# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

癌症具有高度异质性,不同病人使用同样药物治疗的效果可能有很大差别。据估计,美国食品药品监督管理局(FDA)已批准药物的响应率约在20%-80%之间,此外还有毒副作用和获得性耐药的问题。个体化用药和联合用药能达到提高疗效、减少毒副作用、降低耐药性的效果,是癌症精准用药研究的重要任务,亟需基于大数据的计算模型提供支撑。
中国科学院上海营养与健康研究所李虹研究组多年来在抗癌药物疗效建模方向持续深耕,发表了基于分子组学预测药物响应和肝癌药物基因组相关的系列论文。但前期研究表明肿瘤用药的计算分析仍存在诸多挑战,例如:肿瘤临床前模型和病人存在差异,计算模型缺乏泛化能力;药物组合的作用机制复杂搜索空间大,对药物联用协同效果的准确和稳健估计仍很困难。
为了解决这些问题,李虹研究组近期发布了两个新的人工智能(AI)模型。
2024年10月18日,李虹研究组在 Bioinformatics 期刊发表了题为:Dual-view jointly learning improves personalized drug synergy prediction 的研究论文。

该研究构建了一个双视图深度学习模型JointSyn来预测药物组合的协同效应。JointSyn在各种基准的预测准确性和稳健性方面均优于现有的最先进方法。
进一步的分析表明,双视图模型相比单视图更擅长区分协同与拮抗药物组合。每个视图能够捕获不同的协同作用特征,并在最终预测中发挥互补作用。此外,微调后的JointSyn在少量实验数据条件下提高了预测新药物组合和癌症样本的泛化能力,展示了其强大的泛化性能。
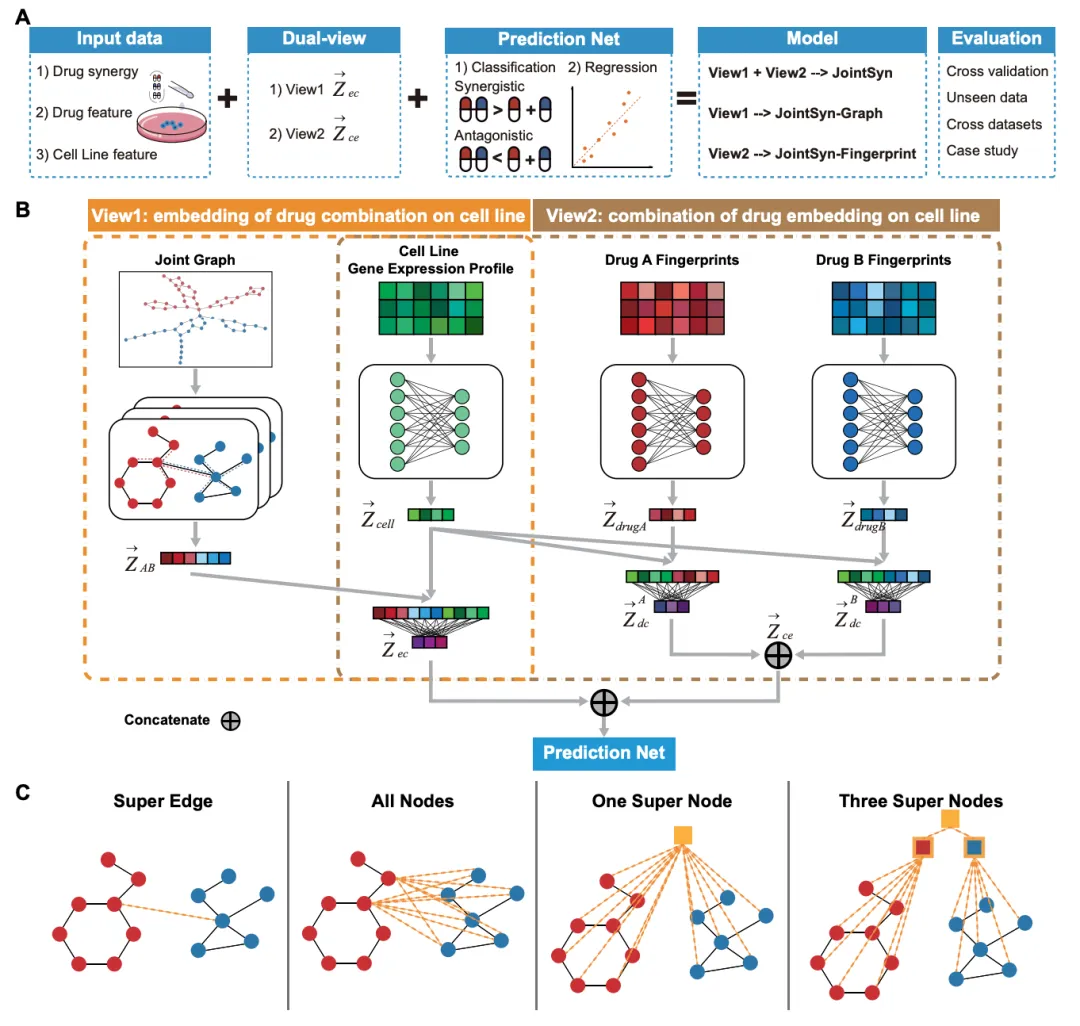
双视图联合学习JointSyn提高药物组合协同性能
研究团队还使用JointSyn生成了泛癌药物协同作用的估计图谱,并探索了不同样本之间的差异模式。这些结果证明了JointSyn预测药物协同作用的能力,可以为更好的实验设计提供定量建议,也为个性化组合疗法的开发提供有力支持。
2024年10月24日,李虹研究组在 Journal of Pharmaceutical Analysis 期刊发表了题为:A disentangled generative model for improved drug response prediction in patients via sample synthesis 的研究论文。

该研究提出了一种用于药物响应预测的新型解耦合成网络DiSyn,有效地将肿瘤细胞系模型上提取的知识泛化到患者数据,在药物响应预测方面达到最先进的性能。
DiSyn旨在从标记良好的源域数据(肿瘤细胞系)上构建药物响应预测模型,并将其应用于缺乏标签的目标域(癌症患者)。其核心策略是从输入数据中分离出与药物响应相关的特征,并通过合成样本来提高模型在目标域的预测准确性。
通过在解耦和合成之间进行迭代,确保模型在目标域中不断提高其性能。在TCGA、I-SPY2和NIBR PDXE三个目标数据集上的验证结果表明:基于癌症细胞系构建的DiSyn模型用于患者和小鼠时取得了优于其它方法的准确性。此外,DiSyn在乳腺癌患者中的应用案例也展示了其在生物标志物发现和药物组合探索中的潜在价值。
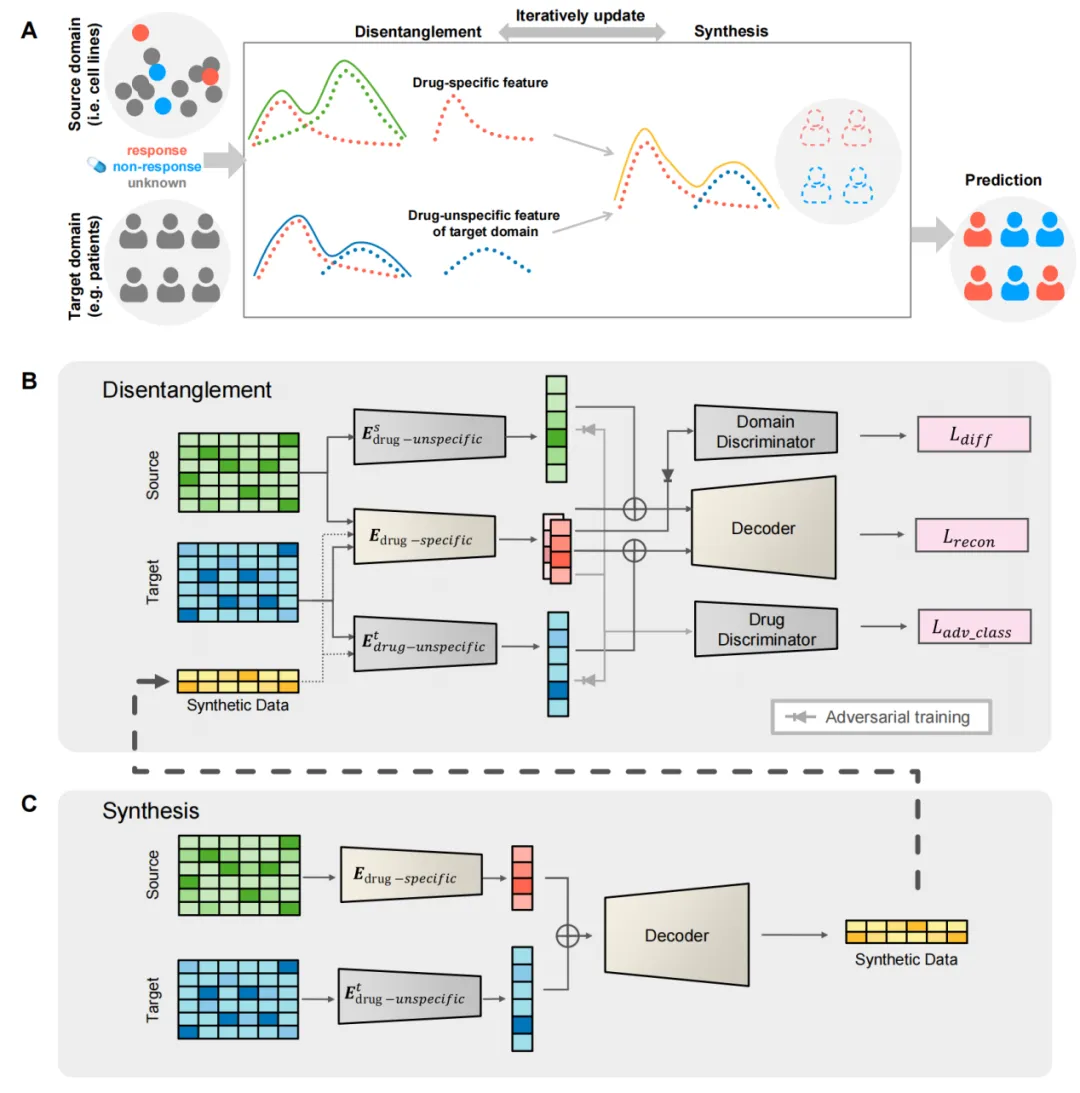
基于解耦与合成的DiSyn模型改进抗癌药物疗效预测
中国科学院营养与健康研究所博士生李学良为第一篇论文的第一作者,博士生李坤实和博士生沈碧寒为第二篇论文的共同第一作者,李虹研究员为两篇论文的通讯作者。
论文链接:
https://doi.org/10.1093/bioinformatics/btae604
https://doi.org/10.1016/j.jpha.2024.101128
文章来自于微信公众号“生物世界”,作者“BW”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
