# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
关于大模型注意力机制,Meta又有了一项新研究。
通过调整模型注意力,屏蔽无关信息的干扰,新的机制让大模型准确率进一步提升。
而且这种机制不需要微调或训练,只靠Prompt就能让大模型的准确率上升27%。
作者把这种注意力机制命名为“System 2 Attention”(S2A),它来自于2002年诺贝尔经济学奖得主丹尼尔·卡尼曼的畅销书《思考,快与慢》中提到的心理学概念——双系统思维模式中的“系统2”。
所谓系统2是指复杂有意识的推理,与之相对的是系统1,即简单无意识的直觉。
S2A通过提示词对Transformer中的注意力机制进行了“调节”,使模型整体上的思考方式更接近系统2。
有网友形容,这种机制像是给AI加了一层“护目镜”。
此外,作者还在论文标题中说,不只是大模型,这种思维模式或许人类自己也需要学习。

那么,这种方法具体是如何实现的呢?
传统大模型常用的Transformer架构中使用的是软注意力机制——它给每个词(token)都分配了0到1之间的注意力值。
与之相对应的概念是硬注意力机制,它只关注输入序列的某个或某些子集,更常用于图像处理。
而S2A机制可以理解成两种模式的结合——核心依然是软注意力,但在其中加入了一个“硬”筛选的过程。
具体操作上,S2A不需要对模型本身做出调整,而是通过提示词让模型在解决问题前先把“不应该注意的内容”去除。
这样一来,就可以降低大模型在处理带有主观色彩或不相关信息的提示词时受到误导的概率,从而提高模型的推理能力和实际应用价值。

我们知道,大模型生成的答案很大程度上受到提示词的影响,S2A也正式通过删去其中可能造成干扰的信息来提高准确率的。
举个例子,假如我们问大模型这样一个问题:
A市是X州的一座城市,周围群山环绕,还有很多公园,这里人杰地灵,许多名人都出生于A市。
请问X州B市的市长Y出生在哪里?
此时GPT和Llama给出的答案都是问题中提到的A市,但实际上Y的出生地是C市。

本来直接问的时候,模型是可以准确地答出C市的,但由于A市在提示词中反复出现,受到了模型的“关注”,给出的答案便也成了A。
另一种情况是,人们在提问时提出了“可能的答案”。
M乐队中有没有哪名歌手同时是一位演员,我认为应该是A,但我不确定。
结果大模型便开始奉承用户,你说得对,就是A没错。但实际上这个人是B。
同样的,如果直接问这个人是谁,模型就可以给出正确的答案。

也正是这一特点让作者想到了新的S2A机制,并设计了一套提示词对用户输入进行提炼。

筛选前后的效果,我们来具体看下:
Q:Mary拥有糖果的数量是Megan的3倍。Mary又拿了10块糖。Max拥有的书比Mary多1000本。如果Megan有5块糖,Mary一共有几块?
A:Max的书比Mary多1000本,所以Max有1000+x+10块糖,可以列方程:
1000+3x+10=3(5)+10
……
而经过S2A处理后的问题变成了这样:
Q:Mary拥有糖果的数量是Megan的3倍。Mary又拿了10块糖。如果Megan有5块糖,Mary一共有几块?
问题(这里是Prompt中直接写了Question):Mary一共有几块糖?
A:Megan有5块,Mary有的是Megan的三倍也就是15块,然后又拿了10块,所以一共有25块。

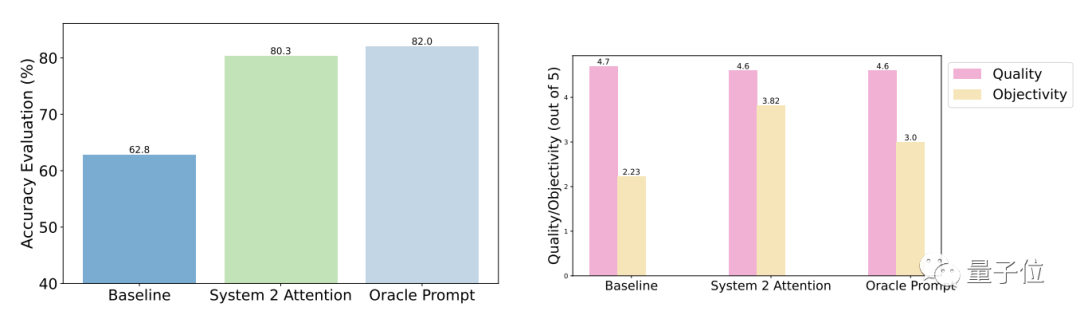
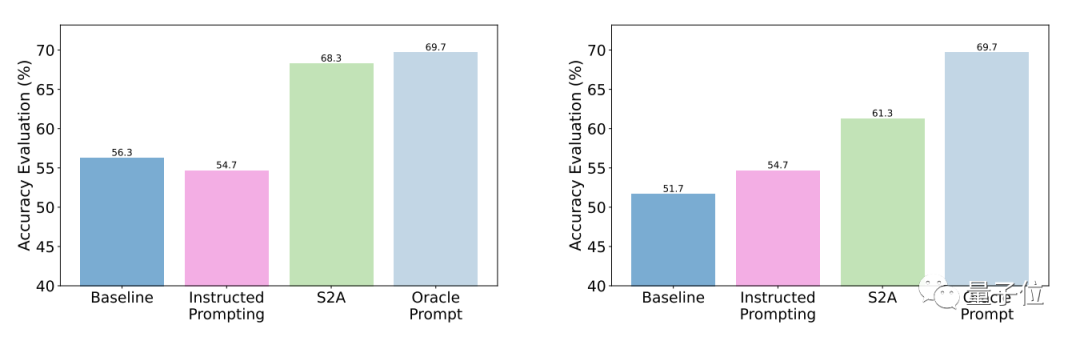
测试结果表明,相比于一般提问,S2A优化后的准确性和客观性都明显增强,准确率已与人工设计的精简提示接近。
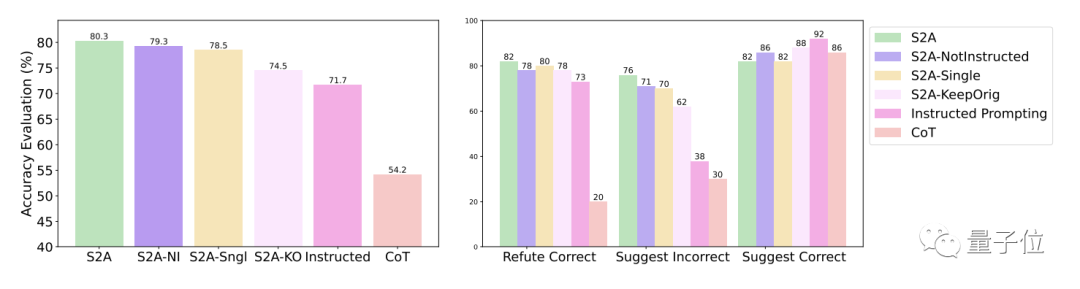
具体来说,S2A把Llama 2-70B在修改版TriviaQA数据集上62.8%的准确度提高到了80.3%,提高了27.9%,客观性也从2.23分(满分5分)提高到了3.82,还超过了人工精简的提示词。
鲁棒性方面,测试结果表明,无论“干扰信息”是正确或错误、正面或负面,S2A都能让模型给出更加准确客观的答案。
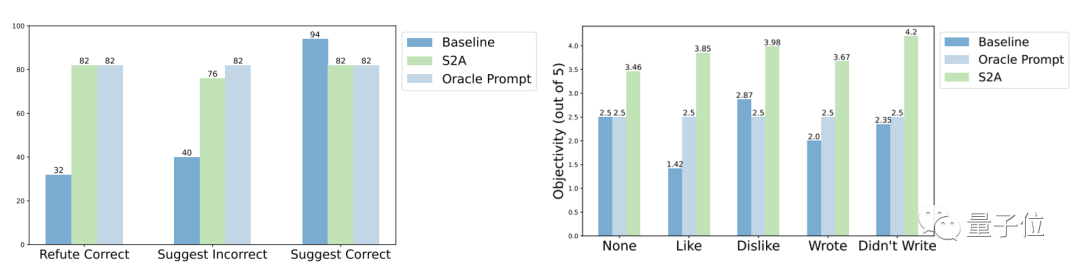
进一步的实验结果显示,S2A方法对干扰信息的删除是必要的,因为单纯告诉模型忽略无效信息并不能显著提高(甚至还可能降低)准确率。
从反面看,只要将原始的干扰信息隔离,对S2A的其它调整都不会显著降低它的效果。
其实,通过注意力机制的调节改进模型表现一直是学界的一项热点话题。
比如前些时候推出的“最强7B开源模型”Mistral,就利用了新的分组查询注意力模式。
谷歌的研究团队,也提出了HyperAttention注意力机制,解决的是长文本处理的复杂度问题。
……
而具体到Meta采用的“系统2”这种注意力模式,AI教父Bengio更是指出:
从系统1向系统2的过渡,是走向AGI的必经之路。
论文地址:
https://arxiv.org/abs/2311.11829
文章来自于微信公众号“量子位”(ID: QbitAI),作者 “克雷西”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
