# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
SELA 由 MetaGPT 开源社区合著,作者分别来自 DeepWisdom、UC Berkeley、港科广、UCSD、华师、Stanford、港中深、Montreal & MILA 等机构。共同一作池一舟与林义章分别任职 DeepWisdom 实习研究员与研究员,他们均毕业于 UC Berkeley,林义章也是 Data Interpreter 的共同一作。共同通讯作者为 DeepWisdom 创始人兼 CEO 吴承霖(MetaGPT 代码作者、论文通讯作者)和蒙特利尔大学与 MILA 实验室的助理教授刘邦。

AI 智能体可以设计 AI 吗?
当然可以!
SELA 用 MCTS 设计 AI 效果在 20 个数据集上达到了 SoTA。它可以自己从历史设计与实验中学习,设计出比之前更好的 AI,并且完全开源。
过去,AI 模型的设计和优化依赖大量专业知识和人力,过程耗时,易受个人经验影响。尽管 AutoML 技术有所进展,但现有系统只会对预定义的搜索空间进行组合搜索,与人类行为不一致。人类会提出动态搜索空间并求解。随着大模型技术的发展,我们看到了大模型能自主设计和调优 AI 模型的希望。然而,实现这一目标面临自主设计和持续调优两大挑战。
过去几个月,MetaGPT 团队开源的 Data Interpreter 能够自主完成多项机器学习任务,通过增强任务规划、工具集成和推理能力,提升了成功率,但缺乏持续性调优。weco.ai 团队的 AIDE 引入了结果反馈,在 OpenAI 发布的 MLE-bench 中表现优异,但由于采用贪婪搜索,往往只收敛到次优结果。
SELA 由 MetaGPT 团队联合多所顶尖机构推出,是一个可以进行自动实验的智能体。它全面超越了 AIDE 和 Data Interpreter ,在多项机器学习测试中表现卓越,展现出自动化设计与优化 AI 模型的巨大潜力。

相比于传统 AutoML 框架和基于 LLM 的自动机器学习系统,SELA 可以动态地构造搜索空间,而不是基于一个固定的搜索空间进行搜索,在动态流水线构造表现出了显著优势。

同时,就像 AlphaGo 会根据棋局中对手的动作不断提升,SELA 也会逐渐在多步中完成机器学习代码,解决了 AIDE 只能进行一步优化的问题。

下方动图展示了 SELA 在医疗数据集(smoker-status)上的搜索过程,我们可以清晰地看到 SELA 在机器学习任务的各个阶段进行了多次深入探索。随着探索轮次的增加,节点的颜色逐渐加深,这象征着得分的持续提升。
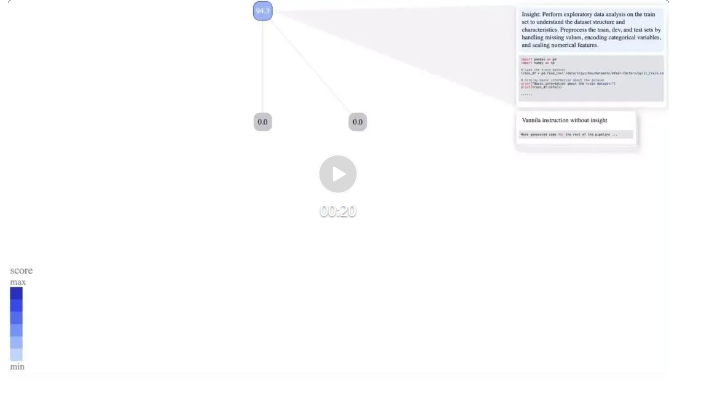
具体来看,SELA 从最初的解决方案 94.3(根节点)出发,通过探索性数据分析,敏锐地捕捉到数据集中潜藏的异常值,并通过数据预处理环节,移除了这些异常值,将得分提升至 96.3。随后,SELA 在另一次实验中,通过相关性分析,精准地剔除了冗余特征并降低了数据维度,使得得分跃升至 97.2。
SELA 通过将问题描述和数据集信息输入 LLM,生成潜在解决方案的搜索空间,并由 Monte Carlo Tree Search(MCTS)进行探索。LLM Agent 进一步规划、编码和执行实验,利用模拟反馈优化搜索,形成迭代过程,最终产生优化的实验管道。这种方法模拟了人类专家的迭代和反馈驱动过程,提升了机器学习任务的性能和适应性。
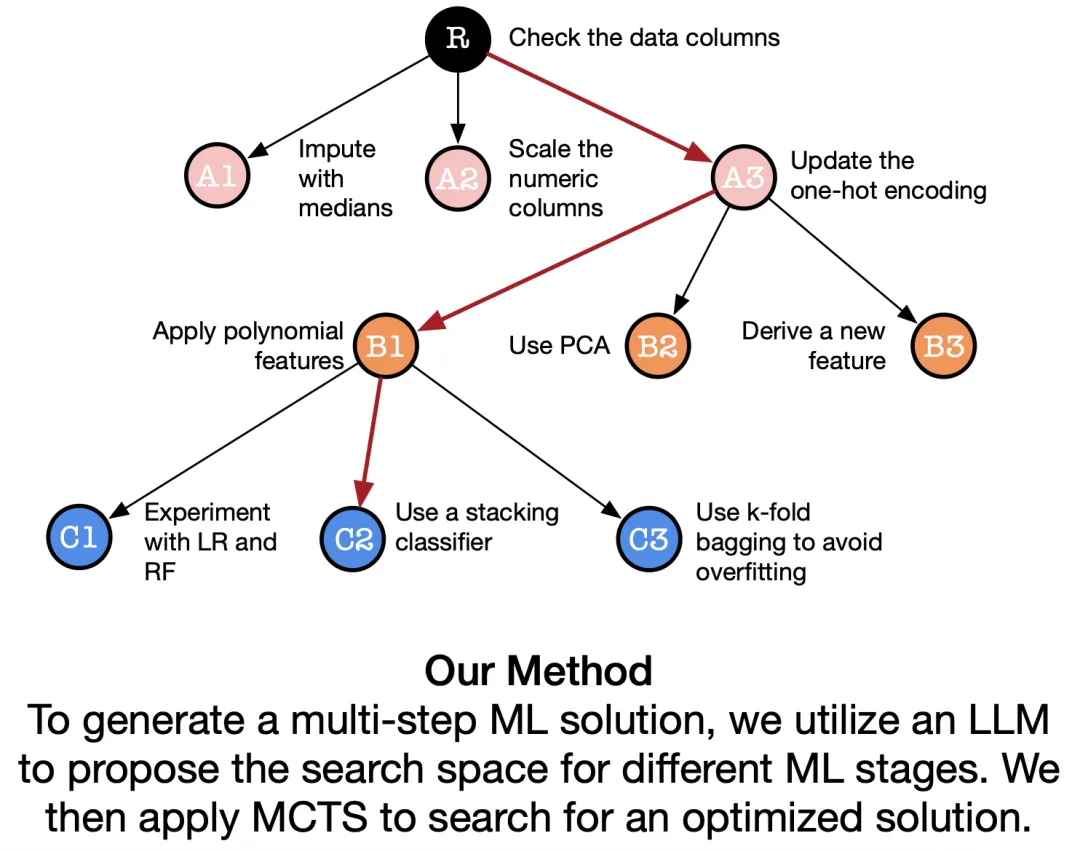
在上面的流程中,研究者们提出了三个重要组件,分别是 1)基于 LLM 的 Insight Proposer;2)基于 MCTS 的搜索策略;3)执行实验方案的 LLM Agent,下面我们会详细展开组件设计:
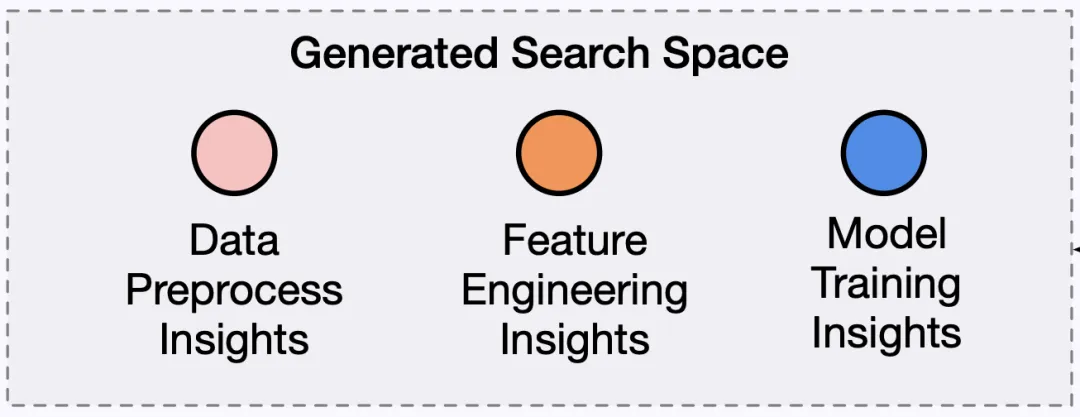
Insight Proposer 负责接收问题描述和数据集信息,将机器学习过程细分为探索性数据分析、数据预处理、特征工程、模型训练和模型评估五个关键阶段。并利用大型语言模型为每个阶段生成多样化的 Insight。这些 Insight 被汇集在见解池中,构建起 SELA 的搜索空间。
在 SELA 框架中,研究者们将解决机器学习问题的搜索空间看作一棵树,每条从根到目标节点的路径都表示一个由 Insight 组成的实验配置。因此,寻找最佳解决方案的任务可以被视为在树中搜索最优路径。
SELA 采用蒙特卡洛树搜索(MCTS)作为核心决策引擎,通过选择、扩展、模拟和反向传播四个关键步骤,高效地探索和优化解决方案。
在每次迭代中,SELA 使用 UCT 算法的修改版本 UCT-DP ,从搜索树中选择一个节点。与传统的 MCTS 不同,SELA 面临的挑战在于模型训练等过程引入的大量计算时间,因此高效的节点探索至关重要。SELA 通过尽早优先探索更深入的节点,减少了探索每个未访问节点的需要,允许在更少的迭代中到达更深的节点,使该方法更适合大规模机器学习实验。
在扩展阶段,将从所选节点实例化一组子节点以进行模拟,子节点继承了父节点的所有属性,并在此基础上增加了新的洞察,以进一步探索和优化解决方案。
扩展结束后,SELA 将从扩展的子节点中随机采样一个节点进行模拟,SELA 将首先获取这条路径对应的配置。这些配置随后被交给负责实验的 Agent 执行,产生模拟分数,该分数作为反向传播的反馈。
在模拟结束后,SELA 会收集性能分数(例如,基于验证集的分数),并通过树结构进行反向传播。这些分数从模拟节点传递到根节点,更新每个父节点的值和访问计数,从而在未来的搜索中优先考虑那些代表更有前途解决方案的节点。同时,解决方案代码也会反向传播到树中,并在更新期间根据父节点进行处理,保存为阶段代码。
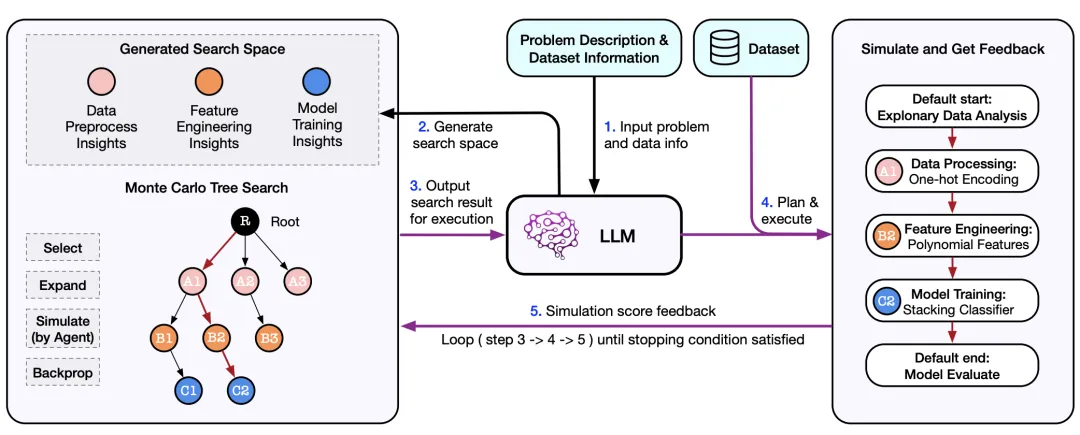
SELA 设计了一个 LLM Agent 用于执行实验方案,通过自然语言需求构建实用的 pipeline。Agent 首先将搜索模块提供的 Insight 转化为详细计划,然后根据计划编写并执行代码,生成最终的 Pipeline 和执行分数。为提升效率,SELA 在阶段级别进行代码缓存,实现精细的代码重用,避免重复劳动,并应对 LLM 的非确定性问题,确保实验的一致性和可预测性。
SELA 选取了 AutoML 的 13 个分类任务和 7 个回归任务,以及 Kaggle 竞赛的 20 个数据集进行评估。
所有数据集按相同比例切分,确保各框架接受相同数据。基于 LLM 的框架(SELA、Data Interpreter 和 AIDE)采用相同配置和迭代次数。AutoGluon 和 AutoSklearn 均使用默认设置。由于 AutoGluon 结果是确定性所以只运行一次,其余实验均运行三次。我们对每个数据集上不同框架的全部运行结果进行排名,以比较优劣。
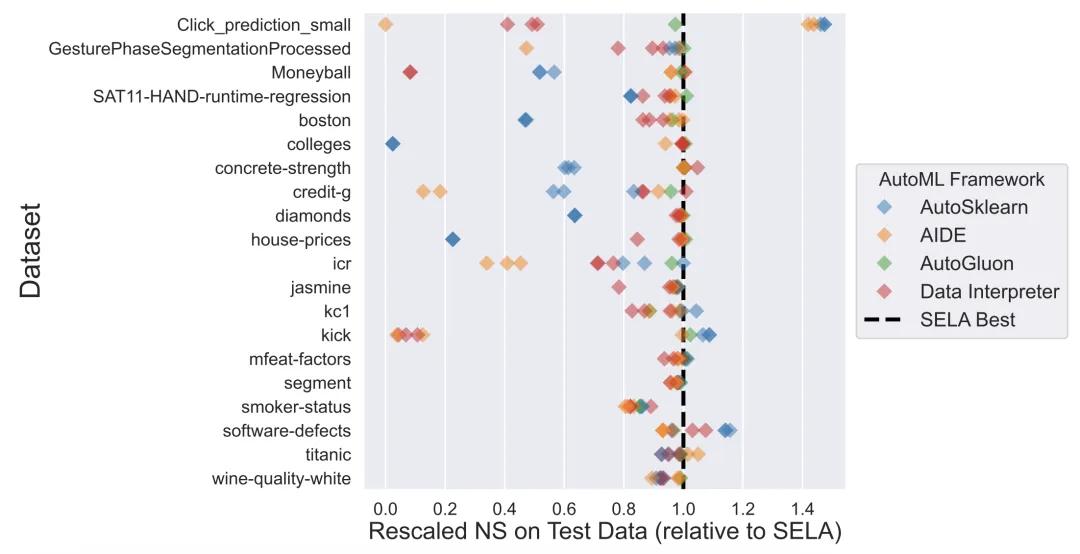
图中展示了多个自动机器学习框架在不同数据集上的预测表现,横轴为与 SELA 最佳性能相比的标准化得分(NS)。结果显示,SELA 在大多数数据集中表现优异,其他框架如 AutoSklearn、AIDE、AutoGluon 和 Data Interpreter 在某些数据集上有竞争力,但整体上 SELA 展现出更为一致的高性能和适应性。

SELA 在所有框架中取得了最高的平均标准化分数和最佳排名,证明了其在多种数据类型和任务上的稳健性和卓越表现。
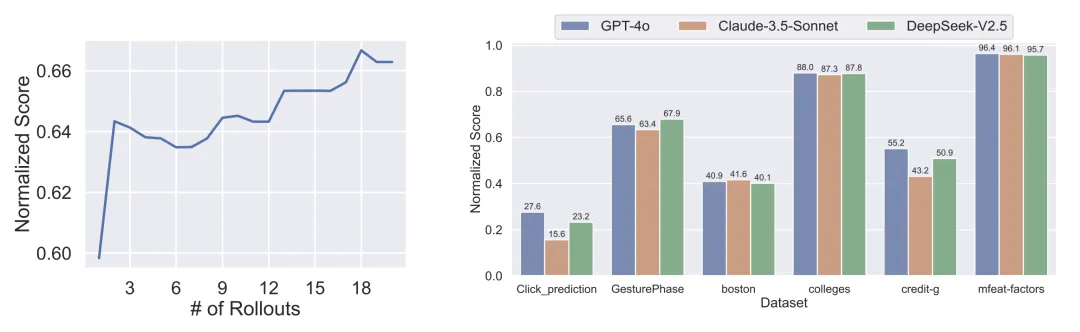

研究者们设计了三个消融实验,用来验证 SELA 性能和策略的有效性。首先,是对探索次数的消融。实验结果显示,随着探索次数的增加,SELA 有效利用了更多的探索机会,使平均性能显著提升。
其次,LLM 的消融研究对比了 GPT-4o、Claude-3.5-Sonnet 和 DeepSeek-V2.5,结果表明 Claude-3.5-Sonnet 和 GPT-4o 表现稳定且适应性强,而 DeepSeek-V2.5 在某些数据集上略逊色,但在 Click prediction 和 boston 数据集上表现相近,充分说明 SELA 在不同模型上均有出色表现。
此外,研究者们进一步验证了 SELA 所采用的 MCTS(蒙特卡洛树搜索)策略的卓越有效性。相较于 DataInterpreter(无搜索)和随机搜索,MCTS 策略展现出了显著的优势,这证明 SELA 最终采用的搜索策略是必要且有效的。
SELA 提出了一种让 AI 自主设计和持续优化自身的方法,并全面地展示了其取得的不俗效果。研究者们认为,该工作表明了 AI 在这一方向的潜力,将为未来的相关研究提供有价值的参考。
文章来自于微信公众号 “机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
