# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。
但当前的大部分评测基准仍然具有以下几个缺陷:
针对这些问题,有没有对应的基准能够较好解决这些问题呢?
在最新的NeurIPS D&B 2024中由浙江大学联合上海人工智能实验室,上海交通大学和香港中文大学提出的MMBench-Video打造了一个全面的开放性视频理解评测基准,并针对当前主流MLLM构建了开源的视频理解能力评估榜单。


MMBench-Video这一视频理解评测基准采取全人工标注,历经一次标注和二次质量核验,视频种类丰富且质量高,问答涵盖模型能力全面,准确回答问题需要横跨时间维度对信息进行提取,更好的考察了模型的时序理解能力。
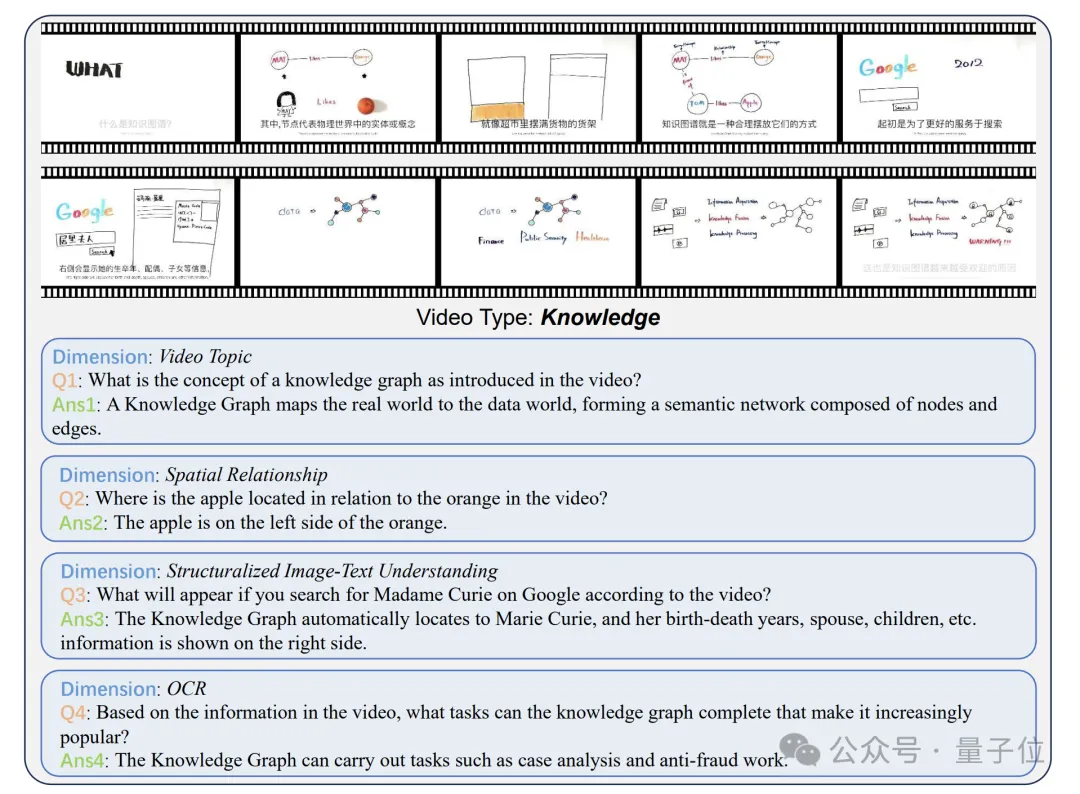
与其他数据集相比,MMBench-Video具有如下几个突出特点:
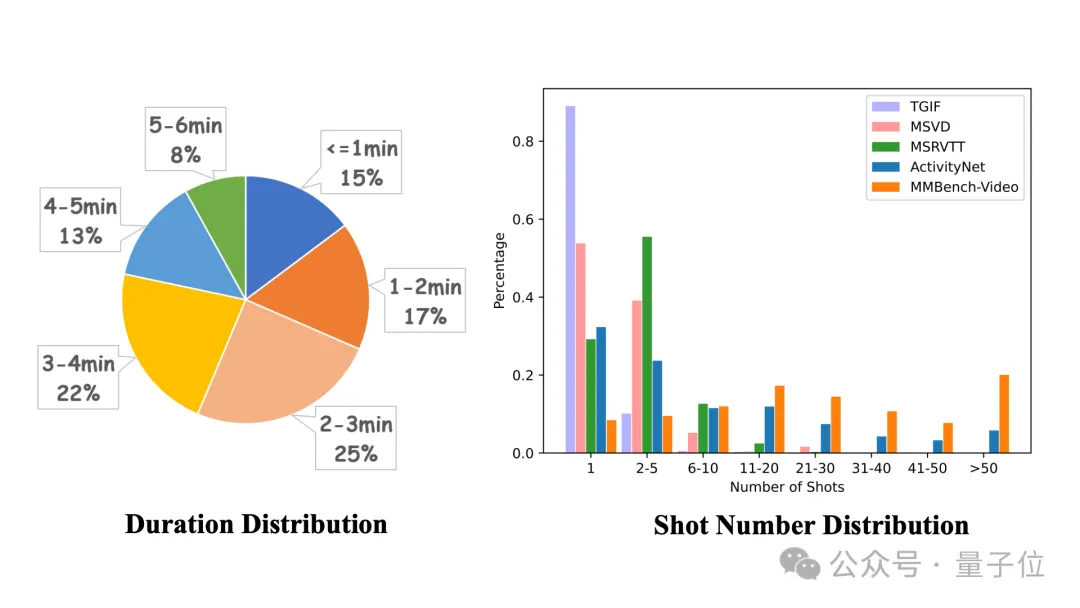
视频时长跨度较广,镜头数多变:采集的视频时长从30秒到6分钟不等,避免了过短视频语意信息简单,过长视频评测带来的资源消耗大等问题。同时视频涵盖的镜头数整体呈长尾分布,一个视频最多具有210个镜头,包含了丰富的场景与语境信息。
全方位能力大考,感知与推理的全面挑战:模型的视频理解能力主要包含感知和推理两个部分,每个部分能力可以再额外进行细化。受MMBench启发并结合视频理解所涉及到的具体能力,研究者建立了一个包含26个细粒度能力的综合能力谱系,每个细粒度能力都用数十到数百个问答对进行评估,且并不为现有任务的集合。
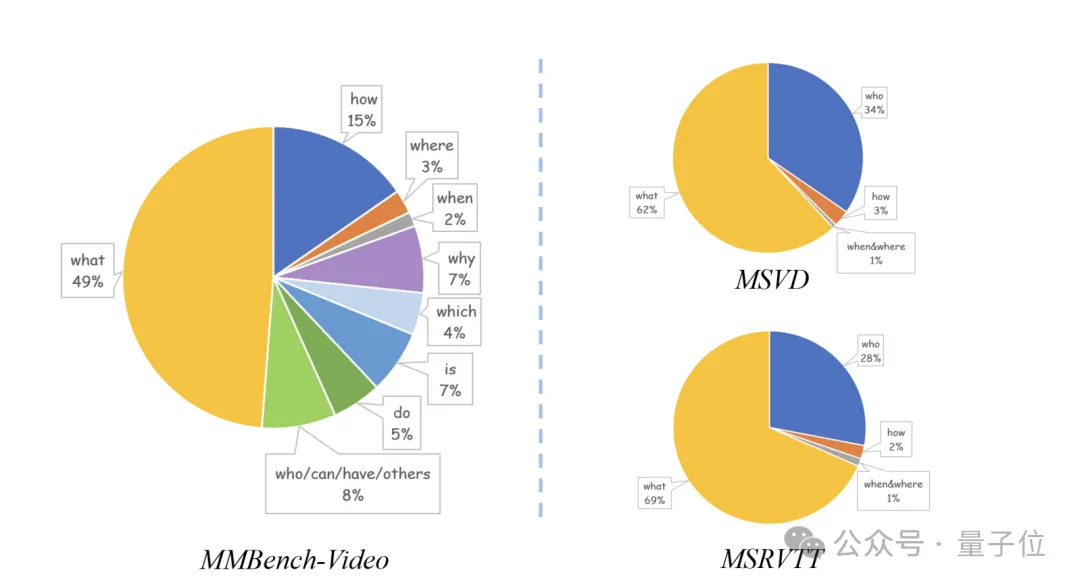
视频种类丰富,问答语言多样性强:覆盖了人文、体育、科教、美食、金融等16个主要领域,每个领域视频均占到5%以上。同时问答对相比传统VideoQA数据集有了进一步的长度及语意丰富度提升,不局限于’what’’when’等简单问题类型。
时序独立性佳,标注质量高:在研究中发现,大部分VideoQA数据集能够仅通过视频内的1帧获得充足的信息,从而进行准确的回答。这可能是因为视频内前后画面变化较小,视频镜头少,也可能是因为问答对质量较低。研究者将这一情况称之为数据集的时序独立性较差。与他们相比,MMBench-Video由于在标注时给出了详细的规则限制,且问答对经过二次核验,具有显著较低的时序独立性,能够更好的考察模型的时序理解能力。

为了更加全面评估多个模型的视频理解性能,MMBench-Video选取了11个代表性的视频语言模型,6个开源图文多模态大模型及GPT-4o等5个闭源模型进行全面的实验分析。
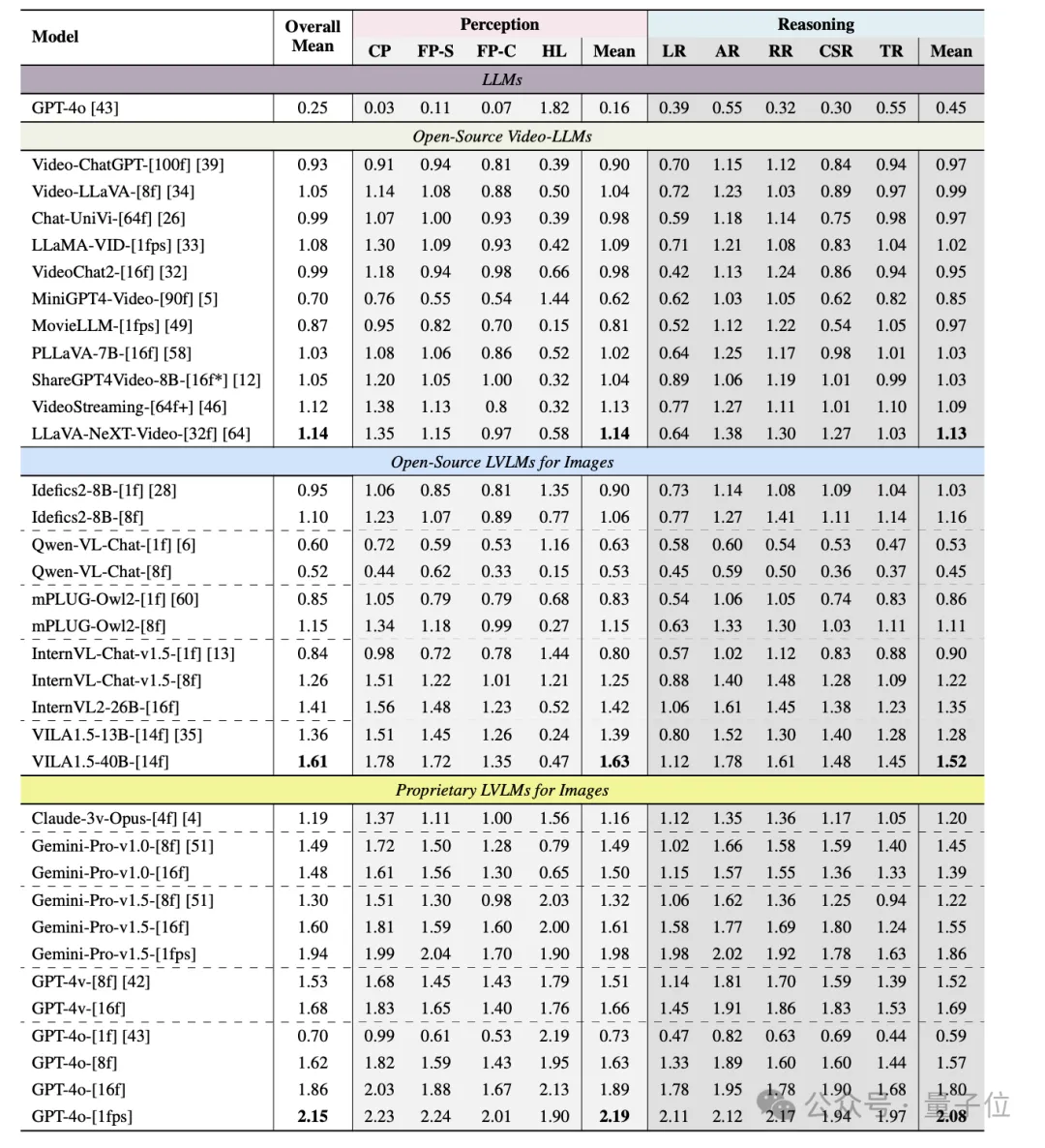
在所有模型当中,GPT-4o在视频理解方面表现突出,同时Gemini-Pro-v1.5也展现出了出众的模型性能。
令人讶异的是,现有的开源图文多模态大模型在MMBench-Video上表现整体优于经过视频-问答对微调的视频语言模型,最优的图文模型VILA1.5在整体性能上超出最优的视频模型LLaVA-NeXT-Video近40%。

经过进一步探究发现,图文模型之所以在视频理解上表现更优,可能归因于它们在处理静态视觉信息时的精细化处理能力更强,而视频语言模型在面向静态图像的感知及推理性能均有不足,进而面对更复杂的时序推理和动态场景时显得力不从心。
这种差异揭示了现有视频模型在空间和时间理解上的显著不足,尤其是在处理长视频内容时,其时序推理能力亟待提升。此外,图文模型通过多帧输入在推理上的性能提升表明,它们有潜力进一步拓展至视频理解领域,而视频模型则需要在更广泛的任务上加强学习,以弥补这一差距。
视频长度和镜头数量被认为是影响模型性能的关键因素。
实验结果表明,随着视频长度的增加,GPT-4o在多帧输入下的表现有所下降,而开源模型如InternVL-Chat-v1.5和Video-LLaVA的表现相对稳定。相比视频长度,镜头数量对模型性能的影响更为显著。
当视频镜头超过50个时,GPT-4o的性能下降至原始得分的75%。这表明,频繁的镜头切换使得模型更难以理解视频内容,导致其表现下降。

除此之外,MMBench-Video还借助接口获取到了视频的字幕信息,从而通过文字引入了音频模态。
在引入后,模型在视频理解上的表现得到了显著提升,当音频信号与视觉信号结合时,模型能够更加准确地回答复杂问题。这一实验结果表明,字幕信息的加入能极大丰富模型的上下文理解能力,尤其是在长视频任务中,语音模态的信息密度为模型提供了更多线索,帮助其生成更精确的回答。然而,需要注意的是,虽然语音信息可以提升模型性能,但同时也可能增加生成幻觉内容的风险。

在裁判模型选择方面,实验显示GPT-4具备更为公正和稳定的评分能力,其抗操纵性强,评分不偏向于自己的回答,能够更好地与人工评判对齐。
相比之下,GPT-3.5在评分时容易出现偏高的问题,导致最终结果的失真。与此同时,开源的大语言模型,如Qwen2-72B-Instruct,也展现了出色的评分潜力,其在与人工评判的对齐度上表现突出,证明其有望成为一种高效的评估模型工具。
MMBench-Video目前支持在VLMEvalKit中一键评测。
VLMEvalKit是一个专为大型视觉语言模型评测设计的开源工具包。它支持在各种基准测试上对大型视觉语言模型进行一键评估,无需进行繁重的数据准备工作,使评估过程更加简便。VLMEvalKit适用于图文多模态模型及视频多模态模型的评测,支持单对图文输入、图文交错输入及视频-文本输入。它实现70多个基准测试,覆盖了多种任务,包括但不限于图像描述、视觉问答、图像字幕生成等。所支持的模型及评测基准正在不断更新中。
同时基于现有视频多模态模型的评测结果较为分散,难以复现等现实,团队还建立了OpenVLM Video Leaderboard这一针对模型的综合视频理解能力评测榜单。OpenCompass VLMEvalKit团队将持续更新最新多模态大模型及评测benchmark,打造主流,开放,便捷的多模态开源评测体系。

最后总结一下,MMBench-Video是一个针对视频理解任务设计的全新长视频、多镜头基准,涵盖了广泛的视频内容和细粒度能力评估。
基准测试包含从YouTube收集的600多个长视频,涵盖新闻、体育等16个主要类别,旨在评估MLLMs的时空推理能力。与传统的视频问答基准不同,MMBench-Video通过引入长视频和高质量的人工标注问答对,弥补了现有基准在时序理解和复杂任务处理方面的不足。
通过GPT-4评估模型的答案,该基准展现了更高的评估精度和一致性,为视频理解领域的模型改进提供了有力的工具。
MMBench-Video 的推出为研究人员和开发者提供了一个强大的评估工具,帮助开源社区深入理解和优化视频语言模型的能力。
论文链接:
https://arxiv.org/abs/2406.14515
Github链接:
https://github.com/open-compass/VLMEvalKit
HomePage:
https://mmbench-video.github.io/
MMBench-Video LeaderBoard:
https://huggingface.co/spaces/opencompass/openvlm_video_leaderboard
文章来自于“量子位”,作者“新宇”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
