# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
登上油管热榜,吸引50万网友围观,波士顿动力人形机器人又放大招了——
无远程遥控(Fully Autonomous),Atlas可完全自主打工了。
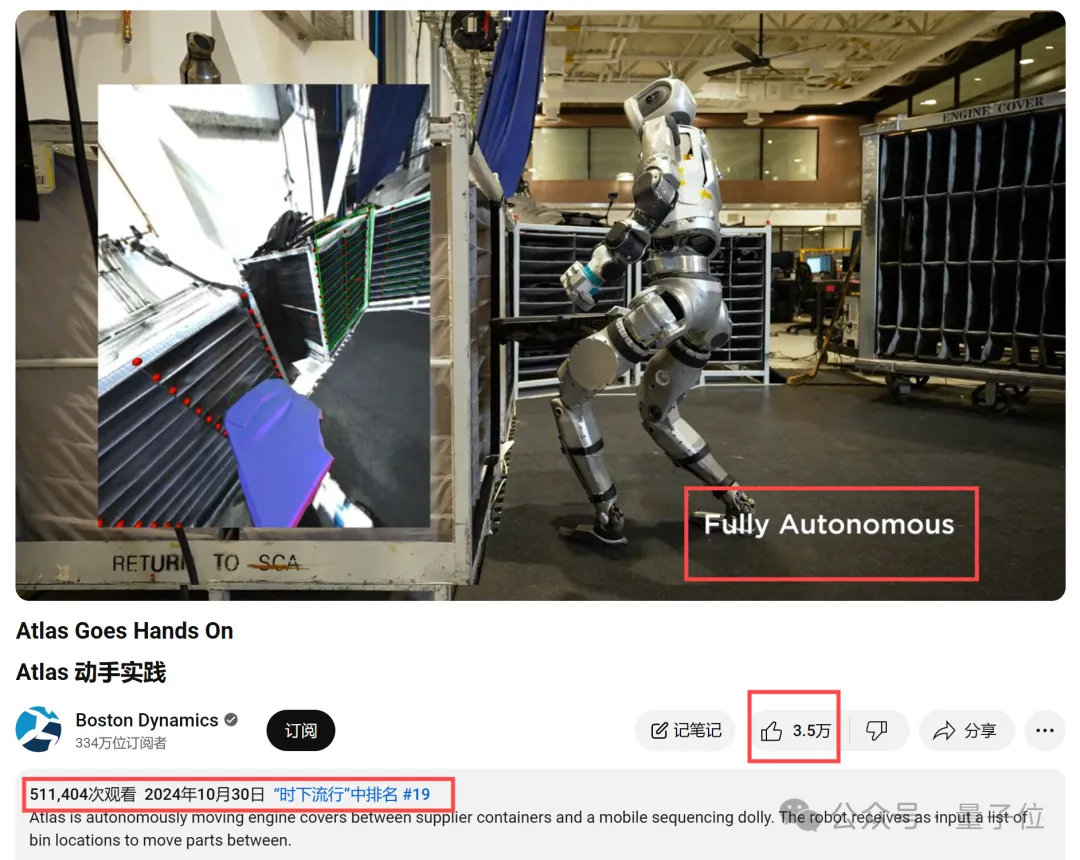
只需告诉Atlas前后搬运的位置坐标,它就能全自动分装物件,动作be like:

而在Atlas的第一视角下,它看到的是酱紫的:

面对“刁难”(物件在底层位置),Atlas直接一个帅气下蹲,再次成功完成任务。

更有意思的是,当发现自己弄错位置后,Atlas突然以一个鬼畜完成了瞬间纠错。(笑死,怪突然的)

总之,在近3分钟demo中,Atlas进行了一系列秀肌肉操作:头部、上半身、髋关节都能360°旋转,可随时转向、倒退行走……

有网友惊呼,其他机器人还在学走路,Atlas已经开始朝九晚五,甚至007式打工了!
同行(通用仓库机器人nimble ai创始人)大赞:Atlas已经遥遥领先了。
只有机器人专家才知道Atlas有多棒
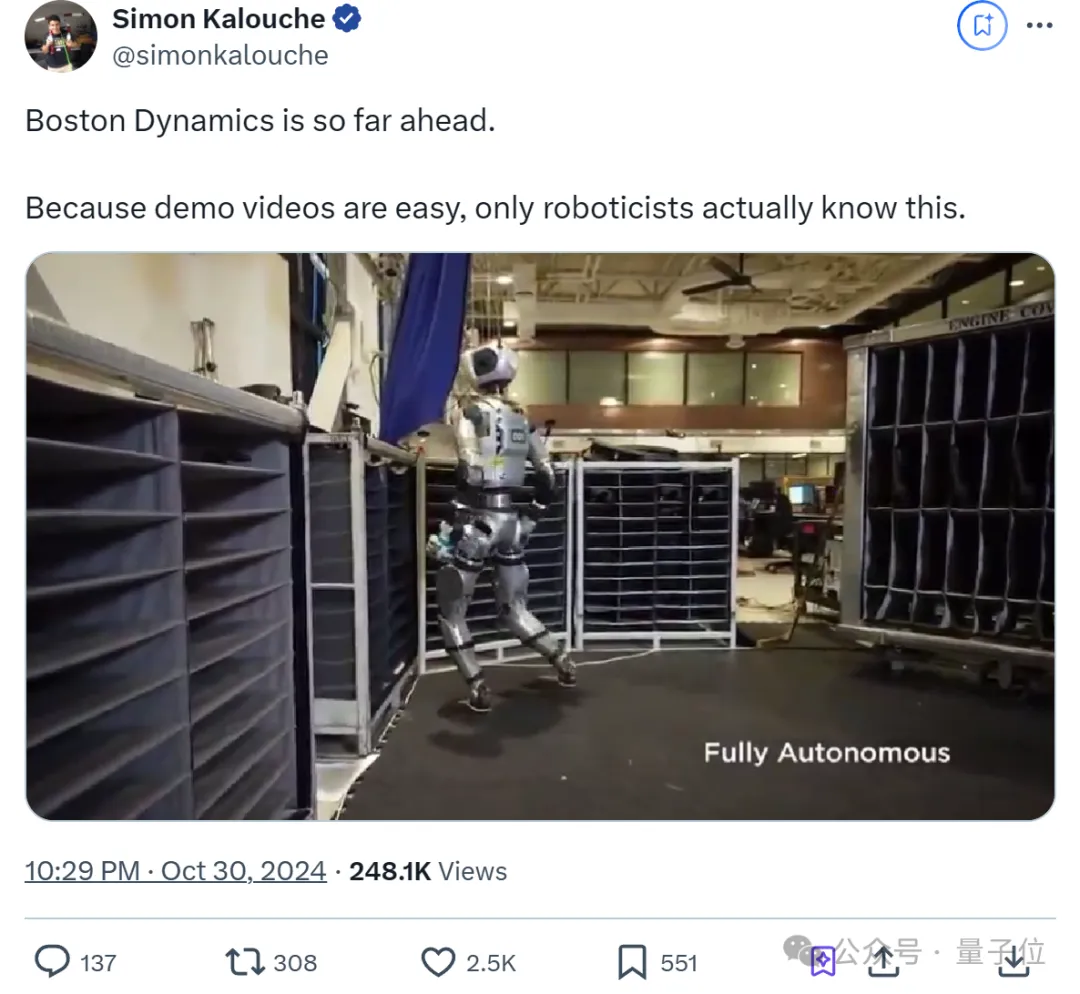
自从今年4月宣布改液压为电驱后,这是波士顿动力人形机器人为数不多的露面。
上一次还是8月底,他们展示了Atlas能够一口气做俯卧撑、深蹲等热身运动,当时就震惊了上百万网友。

而在最新demo中,Atlas又瞄准了自动化控制,现在它能在集装箱和移动小车间自主移动发动机盖了。
据波士顿动力介绍,Atlas使用机器学习视觉模型来检测和定位环境固定装置和单个箱子,并且会使用专门的抓取策略,通过不断估计被操纵物体的状态来完成任务。
机器人能够结合视觉、力和感知来检测环境变化(如移动固定装置)和动作故障(如未能插入盖子、绊倒、环境碰撞)并做出反应。

看完一系列最新表现,果不其然又惊倒了一片网友:
完全自主?现在你引起了我的注意
网友们也是纷纷cue起了特斯拉人形机器人Optimus~
前一阵,Optimus在特斯拉的发布会上同样大秀肌肉(开场热舞、与人交谈猜丁壳、倒酒等一个不落),不过最后被多方证明存在现场远程操控。
后来特斯拉也发布了一个展示Optimus自主导航的demo:
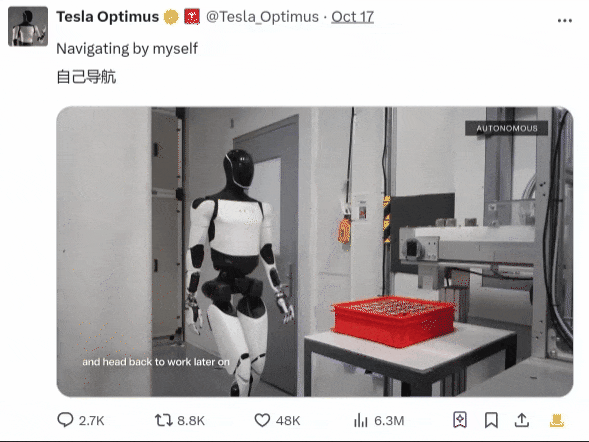
对于这两家人形机器人领域同样炙手可热的竞争对手,网友们也开始各自站台,并最终达成了一个“共识”。
二者的差距在于量产。波士顿动力单兵能力强,而特斯拉在商业化量产方面更具优势。
背后的逻辑也很简单,人形机器人最终还是要走向消费市场。
不过不管怎样,Atlas展现的细节已十分惊艳,比如可以360°旋转的身体、头部。
虽然也有人吐槽这很诡异,不过大多数人表示看好:
人形机器人能够被设计而不是进化,意味着一旦我们弄清楚工程原理,各种变形金刚和驱魔人式的能力都可能发生。
另外,还有人疑惑为什么Atlas不搞个360°全景摄像头,还需要转动头部呢?
对此,有网友推测最大原因还是控成本。
更高分辨率的深度相机价格昂贵(带宽和计算),因此将超密集传感器限制在工作空间的位置是很有意义的。
实在不行,也可以“低质量的360°全景视觉+面向单一方向的高质量相机/激光雷达”(网友支招有)。
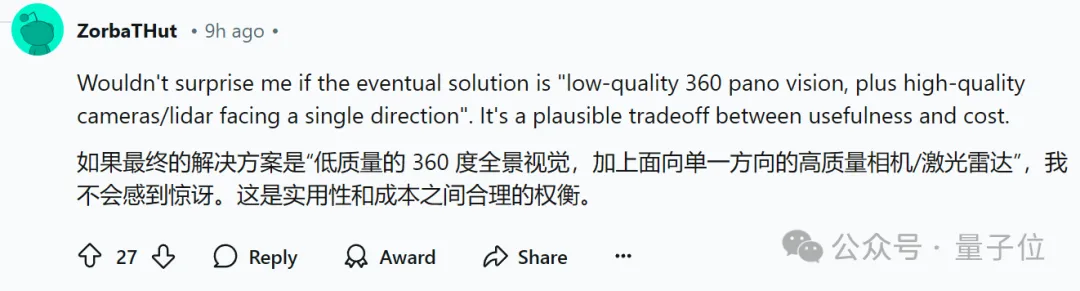
在reddit网友一片热议中,部分网友发出了灵魂拷问:
机器人完成这种任务(分装物件)好像没啥大意义?能不能更贴近现实生活。
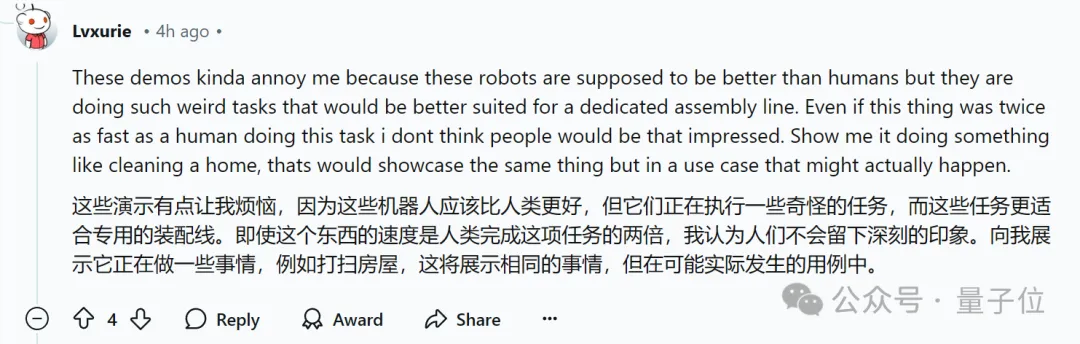
对此,也有人对Atlas采用的技术表达担忧:基于点和规划器/优化器在泛化能力上可能不如神经网络等。

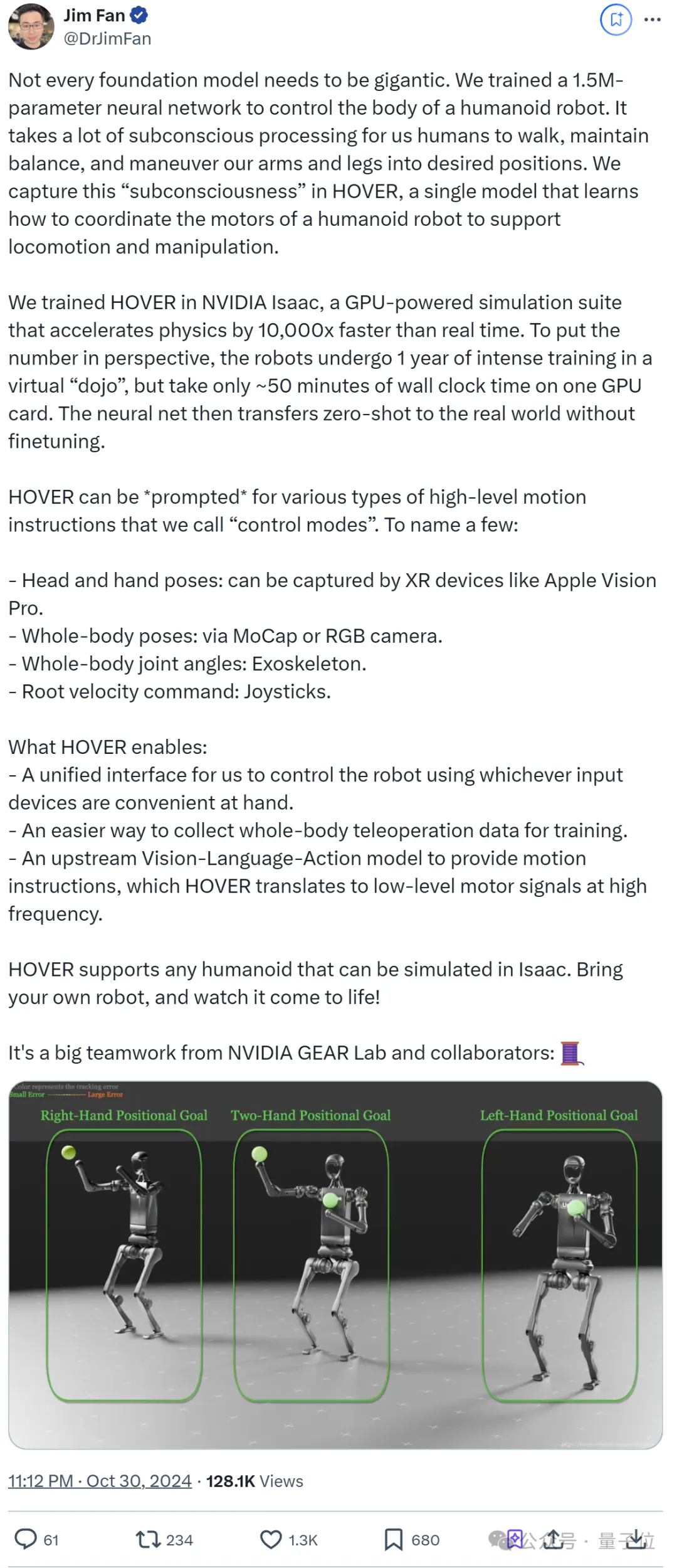
且就在刚刚,英伟达新发布了HOVER,一个1.5M参数的神经网络控制器,用于人形机器人的全身运动和操作协调。
据负责英伟达具身智能实验室(GEAR)的Jim Fan介绍:
人类在行走、保持平衡以及操纵四肢到达期望位置时,需要大量的潜意识处理。我们在HOVER中捕捉了这种“潜意识”,这是一个单一模型,学习如何协调人形机器人的电机以支持运动和操纵。
我们在NVIDIA Isaac中训练了HOVER,这是一个GPU驱动的仿真套件,能够实现比现实时间快10000倍的物理模拟速度。
为了直观理解这个数字,机器人在虚拟“道场”中经历了一年的密集训练,但在一块GPU卡上仅花费了大约50分钟的真实时间。然后,神经网络无需微调即可零样本迁移到现实世界。
简单说,HOVER可以被“提示”执行各种指令,英伟达称之为“控制模式”。比如:
概括而言,HOVER提供了一个统一接口,允许使用任何方便的输入设备来控制机器人。
它简化了收集全身遥控操作数据的方式,以便于训练;且作为一个上游的视觉-语言-动作模型,只要提供运动指令,HOVER就能将其转换为高频的低级电机信号。
对此,你怎么看?
参考链接:
[1]https://www.youtube.com/watch?v=F_7IPm7f1vI
[2]https://www.reddit.com/r/singularity/comments/1gfmytj/new_creepy_atlas_video_dropped/
[3]https://twitter.com/simonkalouche/status/1851632608171679817
文章来自于微信公众号“量子位”,作者“一水”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
