# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
解决真实GitHub Issue的基准测试,字节家的豆包MarsCode Agent悄悄登顶了。
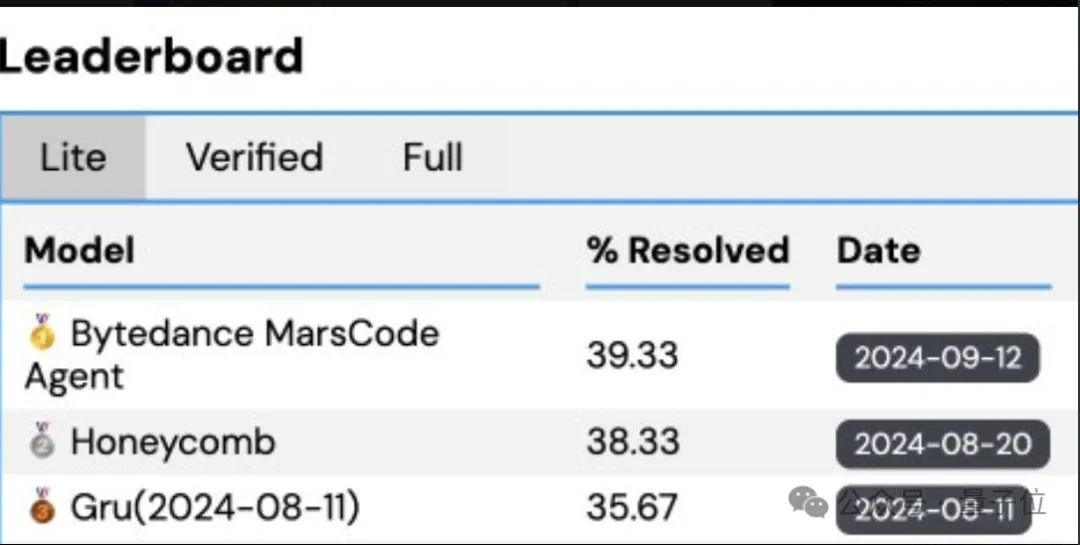
SWE-Bench,一个由普林斯顿大学提出的极具挑战性的Benchmark,近期受到工业界、学术界和创业团队的广泛关注。
在其子集SWE-Bench Lite排行榜上,豆包MarsCode Agent近期冲上第一。
虽然这是面向所有大模型解决方案的评测,但现在排名靠前的部分已基本被AI Agent占领。
AI Agent即能够感知外部环境、操作工具并具有一定自主决策能力的智能体,受到了越来越多的研究关注。
现在,豆包MarsCode Agent团队分享了在软件工程领域进行了一系列关于AI Agent应用的探索和尝试:
通过构建Agent框架并为其提供代码检索、调试和编辑的交互接口和工具,使得Agent有可能接管部分软件工程开发任务。
开发者在日常的开发工作中常常会遇到各种问题,例如:
上述多样化的程序修复和开发任务通常无法用一种固定的模式来进行处理。
例如,一些简单的缺陷修复或功能扩展仅需对代码进行review即可完成;而较深的异常堆栈或复杂的逻辑错误仅凭阅读代码往往很难发现问题所在,需要通过动态执行代码并追踪相关变量才能暴露出相关缺陷,从而对其进行修复。
因此,团队采用了多Agent协作的框架来适应不同的开发场景。如下图所示,多Agent协作框架中包含以下7类角色:

团队为不同的Agent配备了相应的工具集以支撑其完成指定任务,各Agent配备的工具集如下表所示。
值得注意的是,团队并没有令每个Agent都拥有所有工具的使用权,而是尝试限制各个Agent的能力和职责范围,从而降低单个Agent解决当前环节问题的难度,以提高任务执行的稳定性和输出结果的质量。

在动态调试修复场景下,各Agent的协作求解流程如下:
在动态过程中,团队通过在Docker容器中搭建一个运行环境沙箱,以实现动态调试的问题复现和运行验证。
在静态修复场景下,由于无法直接对问题进行复现和动态验证,需要制定针对该问题的静态修复方案。过程如下:
团队为豆包MarsCode Agent提供了多种可跨语言适配的代码检索工具,以适应各种软件工程开发场景下的代码检索需求。
代码知识图谱是将代码元素、属性以及元素之间的关系表示为图结构,从而帮助Agent更好地理解和管理大规模的代码库。
在这种图结构中,顶点代表代码的实体(如函数、变量、类等),边则代表实体之间的关系(如函数调用、变量引用、类的继承关系等)。通过这种方式,代码知识图谱可以为代码库提供更丰富且结构化的信息。
团队通过程序分析的技术,将仓库中的代码,文档信息进行分析组织,生成一个以变量,函数,类,文件等代码语义节点为实体,文件结构关系、函数调用关系,符号索引关系为边的多向图。构成一张融合了代码,文档,仓库信息等多数据源的代码知识图谱。
在给定的代码库中,每个节点和边都通过唯一标识符进行标记,确保每个代码实体在整个代码库中都是唯一的。
在这种设计中,代码知识图谱将使用图属性来存储代码实体及其依赖关系。每个节点记录其在代码库中的位置、类型和名称。每条边标识两个节点之间的关系类型,以及关系在代码中的位置。
比如对下面这样一段代码:
// file: main/fileA.go
package main
import (
"ckg-prompt/main/cmd/pkg_b"
"fmt"
)
// StructA struct
type StructA struct{}
// FunctionA method for StructA
func (a *StructA) FunctionA() pkg_b.StructB {
x := pkg_b.NewStructB() // Instantiate StructB
return x
}
// XFunction function
func XFunction() {
x := pkg_b.NewStructB() // Instantiate StructB
x.FunctionB() // Calls FunctionB
}
它的代码知识图谱如下图所示:
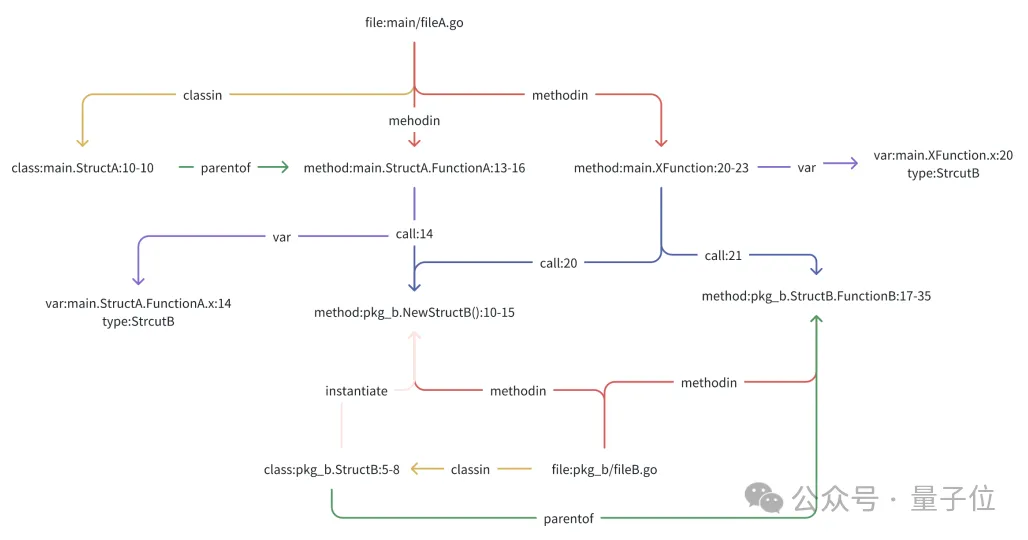
图1代码知识图谱元素构成
在构建完成代码知识图谱后,Agent的代码检索请求将通过下图中的管道进行处理并实现召回。
最后将候选实体列表1 & 2 & 3进行合并,通过精排模型,得到最终实体列表X,返回给Agent,完成代码检索。

图2代码知识图谱召回流程
在豆包MarsCode Agent中,代码知识图谱工具能够实现广泛、全面的代码检索,为Agent提供了repo内知识问答的能力。目前,代码知识图谱支持包含C、C#、CPP、Java、Kotlin、Javascript、Typescript、TSX、Rust、Golang、Python、Lua在内的12种常用编程语言。
代码知识图谱能够应对大部分目标工程下的类、函数定义与引用的检索需求,但仍存在以下盲区:
为解决上述问题,豆包MarsCode Agent利用通用的语言服务协议(Language Server Protocol)实现用户机器上全局、精确的代码召回。
语言服务器协议是一种由Microsoft开发的协议,广泛适配包含编程语言、标记语言、多种工具和框架在内的语法体系,在IDE场景下具有很好的通用性。豆包MarsCode Agent调用语言服务器协议实现代码召回的过程如下图所示:

图3语言服务的召回流程
Agent调用语言服务器进行代码召回的过程与开发者在IDE中使用“Ctrl+左键”点击某个标识符进行代码跳转的过程是一致的,但由于Agent的数字定位和计算能力较弱,团队增加了模糊定位功能以进一步强化Agent使用LSP工具的能力:
这三个服务的优先级自上而下由高到低,使用第一个成功得到响应的LSP请求结果作为工具的输出。
在团队对研发域AI Agent的长期探索过程中,尝试了各种使用LLM进行代码编辑描述的方式,发现目前LLM的代码修改能力普遍较弱。如下是团队曾经探索(失败)过的代码编辑方案:
Unified diff格式的变更是将原始文件和修改后文件以一种统一的方式展示出来,比如:
Unified diff的代码编辑描述有着非常严格的格式要求,而且LLM很难正确计算变更的代码行号增量,从而导致生成的Unified diff无法成功apply。
团队在所有的代码检索的结果中都对代码添加了行号,希望Agent能正确填写修改范围并完成修改,然而即便是GPT-4,也不能完全正确地提供需要修改的代码范围,时常会出现1~2行的偏移,从而导致修改后出现重复行或误删;
-对整个文件进行重写;
为LLM提供整个文件的内容和修改描述,要求LLM输出修改后的完整文件内容。这种方式能够避免LLM进行行号的计算,但显然每次代码编辑都使用闭源模型生成整个文件是非常不经济的,且在一些长文件中几乎不可用。团队也正在尝试通过SFT获取一个专门的代码编辑模型实现全文重写的能力,但这是一个长期计划。
经过大量的探索和尝试,团队认为LLM的代码编辑描述需要具备以下特点:
基于此,团队注意到Aider的代码变更方式,受此启发并开发了团队目前认为相对稳定的代码编辑:豆包MarsCode AutoDiff。
(https://aider.chat/docs/benchmarks.html#the-benchmark)
AutoDiff的代码编辑描述与git冲突的表现方式是类似的,Agent需要在Conflict标识栅栏中提供需要编辑的文件路径、代码原文、替换代码。
AutoDiff会对该代码编辑块进行解析,尝试在给定文件中匹配与LLM提供代码原文片段相似度最高的片段,并用LLM提供的替换代码进行替换操作,随后结合修改文件的上下文对替换代码的缩进进行自动调整。
最后修改前后的文件进行差异对照从而获取Unified diff格式的变更文件。上述修改是模拟进行的,并未实际在用户设备上落盘,只是为了获取Unified diff格式的变更文件,最终代码修改需要经过后续的静态代码诊断。
```diffs
/playground/swe_ws/testbed/matplotlib__matplotlib__3.6/lib/matplotlib/figure.py
<<<<<<< SEARCH
elif constrained_layout is not None:
=======
elif constrained_layout in [None, False]:
>>>>>>> REPLACE
<<<<<<< SEARCH
else:
=======
elif constrained_layout in [None, False]:
self.set_layout_engine(layout='none')
>>>>>>> REPLACE
尽管AutoDiff能够正确完成大部分的代码编辑请求,但仍然会存在诸如类型错误、变量未定义、缩进调整错误、括号没有正确闭合等LLM常见的代码编辑语法问题,针对这些问题,团队使用语言服务器协议对AutoDiff修改前后的文件进行静态代码诊断,过程如下:

图4代码编辑过程中的静态代码诊断
团队在SWE-bench Lite数据集上对豆包MarsCode Agent的性能进行了详细评测。
SWE-bench是由普林斯顿大学提出了一个极具挑战性的针对LLM解决程序逻辑bug的benchmark。该数据集整理了真实的来自Github的12个工业级Python代码大仓中的2294个issue问题。
给定一个代码库以及对要解决issue问题描述,Agent需要从代码仓中检索并编辑代码,最终提交能解决相关问题的代码补丁。
在SWE-bench中解决问题通常需要同时理解和协调多个函数、类甚至文件之间的更改,要求模型与执行环境交互,处理极长的上下文并执行比传统代码生成更复杂的推理。作者评估表明,Claude 2和GPT-4仅能解决其中4.8%和1.7%的实例。

SWE-bench中测试实例在各repo中的分布

不同代码仓样本的求解难度也参差不齐
由于SWE-bench的难度很大,在后续的研究中,开发者们发现在SWE-bench的2294个实例上进行评测是一个时间与Token投入巨大且令人沮丧的过程,无法验证短期内的进展。
所以SWE-bench作者从原本的数据集中抽取了300个Issue描述完整、求解逻辑清晰、相对易于解决的300个实例,组成SWE-bench Lite数据集。目前,SWE-bench Lite数据集已经成为Agent解决软件工程问题水平的评测标杆,已有20多家企业与研究组织参与了SWE-bench Lite评测和提交中。
豆包MarsCode Agent在最新的SWE-bench Lite评测实验中,成功求解了其中的118个实例,求解率达到39.33%。
下表展示了评测实验结果的详细分析:

团队对目前SWE-bench Lite排行榜上排名前三的工具(CodeStory Aide,Honeycomb和AbanteAI MentaBot)进行了错误定位能力评估。对于一个patch,如果它修改的文件和gold patch所修改的文件相同,则认为错误定位正确,否则错误。分析结果如图6所示:
豆包MarsCode Agent通过代码知识图谱、语言服务等代码检索工具,在300个实例中成功定位到了245个实例的待修改文件(成功率81.7%),而CodeStory Aide为221(成功率73.7%),Honeycomb为213(成功率71%),
AbanteAIMentatBot为211(成功率70.3%)。从代码检索和错误定位能力看,豆包MarsCode Agent处于领先地位。

团队分析了实验中静态和动态求解的实例分布,如下图所示,在所有实例中,有104/300=34.67%的实例被PlannerAgent认为适合动态求解,196/300=65.3%的实例被认为适合进行静态求解,通过动态方式成功求解53个实例,求解率为51%,静态方式成功求解65个实例,求解率为33%。由于动态调试有缺陷复现和和验证的过程,表现在求解率上略高于静态修复。在被求解的118个实例中,有44.9%的实例是由动态方式修复,55.1%的实例由静态方式修复。
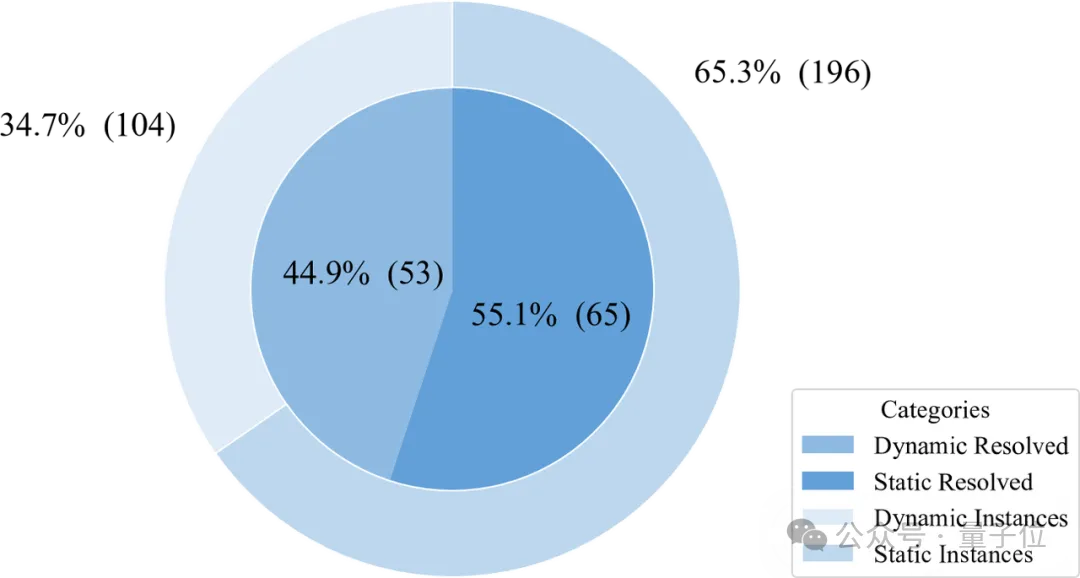
图8豆包MarsCode Agent实验中静态与动态求解分布
豆包MarsCode Agent团队致力于AI Agent方法在软件工程领域的落地和应用。在未来将持续关注以下优化方向:
-降低大语言模型调用成本,推广豆包MarsCode Agent在更多场景的落地,为更多用户提供高质量智能软件开发服务;
-加强用户与Agent的协作和交互,提升用户对Agent作业过程的掌控感;
-支持Agent对用户工作区的动态调试,同时避免用户环境污染等问题;
-进一步提升文件错误定位准确率和代码修改正确率。
欢迎大家通过论文了解更多信息:
https://arxiv.org/abs/2409.00899
文章来自微信公众号 “ 量子位 ”,作者 豆包MarsCode团队



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
