# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Allegro: Open the Black Box of Commercial-Level Video Generation Model
Allegro 是一款先进的商业级视频生成模型,由Rhymes AI团队开发。它通过将描述性文本转换为动态视觉内容,为用户提供了一种灵活且可控的视频创作方法。


Allegro 在视频质量和时间一致性方面表现出色,这得益于其系统化的数据策划流程、优化的模型架构、以及高效的训练策略。该模型不仅能够处理大规模图像和视频数据集,还能确保训练数据的多样性和高质量,从而生成与输入文本高度相关的视频内容。

Allegro 的特点在于其高效的视频数据压缩和编码能力,以及在扩散模型框架内对变分自编码器(VAE)和扩散变换器(DiT)架构的创新性改进。这些技术的应用使得Allegro在视频生成任务中能够实现卓越的性能,即使在复杂的场景和动态动作中也能保持高质量的输出。此外,Allegro还通过多阶段训练策略进一步提升了模型的生成能力,使其在商业应用中具有广泛的适用性。
Allegro 的核心思路是利用深度学习和扩散模型,将文本描述直接转化为高质量的视频内容。这一过程涉及对大规模图像和视频数据集的系统化策划与处理,以及对模型架构的精心设计和优化,从而实现从文本到视频的高效、准确生成。
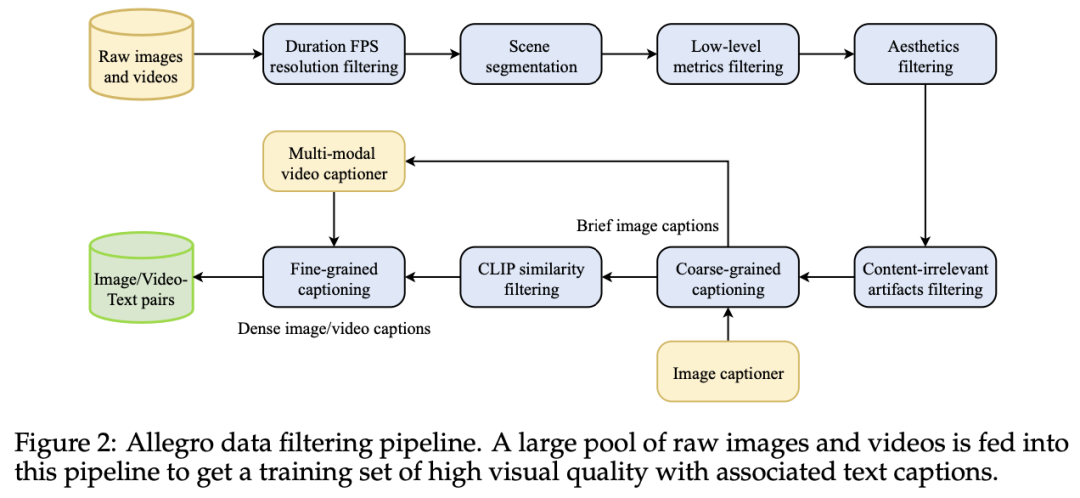
Allegro 的处理过程如下:
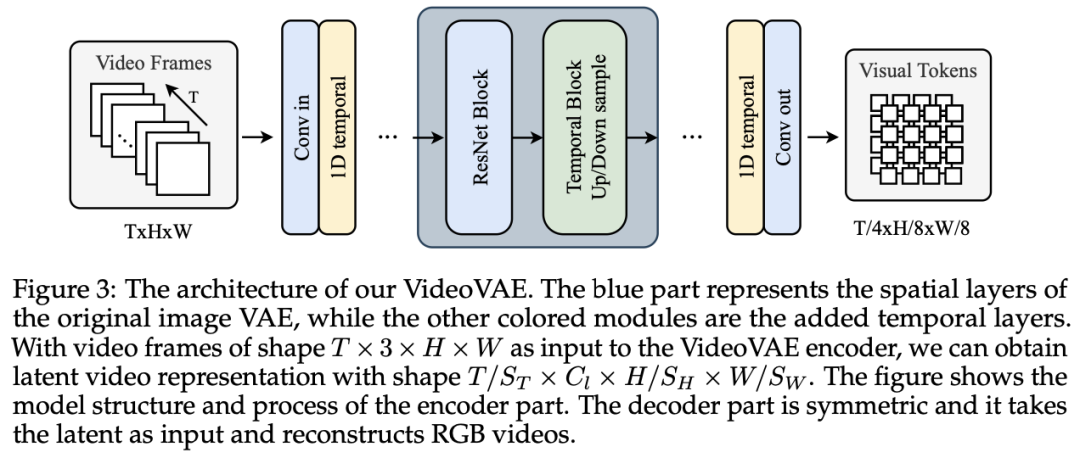
在此基础上,视频扩散变换器(VideoDiT)通过结合文本编码器和视频标记,预测并生成与文本描述相匹配的视频内容。
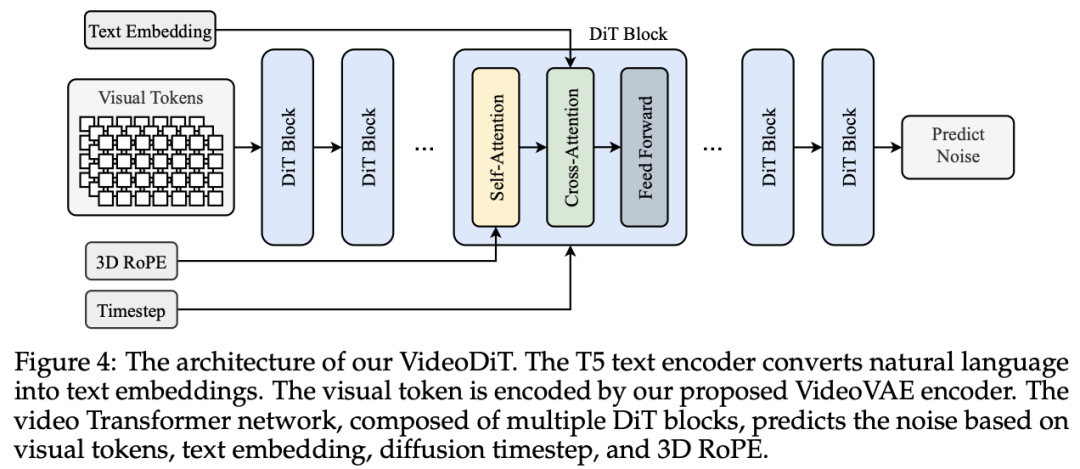
Allegro的技术特点包括对VAE和DiT架构的创新性改进,多阶段训练策略的应用,以及对计算基础设施的优化,这些都使得Allegro在视频生成的质量、一致性和多样性方面达到了商业级标准。
总的来说,Allegro 以其高效的数据处理流程、先进的模型架构和出色的视频生成能力,为自动化视频内容创作提供了一种强大的解决方案。它不仅能够满足数字媒体时代对视频内容爆炸性增长的需求,还为内容创作者提供了一种创新的工具,以更高效、更具创意的方式表达和分享故事。随着技术的不断进步和应用场景的扩展,Allegro及其所代表的文本到视频生成技术,有望在未来的娱乐、教育、营销等领域发挥更大的作用,开启视频内容创作的新篇章。
这篇论文详细介绍了Allegro视频生成模型的研究和开发,以下是内容要点概括:
介绍:
https://rhymes.ai/blog-details/allegro-advanced-video-generation-model
代码:
https://github.com/rhymes-ai/Allegro
论文:
https://arxiv.org/abs/2410.15458v1
文章来自于微信公众号 “ADFeed”




