# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
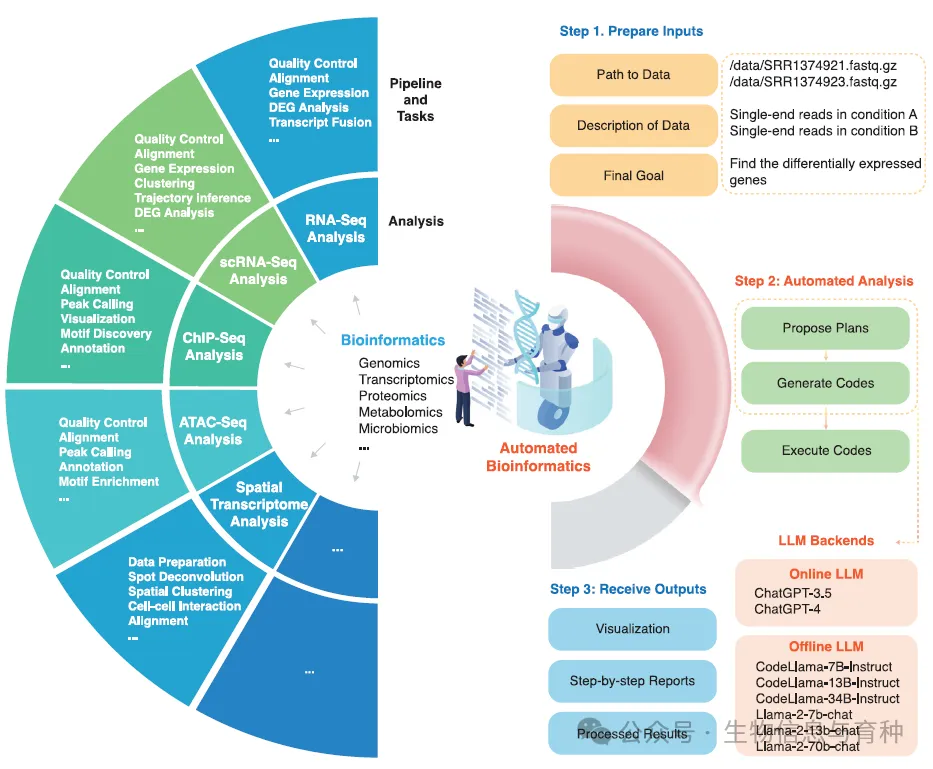
分享一篇近期由华为和阿卜杜拉国王科技大学合作完成的一项生信分析与大语言模型相结合的工作,相关成果发表在《Advanced Science》上。

该文介绍了一个名为AutoBA(Automated Bioinformatics Analysis)的人工智能代理,它专门设计用于全面自动化的多组学分析。AutoBA基于大型语言模型(LLMs),能够简化分析流程,仅需最少的用户输入,同时为各种生物信息学任务提供详细的逐步计划。
AutoBA是一个为传统多组学分析量身定制的自主AI代理。它通过用户提供的三个关键输入(数据路径、数据描述和最终分析目标)来自动分析数据、生成详细的逐步计划、编写代码、执行代码并进行深入分析。AutoBA作为开源软件实现,提供多个LLM后端,并支持在线和本地使用,优先考虑数据安全和用户隐私。
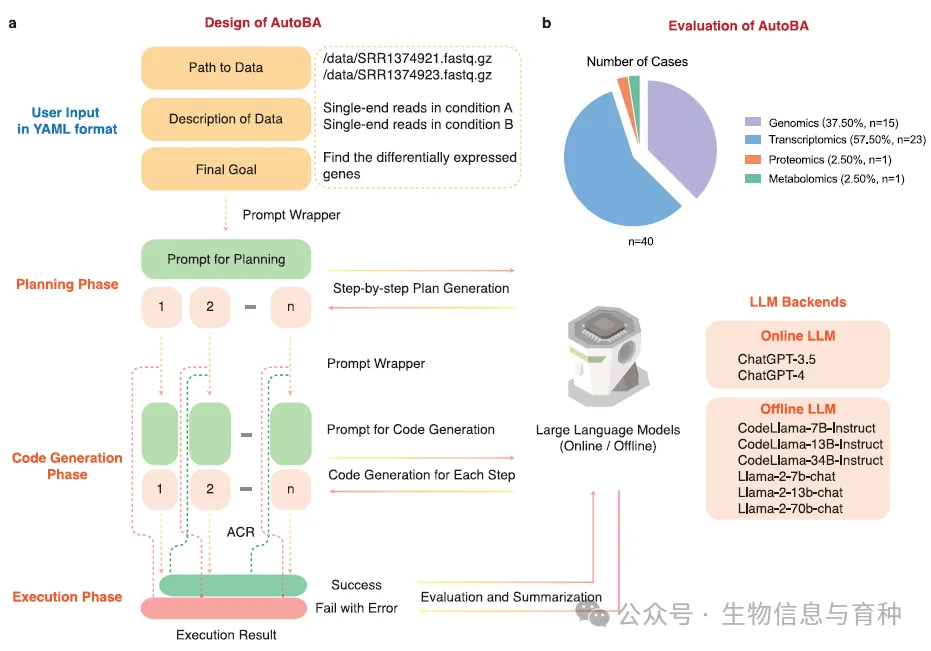
AutoBA的工作流程包括规划阶段、代码生成阶段和执行阶段。在规划阶段,AutoBA详细概述了分析计划,包括每个步骤要使用的软件名称和版本,以及每个阶段的指导行动和特定子任务。在代码生成阶段,AutoBA根据计划生成子任务的代码,包括配置环境、安装必要的软件和编写代码。在执行阶段,AutoBA执行生成的代码。
AutoBA的设计
AutoBA内置了记忆机制,使其能够通过参考先前行动来更有效地生成代码,避免某些步骤的不必要重复。在规划阶段,记忆被结构化为:“首先,您提供了输入格式为‘文件路径:文件描述’的列表:<data list>。您制定了一个详细计划来完成您的总体目标。您的总体目标是<global goal>。您的计划涉及<tasks>。”在代码生成阶段,记忆遵循以下格式:“然后,您成功完成了任务:<task>,对应的代码:<code>。”
AutoBA包含了一个自动代码修复(ACR)模块,旨在简化调试过程并提高生成代码的可靠性。在代码执行阶段,AutoBA从标准错误(stderr)和标准输出(stdout)的输出流中识别错误。一旦检测到错误,这些检测到的错误将被整合到代码再生的提示中,确保重复循环直到生成的代码成功执行无误。
AutoBA的结果经过生物信息学专家的彻底验证,包括对提出的计划、生成的代码、代码执行以及结果的准确性和可靠性的确认。AutoBA的开发和验证基于特定的环境和软件堆栈,包括Ubuntu版本20.04、Python 3.10.0和openai版本0.27.6。这些环境和软件规格为AutoBA在生物信息学领域的功能性提供了坚实的基础,确保了其可靠性和有效性。
AutoBA的评估
AutoBA提供了几种LLM后端版本,包括基于ChatGPT-3.5和ChatGPT-4的在线后端,以及包括CodeLlama-7B-Instruct、CodeLlama-13B-Instruct、CodeLlama-34B-Instruct在内的本地LLMs。
AutoBA采用了沙箱模式来建立一个安全隔离的环境进行分析,有效保护底层系统免受潜在威胁。同时,AutoBA在执行阶段对系统命令施加限制,从而降低恶意命令在环境中执行的风险。此外,AutoBA利用Docker容器化,引入了额外的安全层来进一步加强整体系统完整性。
为了评估AutoBA的鲁棒性,研究者进行了涉及40个案例的评估,涵盖四种不同的组学数据:基因组学、转录组学、蛋白质组学和代谢组学。所有案例都由AutoBA独立分析,并随后由经验丰富的生物信息学专家进行验证。总体结果强调了AutoBA在生物信息学领域多种多组学分析程序中的多功能性和鲁棒性。
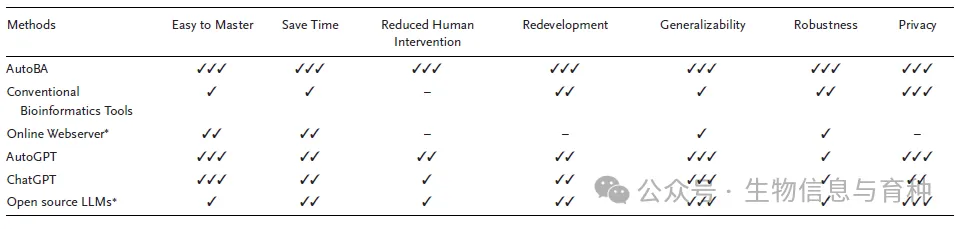
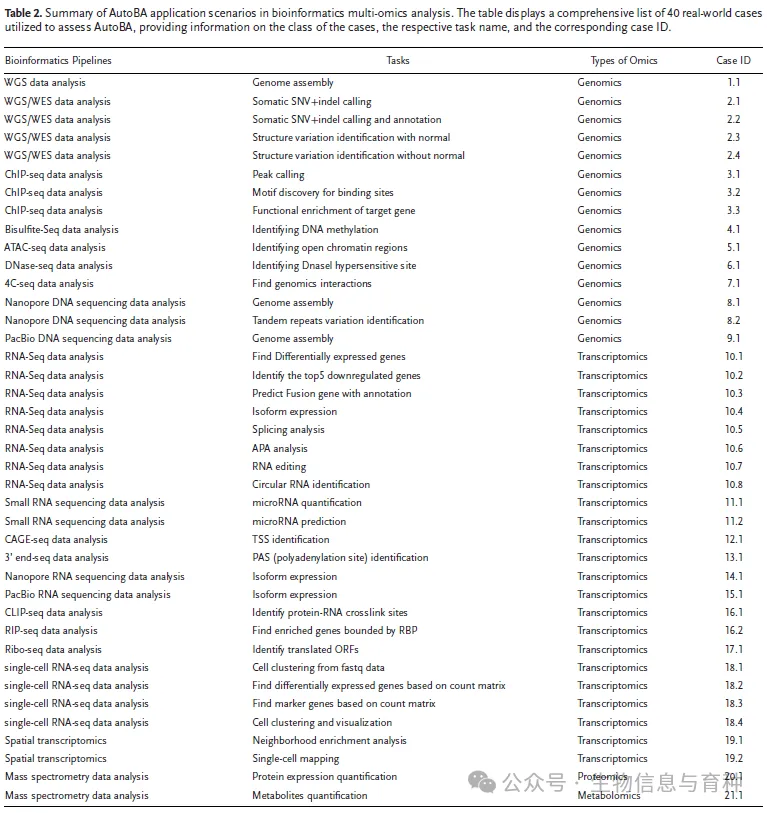
据作者所知,AutoBA是第一个明确为多组学数据分析量身定制的自主AI代理。AutoBA通过最少的用户输入简化分析流程,同时为各种生物信息学任务提供详细的逐步计划。AutoBA的一个关键优势是其对分析目标变化的适应性。此外,AutoBA的多功能性体现在其能够根据不同的输入数据自设计新的分析流程。这种自动适应性使AutoBA成为生物信息学家处理新颖或非传统研究问题时的宝贵工具。与当前流行的在线生物信息学分析平台相比,AutoBA通过提供在线版本和本地版本来解决隐私问题,从而消除了与第三方共享任何信息的需求。AutoBA还展示了其与新兴生物信息学工具的同步适应性,LLMs能够无缝地将这些最新工具纳入数据库。另一个区别特征是AutoBA的透明和可解释的执行过程,这允许专业生物信息学家轻松修改和自定义AutoBA的输出,利用AutoBA加快数据分析过程。AutoBA也是一个为生物信息学分析设计的面向未来的AI代理,利用LLMs作为其核心。这种设计允许AutoBA与任何现有的LLM集成,无论是在线(例如,ChatGPT、GPT-4、GPT-4o)还是离线(例如,LLaMA、CodeLLaMA和DeepSeek)。AutoBA使用的LLM是完全可替代的,使其能够从LLM技术的持续进步中受益。随着新的最先进的LLMs的发展,AutoBA可以整合它们以提高其在自动生物信息学分析中的性能。
尽管如此,AutoBA在工具选择上的限制仍然存在。当前的LLMs在互联网数据上进行训练,这意味着在生物信息学中广泛使用的方法通常训练得很好,而特定论文中的方法可能代表性不足或根本没有训练。因此,当使用经过广泛训练的工具时,可以获得最佳结果,这可能导致工具选择中的潜在偏见。为了解决这个问题,未来可以训练一个涵盖领域内所有工具和方法的专门的生物信息学LLM。考虑到用于大型语言模型的训练数据的时效性,值得注意的是,生物信息学中最近提出的方法可能仍然在自动生成代码方面对AutoBA构成挑战。因此,未来努力训练一个专门针对生物信息学的最新大型语言模型,可以显著提高AutoBA保持最新代码生成能力的能力。尽管如此,AutoBA代表了生物信息学领域的一个显著进步,提供了一个用户友好、高效和可适应的解决方案,用于广泛的组学分析任务。其处理不同数据类型和分析目标的能力,加上其鲁棒性和适应性,使AutoBA成为加速生物信息学研究的宝贵资产。作者预计AutoBA将在科学界得到广泛使用,支持研究人员从复杂的生物数据中提取有意义的见解。
总之,挺有意思的一个项目:https://github.com/JoshuaChou2018/AutoBA
文章来自于微信公众号“生物信息与育种”




【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
