# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着开源技术占据各大新兴领域的技术路线,其不断丰富人工智能领域的应用场景。
2023年,Meta 相继发布 Llama 和 Llama2,很快成为广受欢迎的开源大模型,也成为许多模型的基座模型。
开源大模型可以促进技术的共享和交流,加速人工智能的发展,但也存在数据隐私安全风险、许可协议尚未形成共识、产业生态不健全、商业模式不清晰等问题。
在人工智能大模型领域,开源能够激发技术创新活力,推动数字时代科技创新。开源汇聚众智、促进多方协同,有效实现了优势互补,激发技术创新活力。
开源开放的创新模式相比于工业时代封闭专利的创新模式,更顺应数字时代技术迭代快、应用范围广的发展规律,解决单一主体创新成本过高问题,通过去中心化的异步协作激发各类主体的创新创造活力,以开放协作实现智慧累积,对创新效率和创新质量带来巨大提升。
Meta 在 Llama 基础上开源 Llama2并允许免费用于商业用途。Llama2 为初创企业和科研机构等主体提供了一个强大的免费选择,可以作为 OpenAI 和谷歌出售的专有模型的补充,有效激发了人工智能大模型共创浪潮。
仅Llama2 开源几日后,在其基础上衍生的大模型 FreeWilly2 便实现对 Llama2 的性能超越。与此同时,Llama2 凭借其开放可拓展的优势,衍生出 lawyer-llama、EduChat 等垂直领域的模型产品,加速推动人工智能大模型场景化应用创新。
大语言模型的开源推动了深度学习和人工智能的持续发展,也催生了一系列前沿探索和 落 地 应 用。2017 年,Google 发 表 论 文“Attention is All You Need”, 首 次 提 出 了Transformer 架构,该架构成为后续人工智能大模型构建的基础。
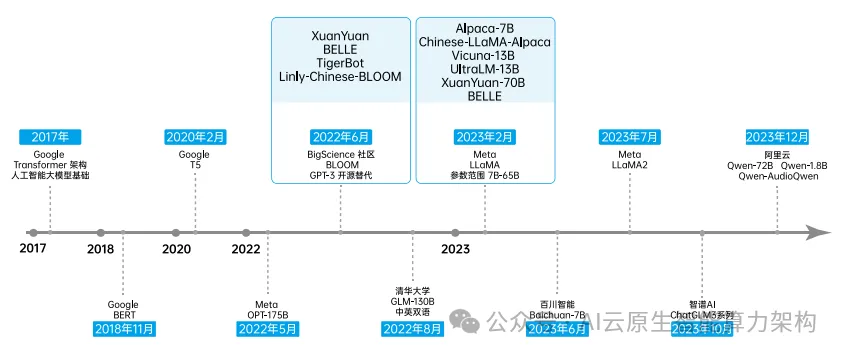
随着开源人工智能大模型不断发展,由 BLOOM、LLaMA 等主流开源大模型逐渐衍生出其他开源人工智能大模型。
人工智能大模型的部署应用需要经历数据准备、模型设计、模型训练、模型优化等多个环节,落地后仍需要根据实际需求以及应用反馈进行调整与维护。
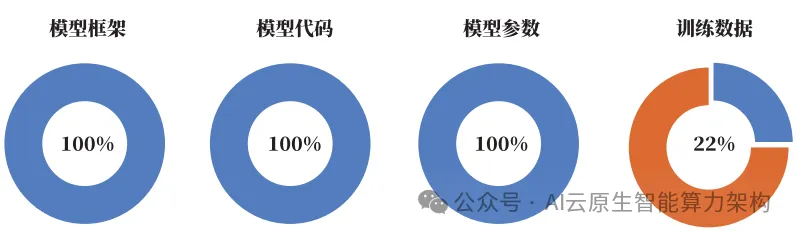
其中,模型框架、模型代码、模型参数、训练数据四个方面是衡量其开源成熟度的重要评定等级。

类 open-core 商业软件模式
open-core 商业软件模式是指核心代码开源,但是部分功能代码是闭源,最终形成了闭源的代码软件进行售卖。在开源人工智能大模型企业中,企业开源较低参数规模的大模型,并提供较大参数规模的付费版本。企业根据自身场景和业务需求,为客户定制专属大模型,并针对部署的定制化版本提供更全面的支持、咨询、培训和托管服务。
专业服务模式
专业服务模式由传统商业软件的以“产品”为卖点转向以“服务”为卖点,是开源商业公司采用的一种全新的商业模式。由于开源人工智能大模型一种技术密集型产品,需要对大模型进行持续维护、优化、迭代升级才能发挥软件的最大价值。专业服务模式下的开源商业公司针对免费的开源项目提供收费服务,如技术文档、二次开发支持、用户培训等技术服务实现盈利。
在数据治理中,开源人工智能大模型关注数据隐私与数据安全质量。开源人工智能大模型训练数据的非法泄露可能会导致敏感信息的暴露,因此确保数据隐私的安全成为治理的重要环节之一。在开发和使用过程中,需确保数据采集、存储和处理符合相关法规。数据的安全质量对于开源人工智能大模型同样重要。为确保数据安全质量,需关注数据的准确性、完整性、代表性等,并关注数据偏差和数据集的平衡性,避免模型在特定群体或场景下产生不公平偏见。高质量的数据能为模型提供更好的基础,从而使其在实际应用中发挥更大的价值。
在模型治理中,应注重开源协议使用与模型伦理道德问题。开源协议通过明确规定开源项目的使用、修改和分发方式,为企业和用户提供了一定程度的保障。开源许可证保障了开源大模型的自由使用和共享,促进了创新和协作,同时也为开源大模型的作者和用户提供了一定的法律保护。目前,部分开源人工智能大模型使用常用的许可协议如 Apache 许可证等,同时部分模型采用自己定义的许可证。开源人工智能大模型的开发和应用还需关注伦理道德问题。这包括确保模型的公平性、透明度和可解释性,避免歧视性结果,评估和管理模型可能带来的社会影响。此外,还需关注模型在特定领域的合规性和符合道德标准的使用,以确保技术的正面推动作用。
在入选本次案例集的大模型中,模型框架开源的企业占比为 100%,模型代码开源的企业占比为 100%,模型参数开源的企业占比达到 100%。在本次调研的所有开源大模型中,用户均可以实现本地部署并针对实际使用情况进行微调。另有 22% 的大模型对其训练数据进行开源,方便用户对模型进行微调和二次开发。同时,部分大模型对外公布其训练细节,方便用户研究大模型训练过程以及进行模型继续训练。
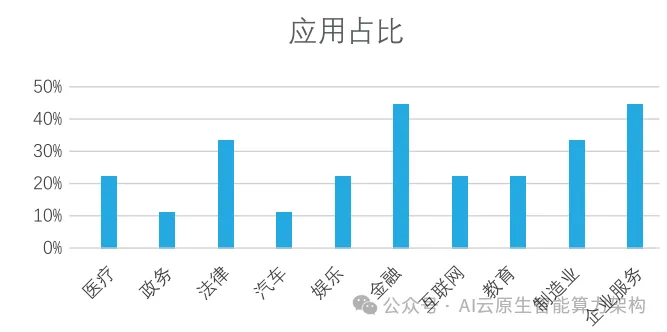
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
在本次调研的开源人工智能大模型中,部分模型在开源模型测评榜单中位居前列,部分开源模型能力已领先 LLaMA2,在全球形成中国大模型开源生态圈。同时开源大模型语言能力出众,在逻辑推理、幻觉感知等方面有高的精度,配套生态丰富,可以支持行业模型应用。开源人工智能大模型有效降低用户使用门槛,方便用户训练、微调并使人工智能大模型。
通过调研,目前国内开源人工智能大模型数量较闭源人工智能大模型仍有差距,模型在多语言能力,支持的序列长度,推理速度,显存占用等方面仍有进步空间。同时开源人工智能大模型应用创新落地能力仍有提升空间。目前国内外基于大模型的应用多停留在基础阶段,应不断提升开源大模型能力,为用户带来便捷、可靠、高效、个性化的产品。
在本次调研的开源人工智能大模型中,通过强化数据安全与保障模型安全以提升模型合规能力。通过数据安全与模型安全,已初步构建开源人工智能大模型安全保障防线。
文章来自于微信公众号“AI云原生智能算力架构”,作者“AIsoar”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
