# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

MPDS: A Movie Posters Dataset for Image Generation with Diffusion Model
MPDS(Movie Posters Dataset)是一个创新的电影海报数据集,旨在解决现有图像生成模型在制作电影海报时面临的挑战。

MPDS数据集包含超过373k的图像-文本对和8k以上的演员图像,这些数据专门针对文本到图像的生成模型进行了优化。研究团队通过结合大规模视觉语言模型自动生成的视觉感知提示和人工校正,为每张海报创建了详细的描述,包括电影标题、类型、演员阵容和概要。此外,数据集还引入了海报标题提示,以在海报中植入文本元素,如演员名字和电影标题。
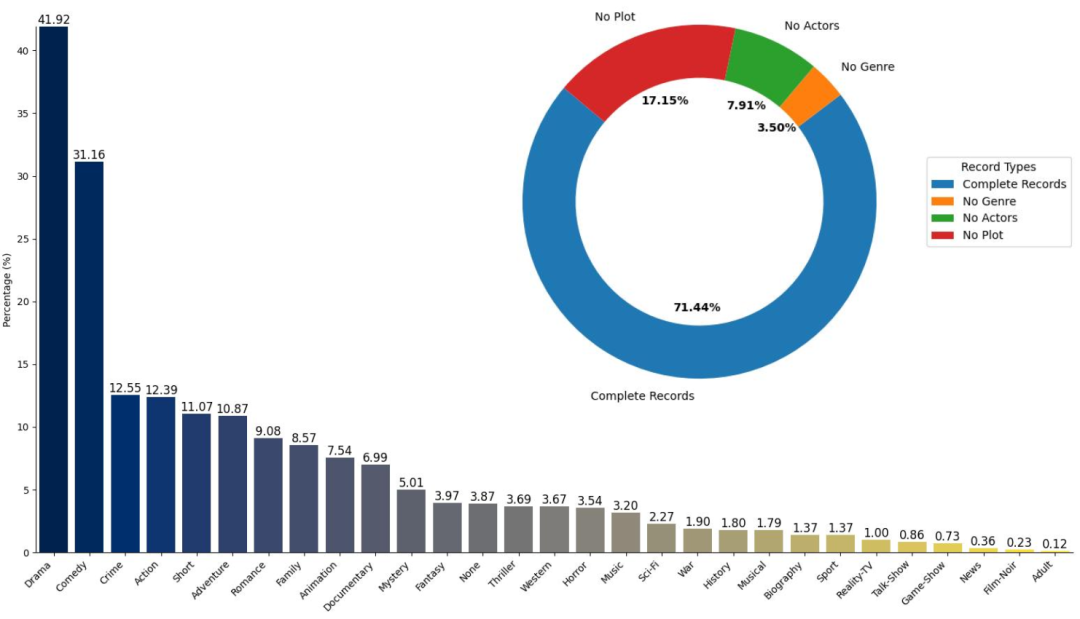
该数据集的特点是其半自动的注释策略,利用视觉语言模型Blip2进行初步注释,然后通过人工精细校正,确保了图像-文本对的准确性和适用性。

此外,研究还开发了一个多条件扩散框架,该框架结合了海报提示、海报标题和演员图像等多种条件,以生成个性化的电影海报。实验结果表明,该数据集在提高海报生成质量和可控性方面具有显著优势。
该研究的思路是构建一个专门用于生成电影海报的数据集(MPDS),并开发一个多条件扩散框架来利用该数据集。通过结合视觉语言模型和人工注释,MPDS提供了丰富的图像-文本对,以支持训练能够理解和生成具有特定风格和元素的电影海报的模型。这一方法不仅提高了海报生成的效率,还增强了设计的质量,为电影海报的智能生成提供了新的解决方案。
MPDS 数据集的创建过程包括从IMDB网站收集电影海报和相关信息,然后使用视觉语言模型Blip2自动生成图像的文本描述,再通过人工校正来提高准确性。数据集包含了详细的电影元数据,如类型、演员和剧情概要,以及专门为海报设计的文本提示。
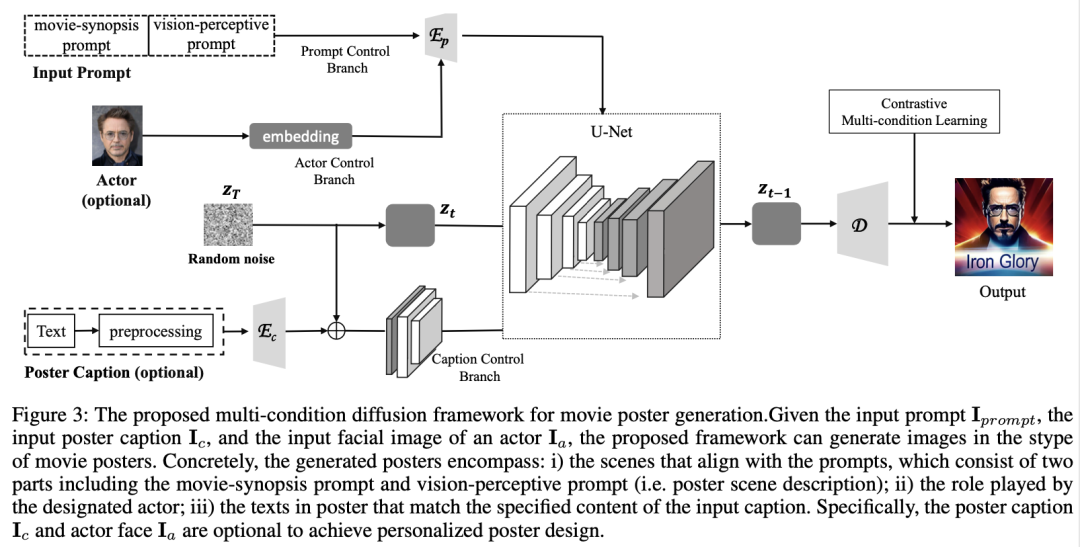
在技术特点上,研究者提出了一个多条件扩散框架,该框架能够接受文本提示、海报标题和演员图像作为输入条件,并通过U-Net网络结构进行图像的生成和重建。这一框架还整合了局部注意力机制,以增强前景和背景之间的自然融合。此外,通过对比多条件学习,进一步提升了海报中角色和标题的生成质量。
总的来说,MPDS数据集及其多条件扩散框架的价值在于它为电影海报的智能生成提供了一个高质量的数据基础和先进的技术手段。随着数据集的不断扩展和模型的进一步优化,这项技术有望在电影宣传材料设计乃至更广泛的视觉设计领域发挥更大的作用。
这篇论文介绍了一个名为MPDS(Movie Posters DataSet)的电影海报数据集,旨在改进和加速电影海报的智能生成。
以下是内容要点概括:
介绍:
https://anonymous.4open.science/r/MPDS-373k-BD3B/
论文:
https://arxiv.org/abs/2410.16840v1
文章来自于微信公众号 “ADFeed”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
