# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
鱼与熊掌可以兼得,厦门大学和vivo AI lab联合提出预训练学习率调整新策略,降低训练42%成本的同时,还能保持大模型效果,该成果已发表于AI领域的顶级会议EMNLP2024。
近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。此外在实际应用中,新数据的不断涌现使LLMs需要不断进行版本更新来保持性能优势,这加剧了LLMs的训练成本。为了探索如何在降低训练成本的同时确保不同版本LLMs的性能,来自厦门大学和vivo的研究员共同展开研究,在EMNLP2024联合提出了一种能更好地平衡版本更新时LLMs的性能和成本的训练范式,并应用于vivo的蓝心大模型训练。

论文标题:
A Learning Rate Path Switching Training Paradigm for Version Updates of Large Language Models
论文链接:
https://arxiv.org/abs/2410.04103
现有的适用于LLMs版本更新的训练范式可分为两类:1)从头开始预训练(pre-training from scratch, PTFS),即在新旧数据上重新训练新版本LLMs;2)继续预训练(continual pre-training, CPT),即基于旧版本LLMs的参数(checkpoint),在新数据上进一步训练新版本LLMs。为了对比现有两类训练范式,我们基于Cosine、Knee和Multi-Step学习率调度策略,模拟LLMs的版本迭代更新。
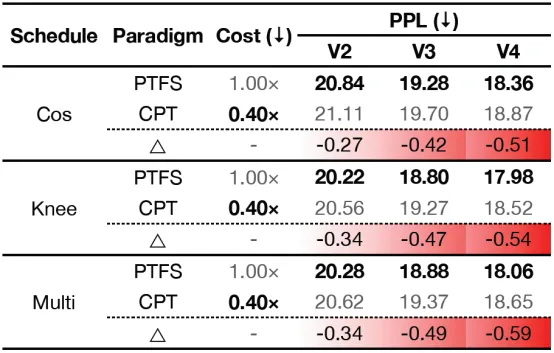
如表所示,相比于PTFS,CPT仅需要40%的成本就能训练得到4个版本的LLMs,但训练得到的LLMs的性能明显不如PTFS。此外,随着版本数的增大,PTFS和CPT的性能差距逐渐增大,这种性能差距在实际应用中是无法接受的。因此,我们在对LLMs进行版本更新时,不得不在性能和成本上进行取舍。那么,是否存在能更好地平衡版本更新时LLMs的性能和成本的训练范式,我们针对此问题展开研究。
在找到更好的训练范式之前,我们需要先探索PTFS和CPT性能差距逐渐增大的原因。为此,我们从学习率的角度展开研究。我们把CPT分成1) 确定初始化checkpoint,和2) 基于该checkpoint的继续预训练两个阶段,分别探索学习率对这两个阶段的影响。具体而言,我们基于Cosine学习率调度策略设计了以下两组实验。在这两组实验中,第一阶段采用10K步的训练以生成初始checkpoint;在第二阶段,我们基于第一阶段得到的checkpoint进行10K步的继续预训练。
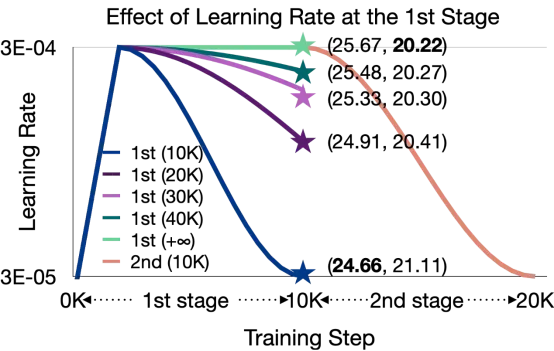
如上图所示,我们在固定CPT第二阶段训练的前提下,调整第一阶段训练的Cosine学习率调度策略的总衰减步数。图中括号内的两个数值分别表示第一阶段和第二阶段训练结束后对应的LLMs的困惑度(PPL)。我们发现,随着第一阶段Cosine学习率调度策略的总衰减步数的增加,训练过程中LLMs使用的学习率平均值也相应提高。在这种情况下,初始化checkpoint对应的LLMs的性能下降,但更新后的LLMs性能得到提升。因此,我们可以得出下述结论:第一阶段的大学习率有利于第二阶段的继续预训练。
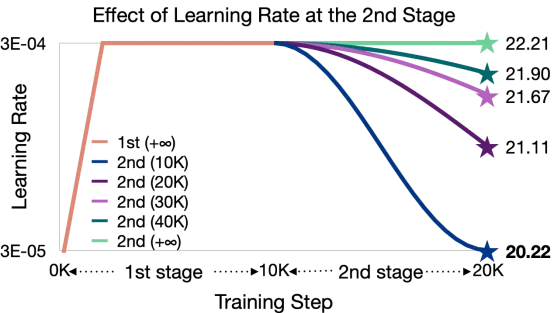
基于上述结论,我们固定第一阶段的学习率为最大值(3E-04),然后调整第二阶段的Cosine学习率调度策略的总衰减步数。上图的数值表示CPT训练结束后LLMs的PPL。如图中的结果所示,当第二阶段选取最小的总衰减步数时(对应图中深蓝色的学习率曲线),即LLMs训练结束时学习率正好衰减至最小值(3E-05),更新后的LLMs取得最佳性能。因此,我们可以得出下述结论:第二阶段完整的学习率衰减过程有利于提升LLMs的性能。
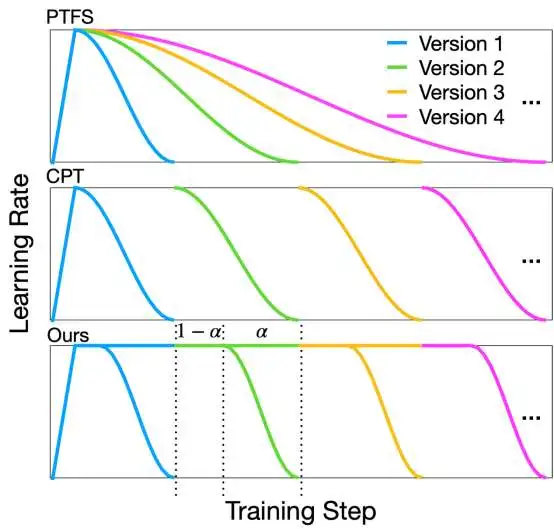
上图分别展示了PTFS、CPT和我们提出的范式应用于Cosine学习率调度策略的学习率曲线。特别地,我们的范式也适用于其它学习率调度策略,如Knee和Multi-Step等。如图所示,我们的范式的学习率曲线由一条主路径和多条分支路径组成,每条分支路径对应一次版本更新。在主路径上,LLMs以最大学习率从头开始预训练,为后续版本更新提供初始化checkpoint。当我们想获得新版的LLMs时,可以直接基于主路径的当前checkpoint继续预训练。在这个过程中,学习率会经历一个完整且快速的衰减过程,从而以较低的成本来保证新版LLMs的性能。同时,在主路径上我们仍然使用新增数据对当前checkpoint以最大学习率进行预训练,以便于后续的版本更新。显然,我们的范式比PTFS的训练成本更低,因为不同版本的LLMs都是基于主路径的初始化checkpoint进行继续预训练所得到的。与CPT不同的是,这些初始化checkpoint是以最大学习率从头开始预训练获得,这使得更新后的LLMs可以取得更好性能。
更进一步地,我们对比分析了不同范式的时间复杂度。为此,我们首先引入两个符号:1) : LLMs的版本更新次数;2) : 每次新增的训练步数。在更新第个版本的LLMs时,PTFS需要每次更新步,CPT需要训练步,而我们的范式需要训练步,其中控制每次更新中快速衰减步数占总步数的比例,一般设置为0.6。
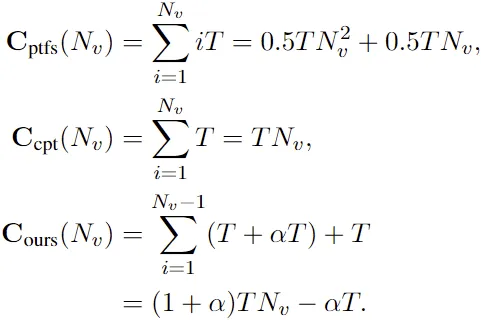
如上述复杂度函数所示,是的二次函数,而和则是一次函数。这表明,CPT和我们的范式的训练成本属于同一量级。相比于PTFS而言,CPT和我们的范式在训练成本方面的优势会随LLMs版本数增大而逐渐扩大。
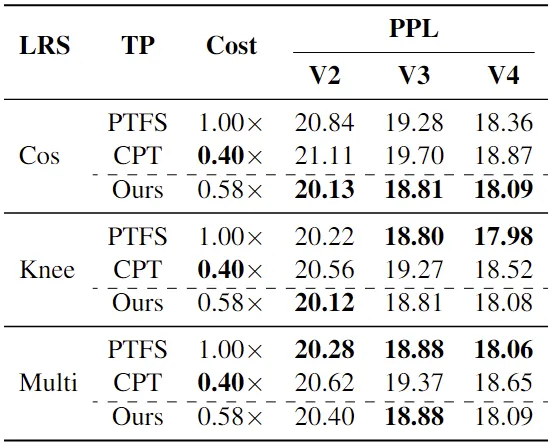
从上表我们可以看出,我们的范式在保持与PTFS相当性能的同时,将总训练成本降低至58%。与CPT相比,我们在使用同一量级的训练成本的同时,取得更优的性能(更多对比实验详见原论文)。总的来说,对于LLM的版本更新,我们的范式在预训练性能和总训练成本之间取得了更好的平衡结果。
1.我们对比了PTFS和CPT在版本更新方面的性能,深入探索两者性能差距逐渐增大的原因,发现第一阶段的大学习率和第二阶段完整的学习率衰减过程对CPT至关重要。
2.我们为LLMs的版本更新提出了一种基于学习率路径切换的训练范式。据我们所知,这是第一个尝试探索如何平衡LLMs版本更新的模型性能和训练成本的研究。
3.实验结果和深入分析有力地证明了我们范式的有效性和泛化性(更多实验结果详见论文)。在训练4个版本的LLMs时,我们的范式仅用58%的总训练成本就实现了与PTFS相当的预训练性能。
文章来自于微信公众号“夕小瑶科技说”,作者“王志豪”




