# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI-o1替代品来了,大模型能根据任务复杂度进行不同时间的思考。
不限于推理性的逻辑或数学任务,一般问答也能思考的那种。
最近畅销书《Python机器学习》作者Sebastian Raschka推荐了一项新研究,被网友们齐刷刷码住了。
论文一作为华人学者Tianhao Wu,导师之一是2011年清华特奖得主焦剑涛。
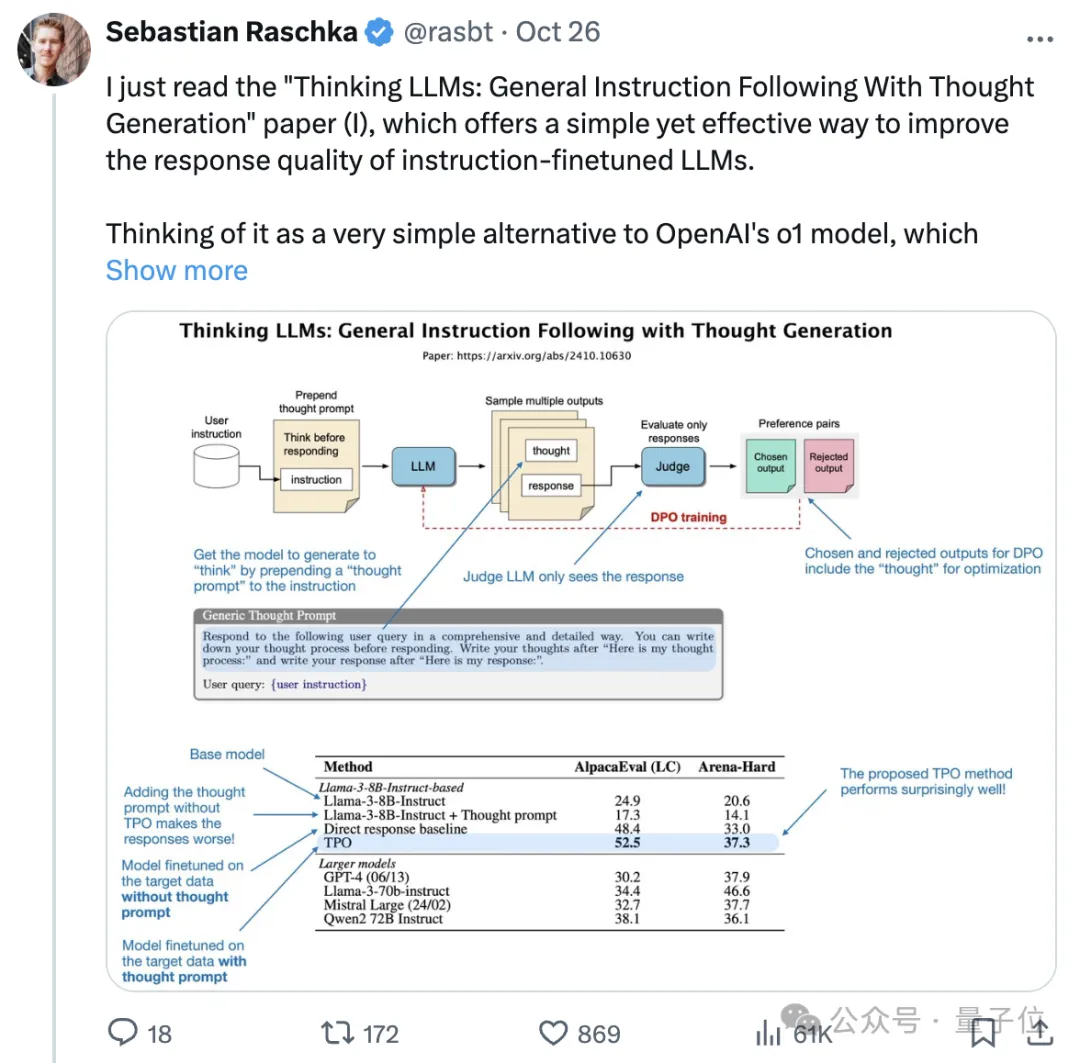
团队提出了一种称作思考偏好优化(Thought Preference Optimization)的方法,能让模型像OpenAI-o1一样,通过内部“思考”输出更好答案,最终只显示结果,不展示思考过程。
TPO将思维链式提示/推理融入训练中:
在回答之前,用思维链式方法进行思考;使用一个LLM评判来评估响应(不包括由LLM生成的想法);根据被拒绝和优选的响应形成偏好对进行DPO(包括这些响应中的想法)。
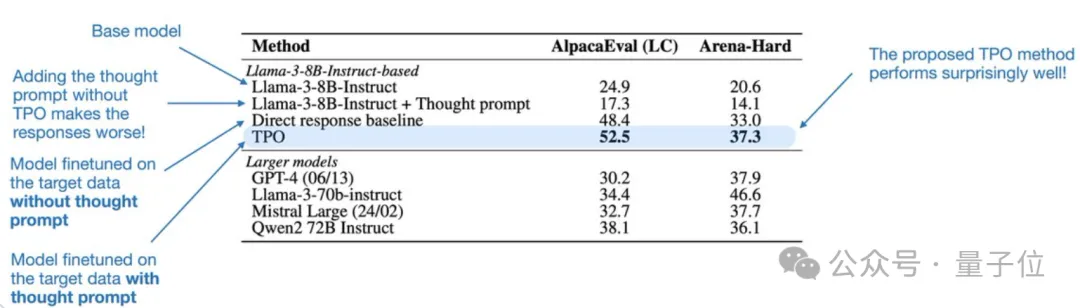
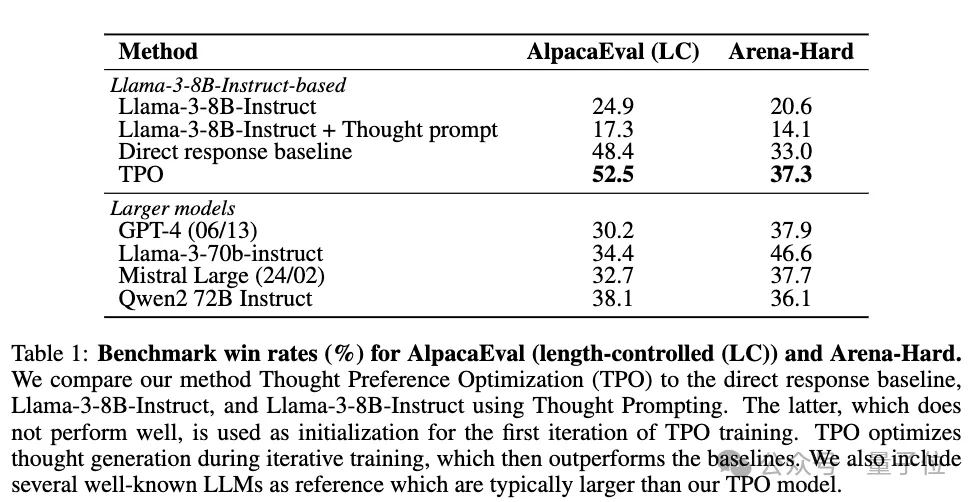
基于Llama 3 8B Instruct的结果表明,TPO效果相当好。
有意思的是,如果添加了思维提示,但Llama 3 8B Instruct基础模型没有在偏好对上经历DPO微调,那么这个基础模型的性能会比没有思维提示时差得多。
在指令数据(直接响应基线)上对模型进行微调(无需思考提示)就能显著提升基模型的性能。
进一步加入TPO,在AlpacaEval、Arena-Hard基准测试中,性能比基线再提升约4%。
网友纷纷表示这项研究很有意思,简单而又实用。
如果你已经在进行DPO,那么采用这种方法几乎就是不二之选了。

所以,TPO到底长啥样?
TPO的基本思路就是让模型在给出最终回答前先生成“思考”过程,且思考过程对用户不可见,仅作为模型内部计算过程,然后通过迭代优化来提升思考的质量,无需额外的人工标注数据。

具体来说,它的实现过程始于一个经过指令微调的基础语言模型,首先通过提示词引导模型生成包含思考过程和最终回答两个部分的输出。
这个提示词可以是通用型的,简单要求模型写下思考过程;也可以是具体型的,明确要求模型先写出草稿回答并进行评估。

对于每个用户指令,模型会生成多个不同版本的输出,每个都包含思考和回答部分。
且思考过程采用自然语言形式,便于解释和利用预训练知识。
然后系统会将这些输出中的回答部分(不含思考过程)提供给一个评判模型来打分。
评判模型可以是像ArmoRM这样直接对单个回答评分的模型,也可以是像Self-Taught Evaluator这样通过比较两个回答来选出更好者的模型。
基于评判结果,系统会选出得分最高和最低的回答,连同它们对应的思考过程一起构成偏好对。
这些偏好对随后被用于直接偏好优化(DPO)训练,通过这种方式,模型能够逐步学习到哪些思考方式能带来更好的回答。
整个过程是迭代进行的,每轮训练后得到的新模型会被用于下一轮的思考和回答生成。
为了防止回答变得过于冗长,TPO还引入了长度控制机制,通过在评分中加入长度惩罚项来平衡回答的质量和简洁性。
值得注意的是,在实际使用时,模型生成的思考过程会被隐藏,只向用户展示最终的回答部分。
更多细节,感兴趣的童鞋可自行查看原论文。
通过这种训练方法,即使是像Llama-3-8B-Instruct这样相对较小的模型也能在AlpacaEval等基准测试中取得接近甚至超过一些更大模型的性能。
在AlpacaEval基准测试中,TPO模型获得52.5%的胜率,比基线提升4.1%;在Arena-Hard测试上,TPO模型获得37.3%的胜率,比基线提升4.3%。
研究发现,虽然在训练初期,带思考的模型表现不如直接回答的基线模型,但经过多轮迭代训练后,TPO模型的表现明显超过基线。

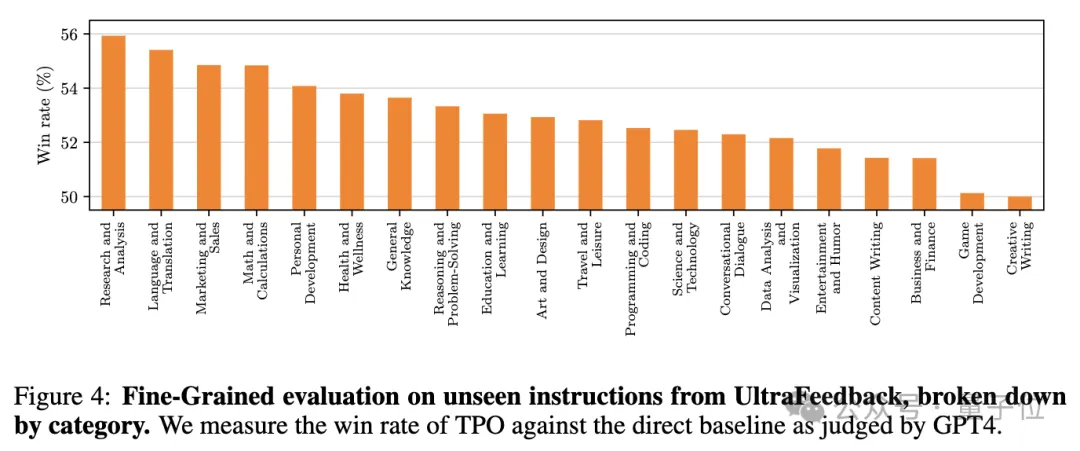
更细致的分析显示,思考不仅对推理和数学等传统认为需要思考的任务有帮助,在营销、健康、一般知识等非推理任务上也表现出优势,模型会随着训练逐渐学会更高效的思考(思考长度缩短)。
这项研究由来自Meta FAIR、加州大学伯克利分校、纽约大学的研究人员共同提出。

论文一作为华人学者Tianhao Wu。
Tianhao Wu目前是加州大学伯克利分校博士生,导师是焦剑涛(Jiantao Jiao)和Kannan Ramchandran。
本科主修数学,合作导师是北大教授、清华交叉信息学院兼职教授王立威(Liwei Wang)。
他的研究重点是通过强化学习改善大语言模型的指令遵循和推理能力,目标是构建可以解决需要多步骤推理的复杂任务的大规模模型。
此外他还在开发由Agent组成的AI社会,这些Agent可以以模块化的方式连接起来,形成更强大的集体智能。

论文链接:https://arxiv.org/abs/2410.10630
参考链接:
[1]https://x.com/rasbt/status/1850177459930497118
[2]https://thwu1.github.io/tianhaowu/
文章来自于微信公众号“量子位”,作者“西风”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
