# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近期,港中大(深圳)联手趣丸科技联合推出了新一代大规模声音克隆 TTS 模型 ——MaskGCT。该模型在包含 10 万小时多语言数据的 Emilia 数据集上进行训练,展现出超自然的语音克隆、风格迁移以及跨语言生成能力,同时保持了较强的稳定性。MaskGCT 已在香港中文大学(深圳)与上海人工智能实验室联合开发的开源系统 Amphion 发布。

本文介绍了一种名为 Masked Generative Codec Transformer(MaskGCT)的全非自回归 TTS 模型。
现有大规模文本到语音(TTS)系统通常分为自回归和非自回归系统。自回归系统隐式地建模持续时间,但在鲁棒性和持续时间可控性方面存在一定缺陷。非自回归系统在训练过程中需要显式的文本与语音对齐信息,并预测语言单元(如音素)的持续时间,这可能会影响其自然度。
该模型消除了文本与语音监督之间的显式对齐需求,以及音素级持续时间预测。MaskGCT 是一个两阶段模型:在第一阶段,模型使用文本预测从语音自监督学习(SSL)模型中提取的语义标记;在第二阶段,模型基于这些语义标记预测声学标记。MaskGCT 遵循掩码预测学习范式。在训练过程中,MaskGCT 学习根据给定的条件和提示预测掩码的语义或声学标记。在推理过程中,模型以并行方式生成指定长度的标记。通过对 10 万小时的自然语音进行实验,结果表明 MaskGCT 在质量、相似度和可理解性方面优于当前最先进的零样本 TTS 系统。
MaskGCT 模型由四个主要组件组成:
1. 语音语义表示编解码器:将语音转换为语义标记。
2. 语音声学编解码器:从声学标记重建波形。
3. 文本到语义模型:使用文本和提示语义标记预测语义标记。
4. 语义到声学模型:基于语义标记预测声学标记。

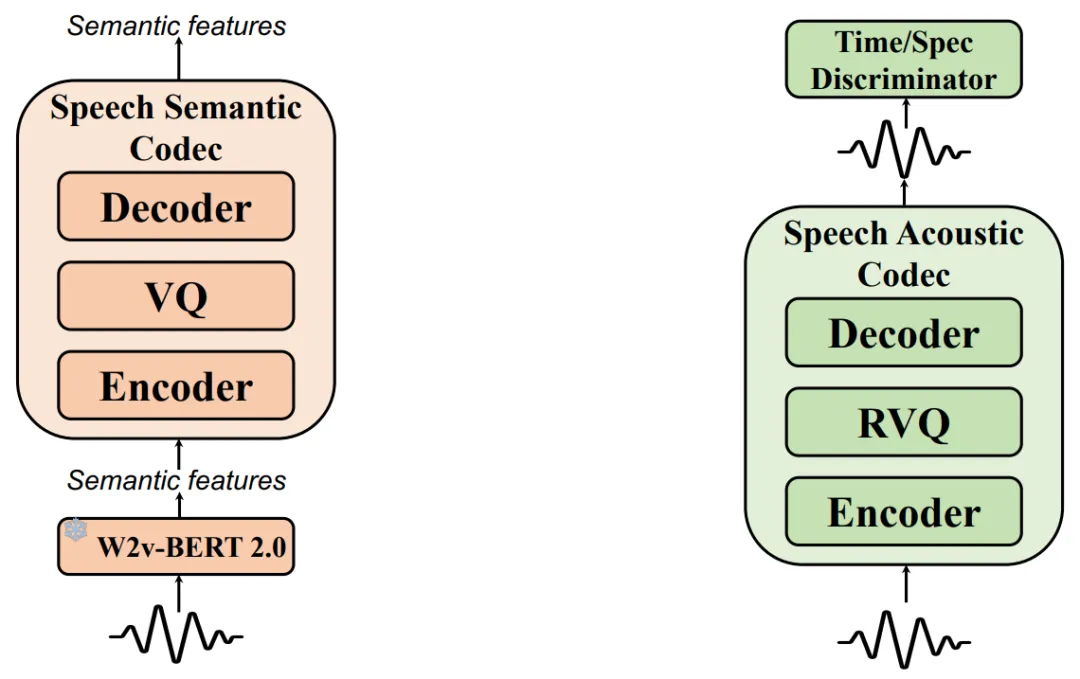
语音语义表示编解码器用于将语音转换为离散的语义标记,这些标记通常通过离散化来自语音自监督学习(SSL)模型的特征获得。与以往使用 k-means 方法离散化语义特征相比,这种方法可能导致信息损失,从而影响高质量语音的重建或声学标记的精确预测,尤其是在音调丰富的语言中。为了最小化信息损失,本文训练了一个 VQ-VAE 模型来学习一个向量量化码本,该码本能够从语音 SSL 模型中重建语音语义表示。具体来说,使用 W2v-BERT 2.0 模型的第 17 层隐藏状态作为语音编码器的语义特征,编码器和解码器由多个 ConvNext 块组成。通过改进的 VQ-GAN 和 DAC 方法,使用因子分解码将编码器输出投影到低维潜在变量空间。
语音声学编解码器旨在将语音波形量化为多层离散标记,同时尽可能保留语音的所有信息。本文采用残差向量量化(Residual Vector Quantization, RVQ)方法,将 24K 采样率的语音波形压缩为 12 层的离散标记。此外,模型使用 Vocos 架构作为解码器,以提高训练和推理效率。
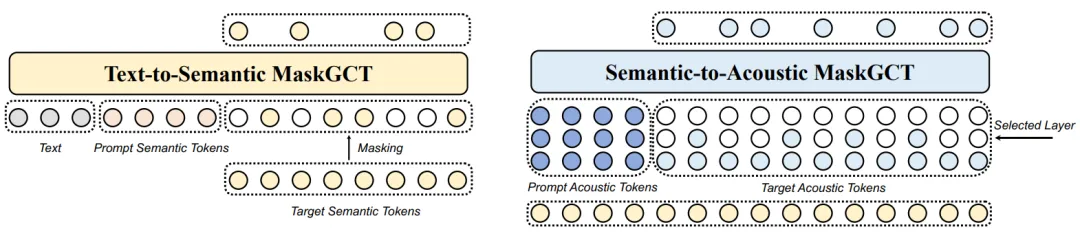
文本到语义模型采用非自回归掩码生成 Transformer,而不使用自回归模型或任何文本到语音的对齐信息。在训练过程中,我们随机提取语义标记序列的前缀部分作为提示,以利用语言模型的上下文学习能力。我们使用 Llama 风格的 Transformer 作为模型的主干,结合门控线性单元(GLU)和 GELU 激活函数、旋转位置编码等,但将因果注意力替换为双向注意力。还使用了接受时间步 t 作为条件的自适应 RMSNorm。在推理过程中,我们生成任意指定长度的目标语义标记序列,条件是文本和提示语义标记序列。本文还训练了一个基于流匹配的持续时间预测模型,以预测基于文本和提示语音持续时间的总持续时间,利用上下文学习。
语义到声学模型同样采用非自回归掩码生成 Transformer,该模型以语义标记为条件,生成多层声学标记序列以重建高质量语音波形。
MaskGCT 能超自然地模拟参考音频音色与风格,并跨语言生成音频:
参考音频:

中文克隆效果:
英文克隆效果:

MaskGCT 还能够模仿动画人物和名人的声音,猜猜下面的音频都是谁?
以下是一个展示 MaskGCT 翻译《黑神话:悟空》的实例:
参考音频:

翻译效果:

SOTA 的语音合成效果:MaskGCT 在三个 TTS 基准数据集上都达到了 SOTA 效果,在某些指标上甚至超过了人类水平。
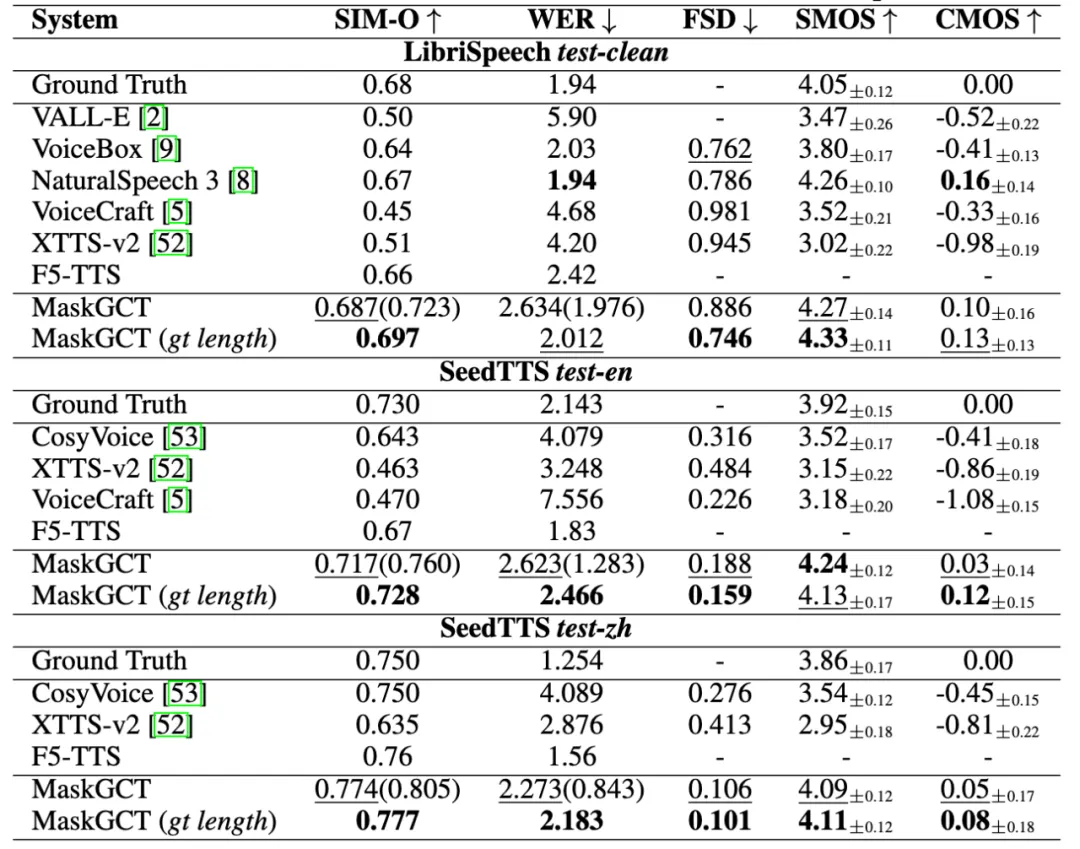
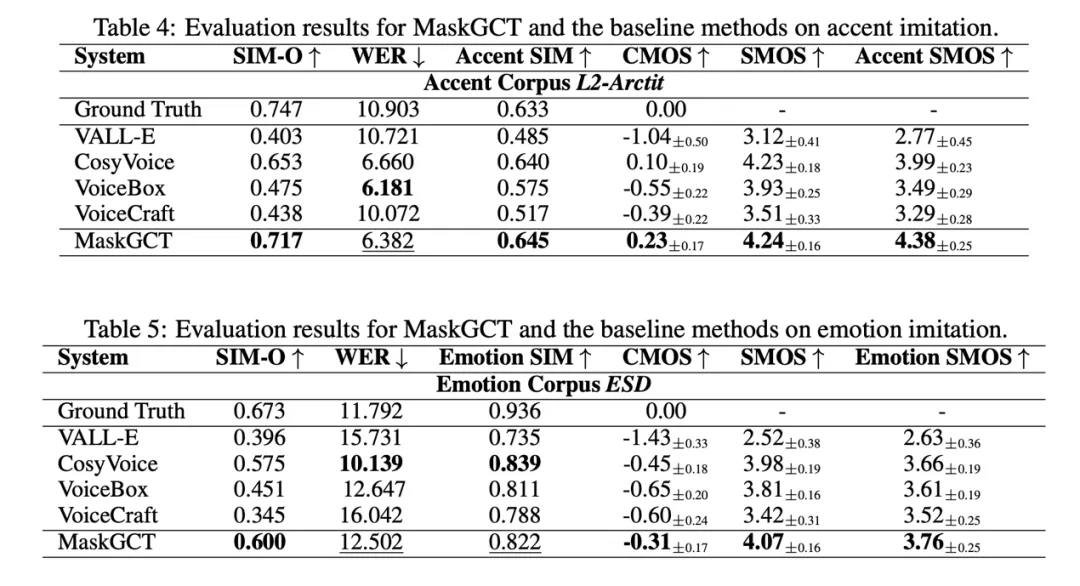
此外,MaskGCT 在风格迁移(口音、情感)也达到了 SOTA 的水准:
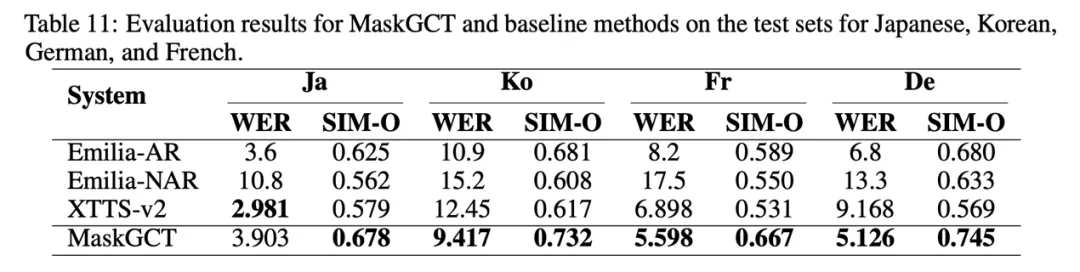
我们还研究了 MaskGCT 在中、英外其它语言的能力:
目前,MaskGCT 在短剧出海、智能助手、有声读物、辅助教育等领域拥有丰富的应用场景。为了加快落地应用,在安全合规下,趣丸科技打造了多语种速译智能视听平台 “趣丸千音”。一键上传视频即可快速翻译成多语种版本,并实现音话同步、口型同步、去字幕等功能。该产品进一步革新视频翻译制作流程,大幅降低过往昂贵的人工翻译成本和冗长的制作周期,成为影视、游戏、短剧等内容出海的理想选择平台。
《2024 年短剧出海白皮书》显示,短剧出海成为蓝海新赛道,2023 年海外市场规模高达 650 亿美元,约为国内市场的 12 倍,短剧出海成为蓝海新赛道。以 “趣丸千音” 为代表的产品的出现,将加速国产短剧 “走出去”,进一步推动中华文化在全球不同语境下的传播。
MaskGCT 是一个大规模的零样本 TTS 系统,利用全非自回归掩码生成编解码器 Transformer,无需文本与语音的对齐监督和音素级持续时间预测。MaskGCT 通过文本预测从语音自监督学习(SSL)模型中提取的语义标记,然后基于这些语义标记预测声学标记,实现了高质量的文本到语音合成。实验表明,MaskGCT 在语音质量、相似度和可理解性方面优于最先进的 TTS 系统,并且在模型规模和训练数据量增加时表现更佳,同时能够控制生成语音的总时长。此外,我们还探索了 MaskGCT 在语音翻译、语音转换、情感控制和语音内容编辑等任务中的可扩展性,展示了 MaskGCT 作为语音生成基础模型的潜力。
文章来自于微信公众号 “机器之心”



【开源免费】MockingBird是一个5秒钟即可克隆你的声音的AI项目。
项目地址:https://github.com/babysor/MockingBird
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
