
DeepMind 公布其正在开发一套创新的音频生成技术细节,也就是NotebookLM背后使用的语音技术。使 AI 能够生成更加自然的对话和高质量的音频。这些技术不仅提升了语音助手的交互性,还帮助多种应用在语音合成和对话生成上取得更大进展。
1. 核心音频生成技术
- SoundStream 是一个神经音频编码器,它能够高效地将音频压缩成一组声学令牌(tokens),然后解码出接近原始音频的高保真声音。
- 这是一种 AI 技术,它能够把一段音频压缩成一组小的“音符”(被称为声学令牌),然后再解压缩成高保真音频。这个过程类似于把一段语音“翻译”成数据,然后再“翻译”回来。
- 声学令牌是音频的数字表示,它们携带语音的各种信息,如语调、节奏和声音细节。这些令牌类似于文本模型中的词汇,帮助 AI 生成自然语音。
- AudioLM 将音频生成视为一种语言建模任务,即将音频生成类比于文本生成。通过处理这些声学令牌,它不需要为不同类型的声音进行模型调整,可以灵活地生成多种类型的音频。
- 可以将生成语音看作生成文字的类似过程。它像 GPT 这样的文本模型一样工作,但处理的不是单词,而是声音数据。
- 这项技术能够生成多说话人对话,而无需为每个说话人调整模型。
- SoundStorm 是 DeepMind 开发的一个多说话人对话生成模型,能够生成多达 30 秒的自然对话段落。
- 它进一步发展了 AudioLM 和 SoundStream 的基础技术,能够根据不同说话人的标记生成更长、更自然的对话。
- 可以生成多个人之间的对话,而不是一个人独白。例如,AI 可以模拟一场访谈,两个虚拟人物有问有答,看起来像是“现场”对话。
举例:
- 你正在和语音助手(比如 Google Assistant)对话,问它:“明天天气怎么样?”以往的语音助手可能会直接回复一句“明天多云”。而用 DeepMind 的技术,语音助手可能会更自然地说:“明天可能会有些多云,记得带把伞哦。”
2. 最新的音频生成技术
- DeepMind 的新一代音频生成模型能够生成长达 2 分钟的对话,并且保持高质量的音频输出。这项技术通过以下方式实现改进:
- 更快的生成速度:该模型在 3 秒内即可生成 2 分钟的对话,速度比实时生成快 40 倍。
- 自然的对话流:模型能够保持说话人之间的连贯切换,输出语音中还包括自然的停顿、口头语(如 “嗯”、“啊”)等细节,使得生成的对话更接近真实交流。
- 高效的计算架构:利用新的 Transformer 架构,模型能够处理更长的音频序列,同时保持高效的推理过程。这些音频序列以自回归方式生成,意味着模型会逐步生成音频内容,确保准确性和一致性。
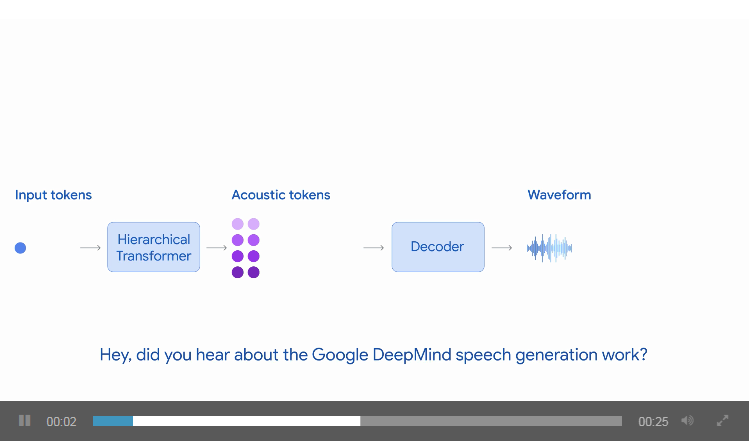
动画展示了语音生成模型如何自回归生成音频标记流,并将其解码回由两个说话者对话组成的波形。
3. 多层次的音频压缩与处理
- 新的语音编码技术可以把音频压缩到 600 bps(比特每秒),比以前的技术更高效,但仍能保持清晰的音质。
- 生成的“音符”分为多层次,每一层代表不同的语音信息:
- 第一层:包含基本的语音信息,比如语调和节奏。
- 后续层次:包含更细致的声音细节,比如声音的音色和细腻的发音。
举例:
- 在一个教育应用中,AI 正在解释二次方程的解法。以前的 AI 可能会平铺直叙地说:“二次方程的解法是…” 但有了新的技术,AI 可能会用更自然的语气说:“我们现在来看看二次方程的解法吧!首先呢,我们需要…”,不仅保持清晰,还显得更有人情味。
4. 训练方法和数据集
- 大规模预训练:模型通过数十万小时的语音数据进行预训练,学习如何生成基础的语音结构。
- 高质量对话微调:为了让模型生成更自然的对话,DeepMind 还使用了小规模的高质量对话数据集进行微调。这个数据集包含真实对话中的细微特征,如非剧本对话、自然停顿和真实的语音变化。
5. 模型的潜在应用
DeepMind 的音频生成技术正在应用于多种 Google 产品和实验项目,如:
YouTube 自动配音:用 AI 自动为视频生成多语言的配音。以前的配音可能很平淡,但新的技术能让 AI 配音听起来更真实。
NotebookLM 音频概述:这是一种新功能,能把文档内容转成两个 AI 角色的对话形式,像是在听一场讨论会。
教育和普及内容:通过将复杂的研究论文或文章转化为自然的对话形式,让人们更轻松地理解。
举例:如果你上传了一篇关于气候变化的文章,AI 会自动生成一个对话版本。例如:
AI 1:“气候变化是一个全球性问题。”
AI 2:“是的,尤其是温室气体排放带来的影响。”
这就像是两个专家在讨论,而不是单调的文章朗读。
这项技术的主要应用场景包括:
语音助手:生成更自然、对话性强的语音响应。
教育和普及内容:例如,将研究论文转化为对话形式,帮助用户更轻松地理解复杂的内容。
多模态交互:计划将语音生成技术与视频等其他模式结合,以提升学习体验和信息传达效果。
原文:https://deepmind.google/discover/blog/pushing-the-frontiers-of-audio-generation
文章来自于“XiaoHu.AI日报”,作者“小互”



