物表演的可控性,直接提升了一大步。
在传统的没有AI的过去,如果你想做这种动画视频,那复杂度是不可想象的。
我给大家大概三种方式的工作量的对比。
第一种是传统动画中,动画师去手K角色的表演。就是在模型上,人物一点点做,做200分钟左右的动画,其中人的部分,大概要7、8个动画师,徒手做半年。
第二种就是动捕。大概录制时间是2~3天,把所有的表演存下来,然后再花大概一个月的时候做优化和细节清理,就可以得到一个很牛逼的效果。
而整套动捕的工作流和设备,也是相当的复杂。
比如《死亡搁浅》里面,拔叔饰演的昂格尔,就全是动捕做的。
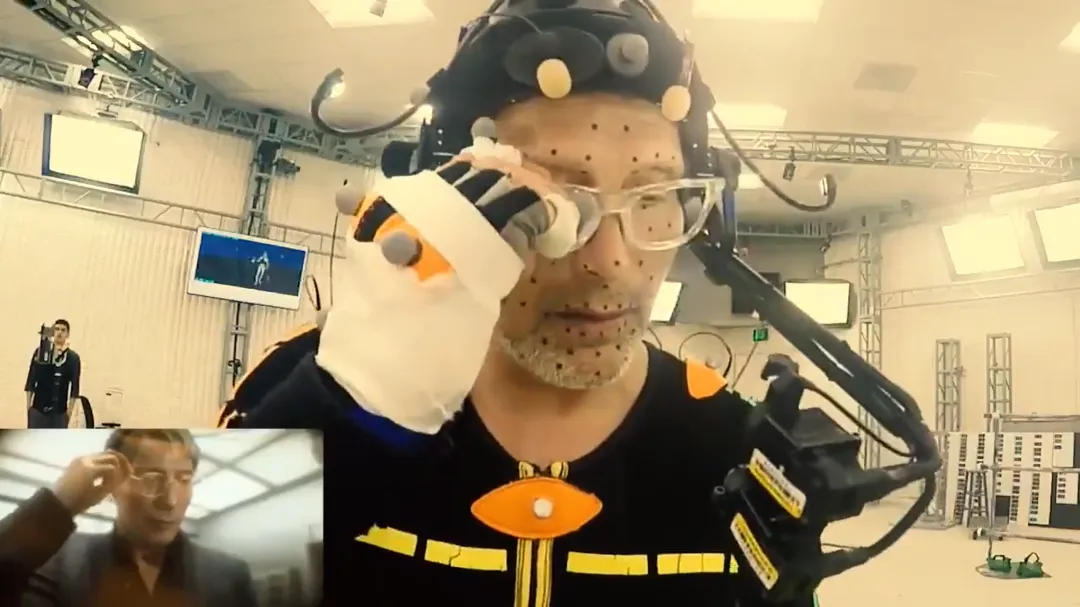
可以看到拔叔带着一整套面部动捕设备,脸上还有很多的黑点,这些黑点就是标记点,记录面部肌肉的运动,面前有摄像机阵列,大概就是通过捕捉标记点的运动和面部肌肉的变化,将这些表情信息转化成3D模型的数据,以驱动动画角色有更细腻的表演。
这里说个有趣的小东西,就是脸部的标记点其实也不一定是黑的,而是有反差就行,比如白人是黑点,黑人就是白点。。。

而且这套动捕设备很贵,动不动就是几十万美金,你信息采集完了还不能直接用,还得绑定、清理等等以后,才算Ok。
但是就这,也比传统的动画师手K要好多了。
而现在,有了AI之后呢?
以Runway这个Act-One为例,你传一张图,一个视频上去。
1分半钟,一段视频就生成完了。
就是这么快。
周末,我也终于拿到了Act-One的权限,好好测试了一波。
可以进入Runway的首页:https://app.runwayml.com/
如果你被推送到了的话,你就能看到一个巨大的Banner,Act-One。

点Try进去,你就能看到Act-One的界面,非常的简洁易懂。
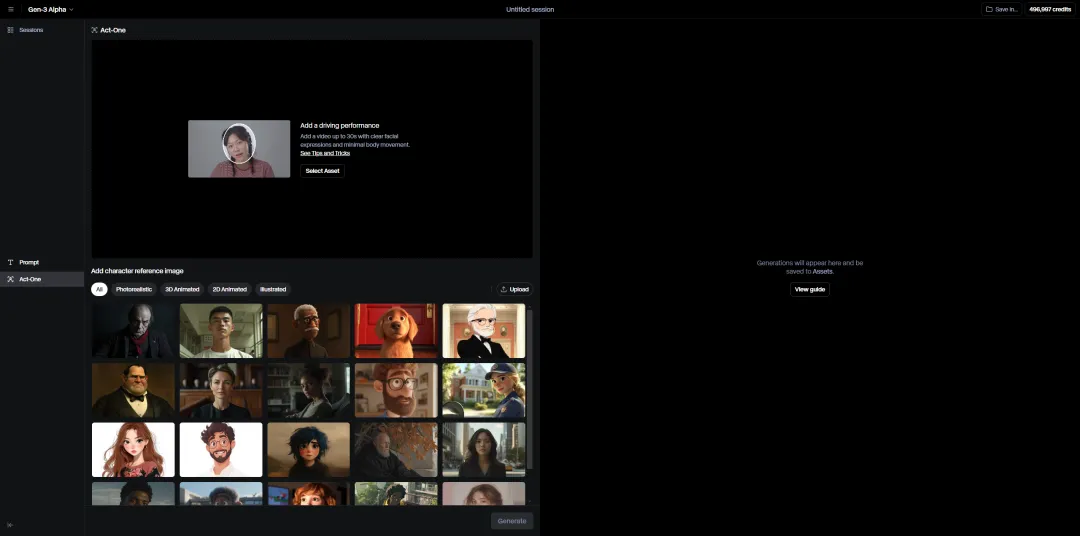
上面是你要上传的视频,下面是你要上传的角色,Runway为了给大家快速上手玩,也放了一堆默认的角色。
比如有一个很经典的视频,就是那个:“我信你个鬼,你这个糟老头子坏得很”。这个动态幅度还挺大的,我们来试试。

我们直接把这个视频,传到Runway里面去,再随便挑个角色。
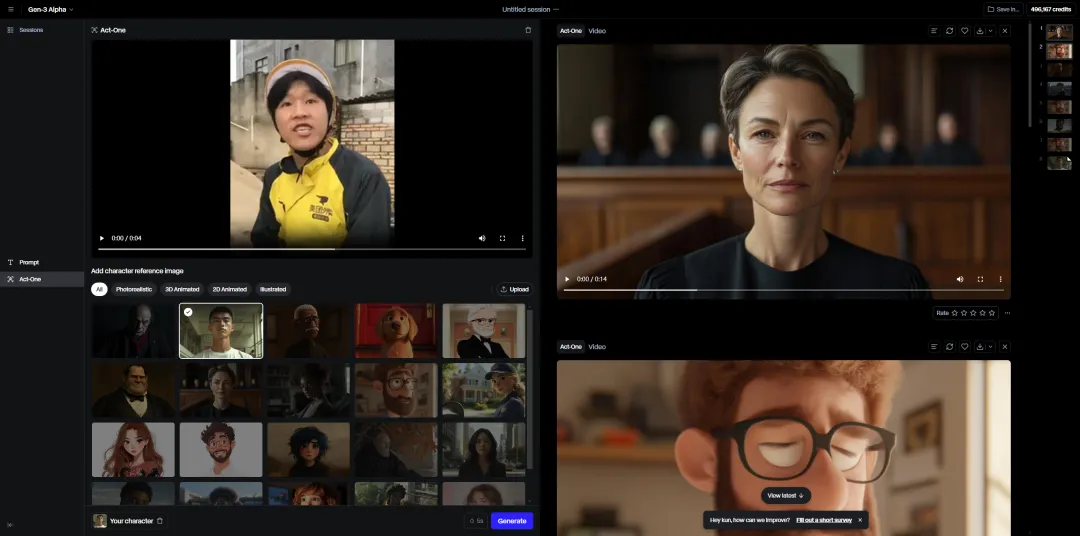
直接开跑就行。
大概1分多钟,这一段视频就跑完了,看看效果。

天秀,过于稳定了。
还原除了神韵,脸部的肌肉表情也复刻的很到位,更是看不出来一丁点闪动现象,稳定的不像是AI的视频。
再来一个超级复杂的表情,之前我在B站上看到这个惊为天人。

她的脸会跳舞,这表情丰富度,这控制力,过于可怕了。。
我们把这个视频,让Runway的Act-One再试试。

说实话,没有原来视频那种非人类的细节控制力,特别微表情和瞳孔的细节,是但是大部分的节奏和动态,都模仿到位了。在我看来,已经很棒了。
还有那个经典的老爷爷nice的魔性片段。

可以看到,当你的头部和表情幅度大的时候,表现是更好的。
Runway的Act-One,还是太强了。
其实表情迁移,Runway不是第一个做的。前有Viggle,后有快手的LivePortrait。但是基本都有个共同点,就是画面不稳。
Viggle比较屌的点是可以迁移更多的头部和身体动作,但是会有一些闪烁,有些细节会比较糊。这个桐生一马的case应该会比较明显的能看出来跟Runway的差异。

Runway的Act-One只能迁移表情,不支持迁移动作,但是稳定是真的稳定,直接直接加入动画生产工作流中的那种稳定。
在测试过程中,我也遇到了无数次说检测不到人脸的情况,所以还是要适应他们的一些规矩。
比如上传的视频,必须保证面部特征明显,肩膀以上,整个头部都在画面区域中,没有手部运动,效果是最好的,也是能识别的。整体要在30秒以内。
举个例子,著名的《楚门的世界》里面最后那一幕经典的独白。

这个片段,Runway死活说识别不到人脸上传不上去,其实就是头部没有完全在画面里,当我用AI视频扩展,把整个视频扩了1.5倍,把他画面外的头发给补出来后。
瞬间上传成功了。

上传的角色图片,可以是脸部特写,可以是半身,可以稍微侧一点脸,但是眼睛必须注视着摄像机的角度。
也同样的,必须包含整个头在里面,要不然会识别不到人脸,这个就很烦。
其他的就没啥注意事项了,Act-One的风格泛化很好,真人、3D、2D等等角色我测试下来驱动效果都很不错。
整体上,我确实觉得,Act-One对于动画行业来说,是革命性的。
成本极低,效果极佳,能匹配高质量项目的质量,这就足够让人心动了。
AI的每一步,都是生成效率和智能的巨大提升。
而且,他的可能性,在这短短几天,还远远没有被发掘,我再放两个我很喜欢的用Act-One做的例子,让大家看看,当AI跟想象力进行深度的碰撞,能碰出怎么样的火花。
第一个是一个导演Paul Trillo所做的小短片,当钱会说话。

效果非常的惊艳,当他把钱拿起来的那一刻,听到那声音,以及看着钱币中的人开口说话,我鸡皮疙瘩都起来了。
当Act-One+运动追踪+视觉特效,这玩意在艺术家手上,那真的就是完全不一样的火花。
另一个是Runway自己官方的case,也非常的有趣。

只需要一台手机,一个演员,就能用AI驱动一人分饰多角,演一出很酷的剧情。而且,已经几乎逼近电影质感了。
对于创作者来说,这是已经把成本给你打到尘埃里面去了。
Act-One最重要的,是为创作者们打开了一扇全新的大门。
你可以让历史人物"复活"讲述他们的故事,可以让艺术作品中的人物走出画作与观众对话,甚至可以让任何静态图像中的角色焕发生机。
你不再需要受到技术的限制,而是可以尽情发挥你的想象力。
重新定义,什么叫“可能”。
一切都在。
向前进。
文章来自于“数字生命卡兹克”,作者“卡兹克”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LivePortrait项目可以实现高效的人像动画,通过拼接和重定向控制技术,使一个静态人像或动物图像能够变成动态的视频,变成动画形式。
项目地址:https://github.com/KwaiVGI/LivePortrait?tab=readme-ov-file
