# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

介绍:
https://microsoft.github.io/OmniParser/
代码:
https://github.com/microsoft/OmniParser
论文:
https://arxiv.org/abs/2408.00203
OmniParser 是由微软研究院提出的一个创新性工具,旨在通过解析用户界面截图来增强基于视觉的图形用户界面(GUI)代理的性能。
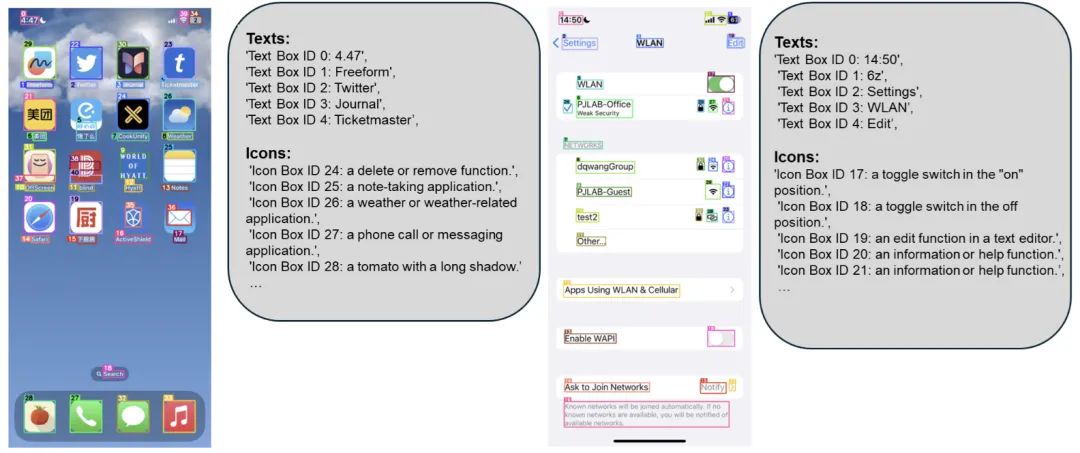
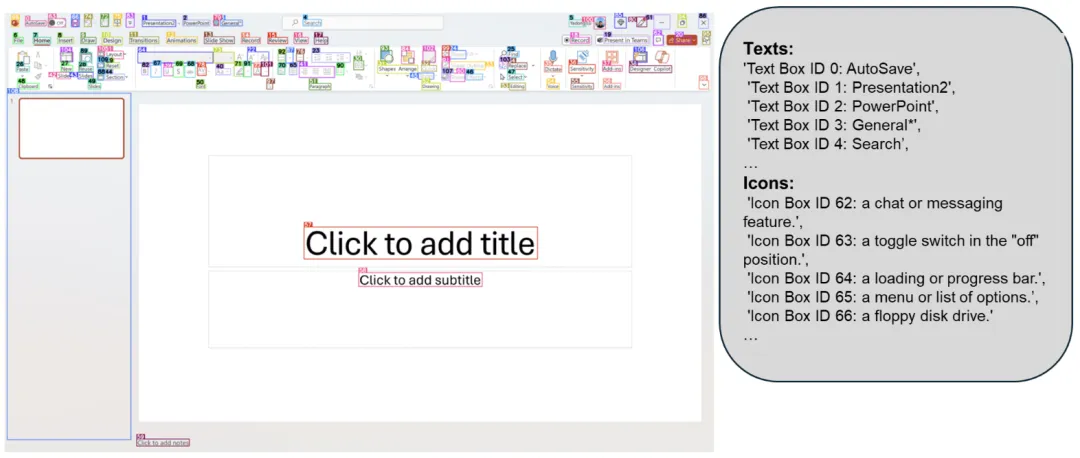

该工具通过识别用户界面中的可交互图标,并理解截图中各种元素的语义,解决了以往多模态模型在跨操作系统和应用程序中应用时的局限性。OmniParser 通过结合微调后的检测模型和描述模型,将截图转换成结构化的元素,显著提升了GPT-4V模型在执行各种用户任务时的准确性和鲁棒性。
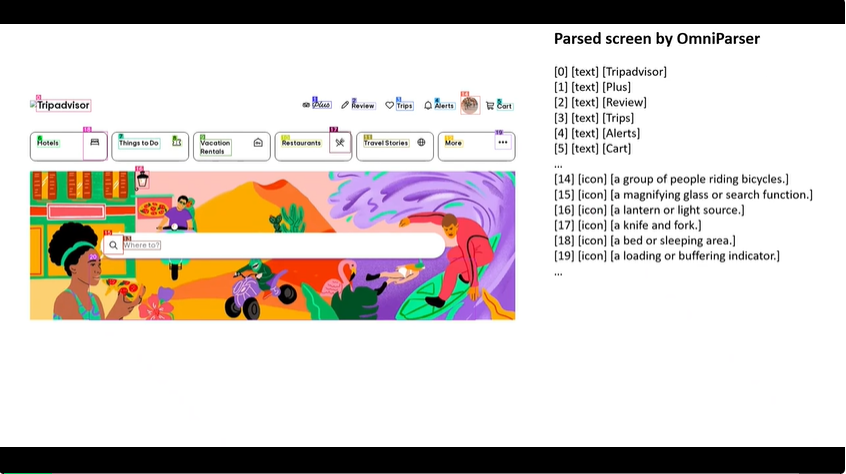
OmniParser 的特点在于其能够处理来自不同平台和应用程序的截图,而无需依赖于额外的信息,如HTML或视图层次结构。它通过一个检测模型来识别屏幕上的可交互区域,并使用一个描述模型来提取这些元素的功能语义。此外,OmniParser还整合了光学字符识别(OCR)模块,以进一步提高对用户界面的理解。在多个基准测试中,OmniParser都显示出了其卓越的性能,证明了它在提高GUI代理的行动预测能力方面的有效性。
OmniParser 的思路是将用户界面截图转化为结构化元素,从而提高GUI代理在执行任务时的准确性和效率。这一过程涉及到对截图中可交互图标的识别、元素功能语义的理解,以及将这些信息以结构化形式整合,使得大型视觉语言模型如GPT-4V能够更可靠地将预测的行动转换为屏幕上的具体操作。
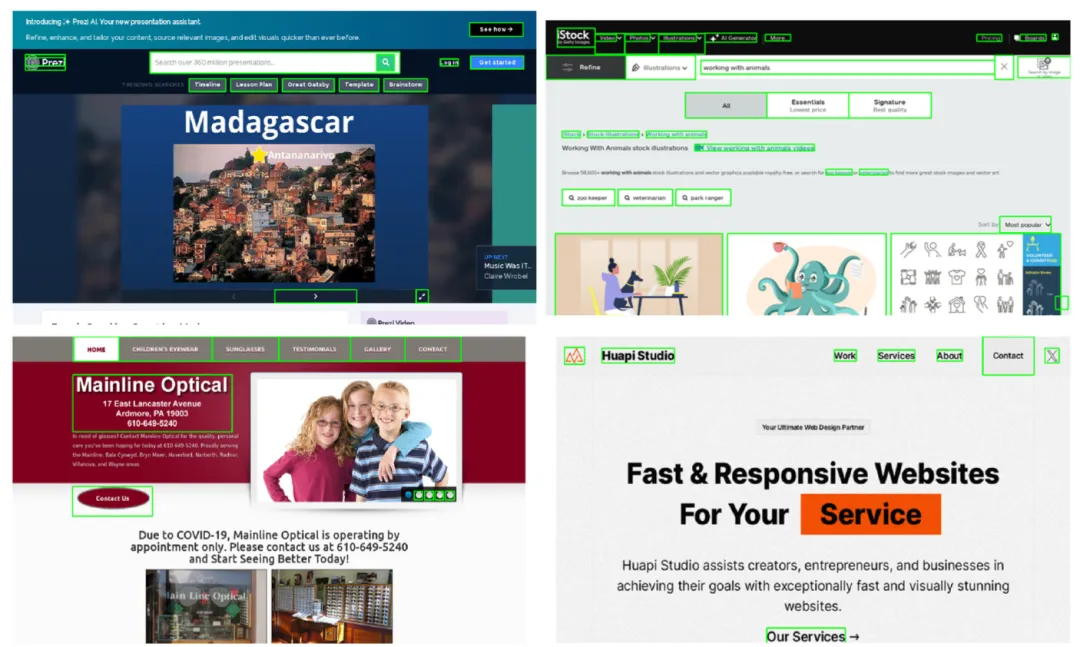
OmniParser 的处理过程包括以下关键步骤:
OmniParser 的技术特点在于其纯视觉的处理方式,不依赖于HTML或其他额外信息,使其能够跨平台、跨应用程序地工作。它通过提供更精确的可交互元素检测和结合功能语义,显著提高了GPT-4V在多个基准测试中的性能。
总的来说,OmniParser 为构建跨平台和跨应用程序的通用GUI代理提供了一种有效的解决方案。它不仅提高了现有模型的性能,还拓宽了这些模型的应用范围,使其能够在更广泛的环境和任务中发挥作用。
这篇论文介绍了OmniParser,这是一个用于解析用户界面截图的工具,旨在提高基于视觉的图形用户界面(GUI)代理的性能。
以下是论文内容要点:
摘要:
引言:
相关工作:
方法:
实验与结果:
讨论:
结论:
文章来自于“ADFeed”,作者“ADFeed”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
