# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本篇论文已经被NeurIPS 2024接收。第一作者王方懿康是微信视觉团队实习生,同时也是浙江大学一年级硕士研究生。共同一作是微信高级研究员Hubery。通讯作者是浙江大学助理教授张超。其他作者包括来自清华大学的董玥江,来自浙江大学的朱胡旻昊,赵涵斌助理教授和钱徽教授,以及微信基础视觉和视觉生成技术负责人李琛。
随着扩散生成模型的发展,人工智能步入了属于 AIGC 的新纪元。扩散生成模型可以对初始高斯噪声进行逐步去噪而得到高质量的采样。当前,许多应用都涉及扩散模型的反演,即找到一个生成样本对应的初始噪声。当前的采样器不能兼顾反演的准确性和采样的质量。
为彻底解决这一问题,微信视觉团队与浙江大学和清华大学联手提出了基于双向显式线性多步法的扩散模型精确反演采样器(BELM)这一通用算法,并通过截断误差分析确定了最优的 BELM 采样器系数。此方法在确保精确反演的同时还提升了生成样本的质量,在图像与视频的编辑、插值等下游任务中有广泛的应用前景。这一研究成果已被 NeurIPS 2024 会议接收。
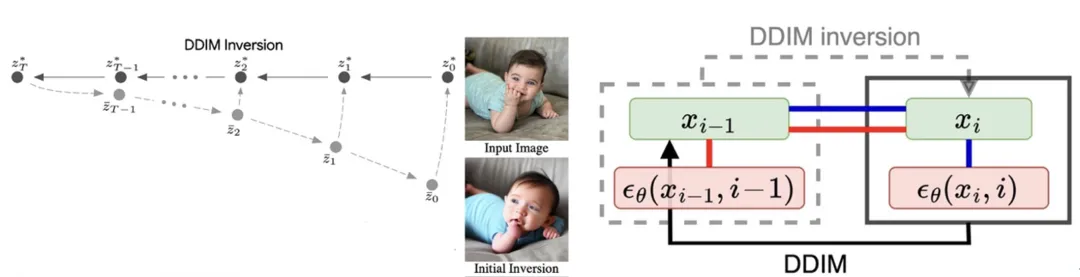
当前,扩散模型在图像生成、文字生成、音频生成等多个领域得到了广泛应用,表现出了卓越的性能。扩散模型的反演操作,即找到一个生成样本对应的初始噪声,对若干下游任务起到关键的作用。传统的 DDIM 反演会造成严重的不一致问题,即原始图片加噪再去噪的结果与原图相差甚远。
近期,研究者们提出了多种启发式的精确反演采样器来解决 DDIM 反演的不一致问题。然而,这些启发式的精确反演采样器的理论特性尚不明确,且采样质量常常不尽如人意,这在一定程度上限制了它们的应用。
为此,本研究引入了一种通用的精确反演采样器范式 —— 双向显式线性多步(BELM)采样器,该范式包含了上文提到的启发式精确反演采样器。该团队在 BELM 范式内系统地研究了局部截断误差(LTE),发现现有的精确反演采样器的 LTE 并非最优。
因此,研究团队通过 LTE 最小化方法提出了最优的 BELM(Optimal-BELM,O-BELM)采样器。实验表明,O-BELM 采样器在实现精确反演的同时,也提升了采样的质量。

由于 DDIM 的正向过程和反演过程使用的迭代式并不相同,所以 DDIM 的反演重构样本与初始的样本存在较大差别。
实际使用中,DDIM 的反演有显著的不一致问题:

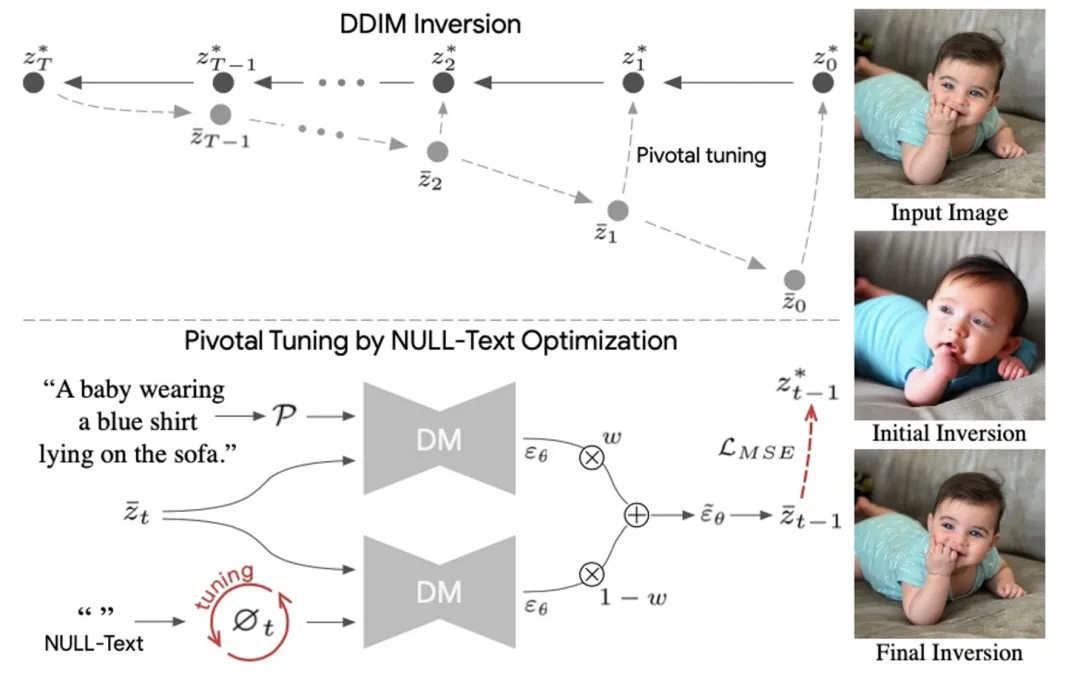
以 Null-tex-inversion 为代表的方法对 unconditional 占位符进行 fine-tune,以达到精确反演。
问题:这类方法局限于 text-classifier-free-guidance 场景下的扩散模型;需要额外训练,低效。
EDICT 是基于 DDIM 的启发式算法,借鉴了可逆网络的做法,有两个相互糅合的采样链。
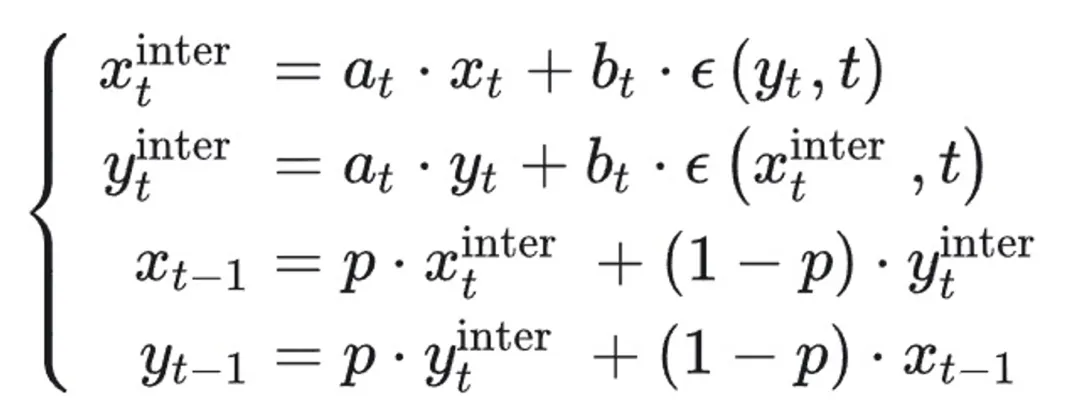
其逆过程如下,精确可逆:
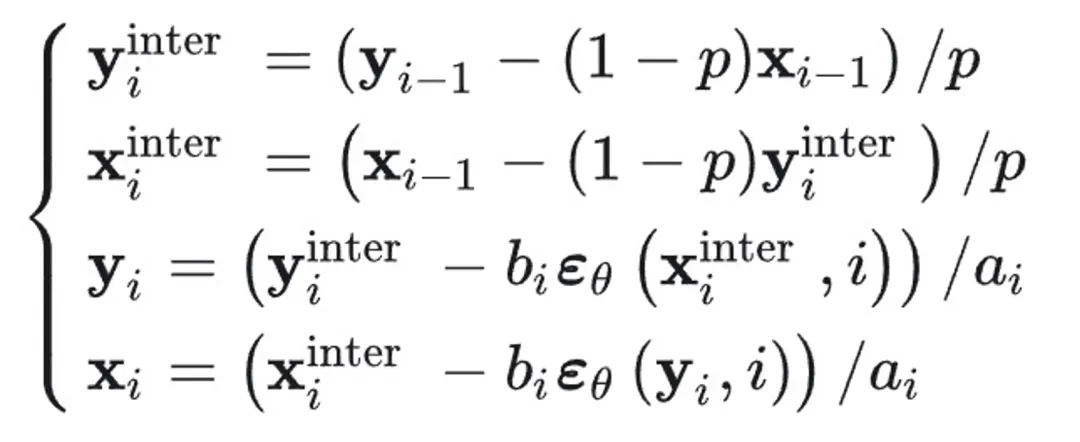
问题:需要两倍计算量;超参数 p 不鲁棒,导致采样质量不可控。
BDIA 改进了 EDICT,使用 x_i 的速度,x_i 和 x_{i+1} 的位置,通过下述公式实现精确可逆:
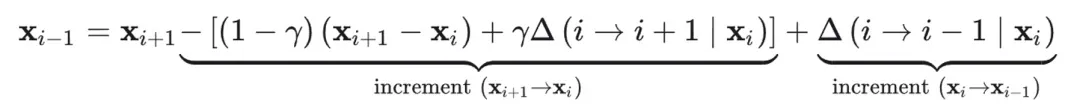
问题:超参数 gamma 不鲁棒,导致采样质量不佳。
EDICT 和 BDIA 超参数的意义不明,没有理论指导如何调整,导致不同情形下超参数的选择差别巨大。使用起来极为不便。

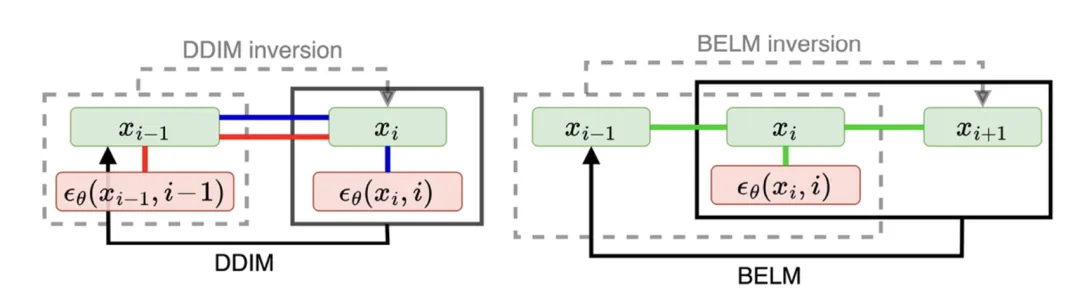
思路起源:DDIM 的正向过程(由蓝线表示)与反演过程(由红线表示)是两种不同的关系,这导致了 DDIM 的反演不准确。如果强制正过程与反过程使用相同关系,又会引入隐式方法,大大增加计算复杂度。如果多引入一个点,不用隐式方法也可逆(由绿线表示)。
该论文中的算法,正向和反演过程都服从相同的关系,因此能够精确反演。具体来说,为了系统地设计这种采样器,首先要将扩散模型的采样过程建模为一个 IVP(Initial Value Problem,初值问题):

以下是 IVP 的一般形式,这实际上是一个变步长变公式线性多步方法(VSVFM):
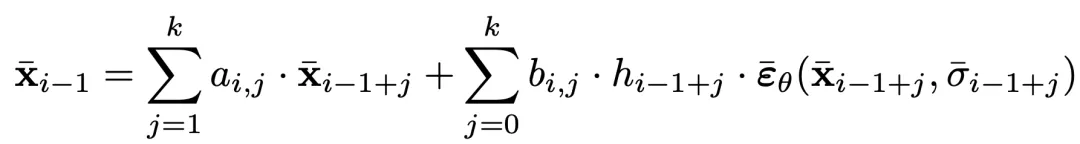
为了避免隐式方法的复杂计算,上式需要在正向和反向都是显式的,该团队称这一性质为双向显性(bidirectional explicit)。
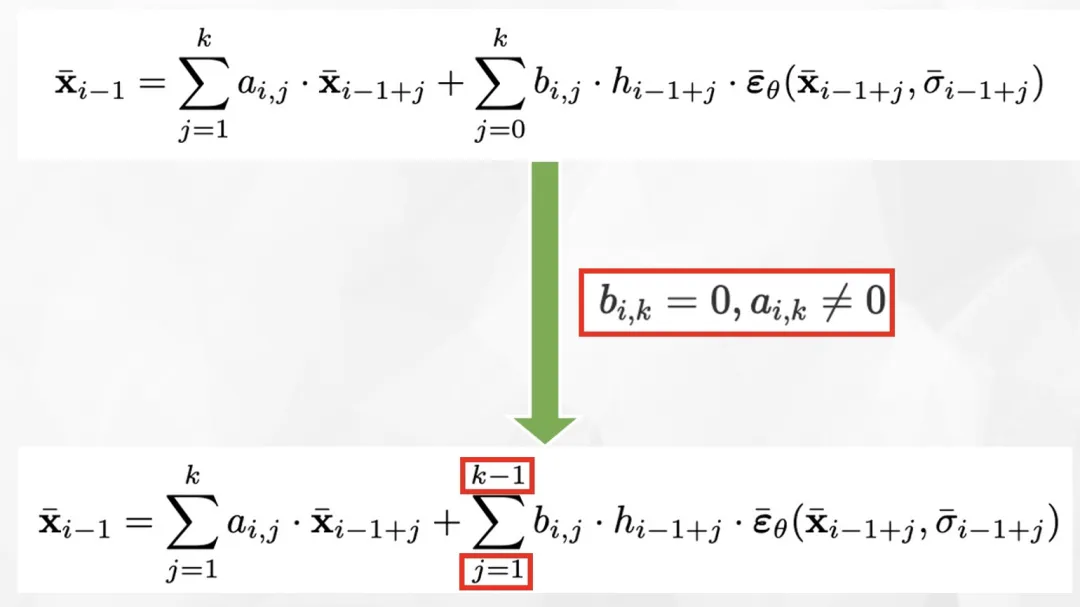
代入双向显性条件,可以得到一般的 k 步 BELM 采样器:
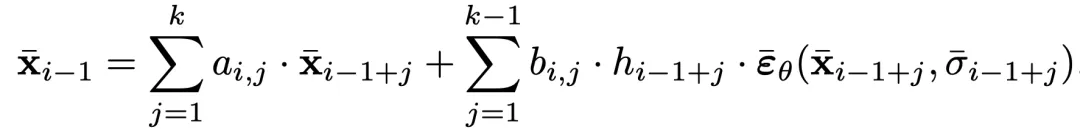
最简单的形式是 k=2,称为 2-BELM,其表达式如下:
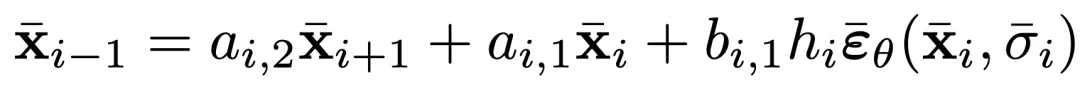
据此很容易证明,一个满足双向显性性质的线性多步法采样器拥有精确反演性质:
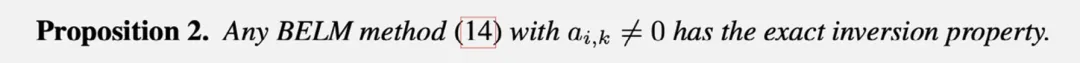
研究团队还发现,前文提到的 EDICT 和 BDIA 都是 BELM 框架的特例:
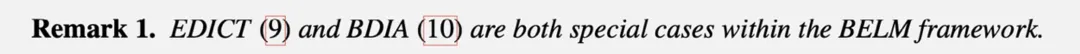
这也解释了 EDICT 和 BDIA 能够精确反演的原因。
研究团队在推导 BELM 框架暂时没有给出具体的系数选择,而启发式的系数选择(如 EDICT 和 BDIA)会造成采样质量的退化。因此,他们提出使用局部截断误差(LTE)来获取最优系数。
首先分析 BELM 的局部截断误差:
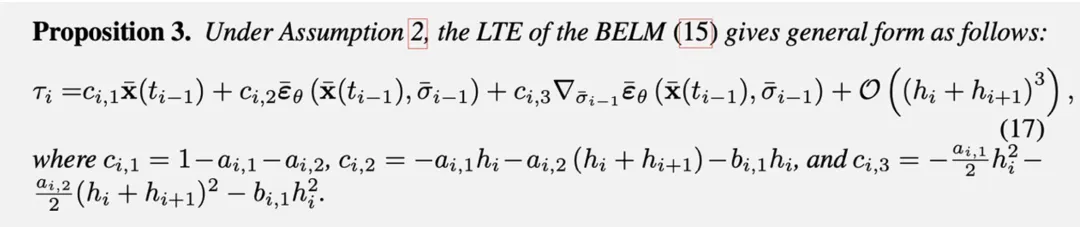
通过对局部截断误差的最小化,我们得到了最优的 BELM 系数,我们称此系数下的 BELM 采样器为最优 BELM(O-BELM):

O-BELM 的正向过程表达式如下:
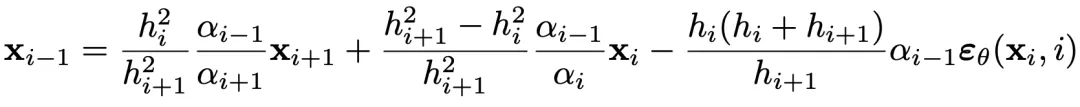
O-BELM 的反演过程表达式如下:
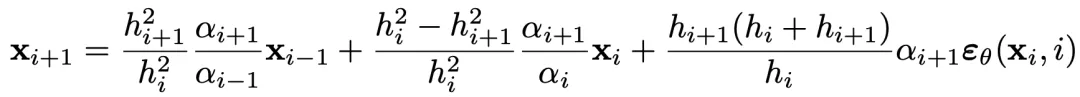
此外,研究团队还证明了 O-BELM 满足稳定性和全局收敛性:
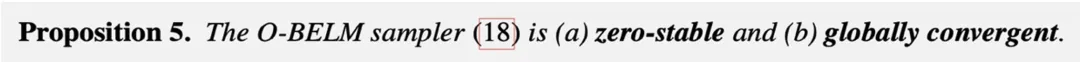
至此,可以对比几种不同反演采样器的性质:

可见,O-BELM 是第一种在严格的理论保证下兼顾精确反演性质和采样质量的采样器。
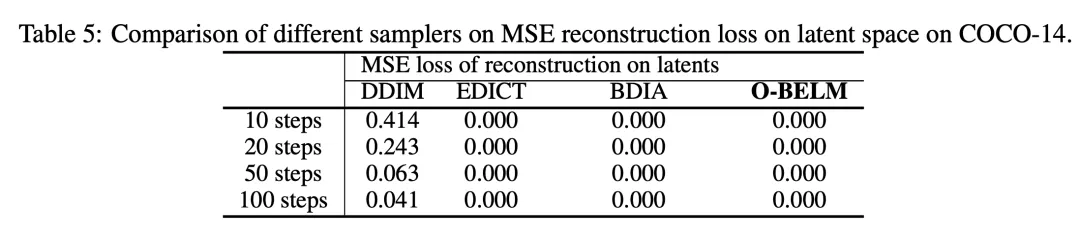
latent 空间上的 O-BELM 的重建误差为 0,这表明 O-BELM 具有精确反演的性质:

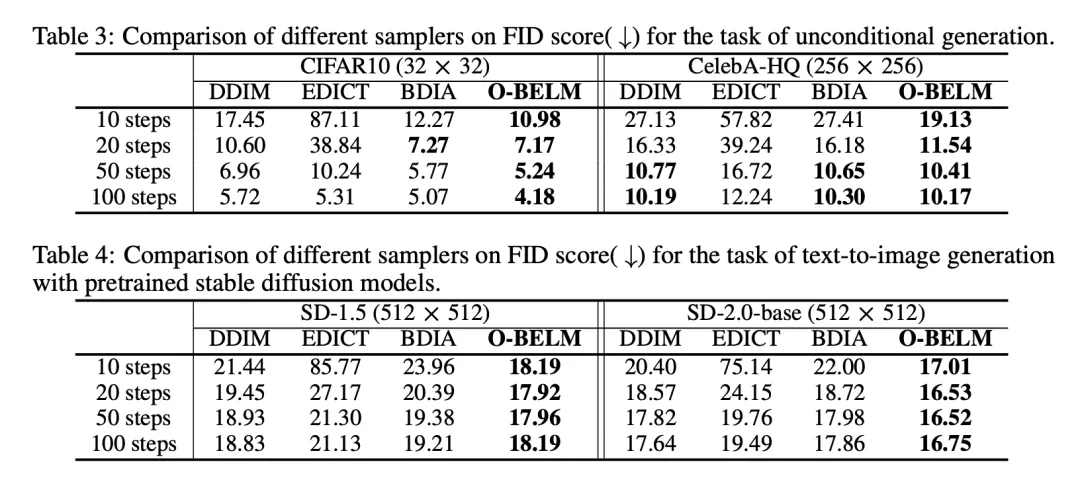
不论在无条件生成还是条件生成中,O-BELM 都表现出了高于 DDIM,EDICT 和 BDIA 的采样质量:
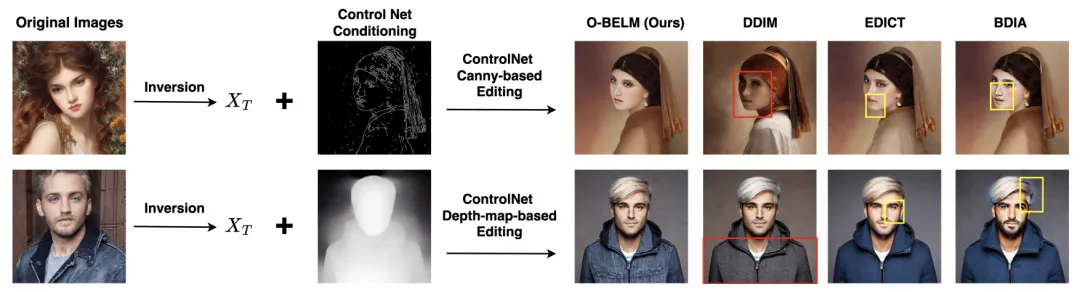
图像编辑实验体现了:
1. 由于 DDIM 不具有精确反演性质,编辑的结果中存在不一致问题(红色框);
2. 由于 EDICT 和 BDIA 具有较大的采样误差,编辑的结果出现了不真实区域(黄色框);
3.O-BELM 在保持图像一致的条件下完成了高质量的编辑。


由于 O-BELM 是一个采样方法,因此可以无缝地与 controlNet 结合,编辑效果也优于其他方法:
由于 O-BELM 精确地建立了噪声和生成样本的对应关系,这个关系是 probability flow ODE 的近似,因此 O-BELM 也使得图像插值更符合人的直觉:

本研究提出的双向显式线性多步法采样器从理论上分析并彻底解决了现有扩散生成模型中的反演问题,进一步拓宽了扩散模型在计算机视觉领域的能力边界。在图像和视频的编辑任务上有巨大的应用前景。
文章来自于微信公众号 “机器之心”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
