# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人类只需要演示五次,就能让机器人学会一项复杂技能。
英伟达实验室,提出了机器人训练数据缺乏问题的新解决方案——DexMimicGen。
五次演示之后,DexMimicGen就可以直接模仿出1000个新的demo。
而且可用性强,用这些新demo训练出的机器人,在仿真环境中的任务成功率可以高达97%,比用真人数据效果还要好。

参与此项目的英伟达科学家范麟熙(Jim Fan)认为,这种用机器训练机器的方式,解决了机器人领域最大的痛点(指数据收集)。
同时,Jim Fan还预言:
机器人数据的未来是生成式的,整个机器人学习流程的未来也将是生成式的。

值得一提的是,DexMimicGen三名共同一作都是李飞飞的“徒孙”,具体说是德克萨斯大学奥斯汀分校(UT奥斯汀)助理教授朱玉可(Yuke Zhu)的学生。
而且三人均为华人,目前都在英伟达研究院实习。

如前所述,DexMimicGen可以仅根据人类的5次演示,生成1000个新DEMO。
在整个实验中,作者设置了9个场景,涵盖了3种机器人形态,共进行了60次演示,获得了21000多个生成DEMO。
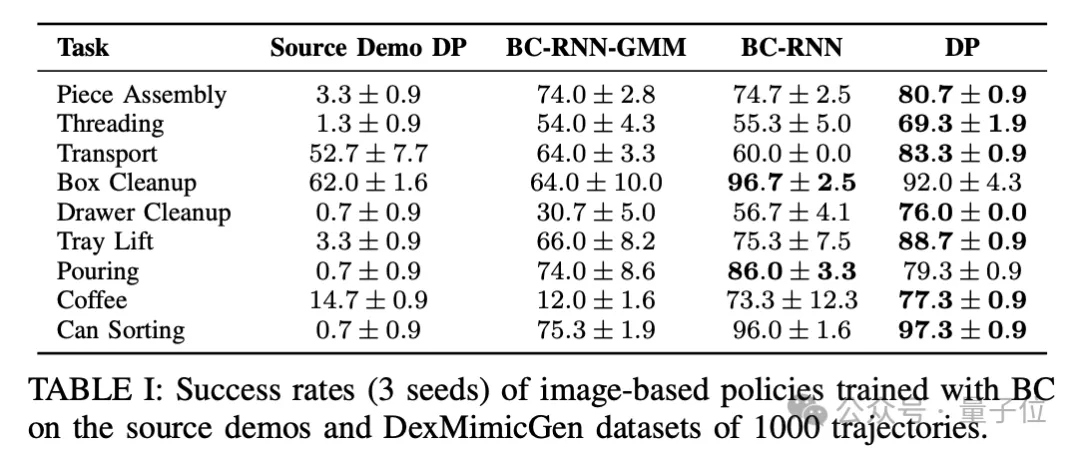
在仿真环境当中,用DexMimicGen生成数据训练出的策略执行整理抽屉这一任务,成功率可达76%,而单纯使用人工数据只有0.7%。

对于积木组装任务,成功率也从3.3%提升到了80.7%。

成功率最高的任务是罐子分类,更是高达97.3%,只用人工数据的成功率同样只有0.7%。

整体来看,在仿真环境中,生成数据让机器人在作者设计的九类任务上的成功率均明显增加。
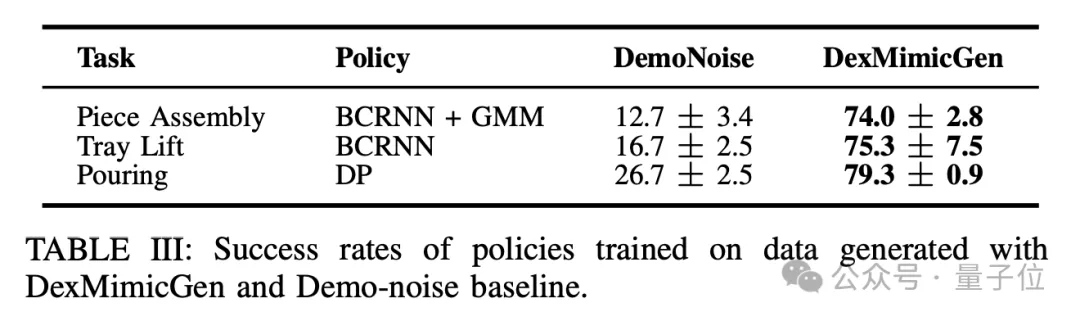
相比于baseline方法,用DexMimicGen生成的数据也更为有效。
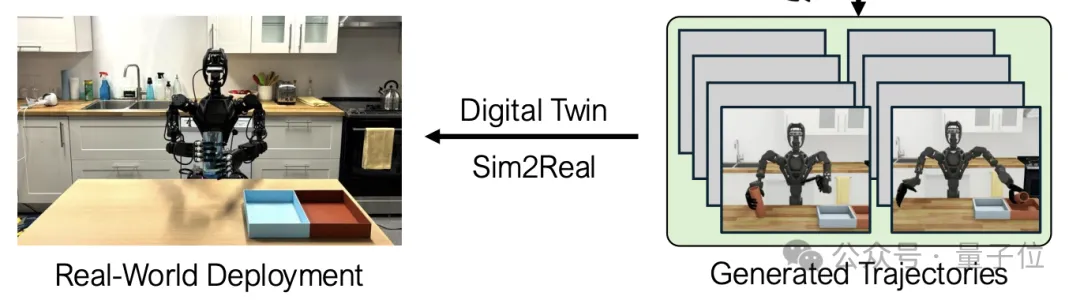
迁移到真实环境之后,作者测试了易拉罐分拣的任务,结果仅用了40个生成DEMO,成功率就达到了90%,而不使用生成数据时的成功率为零。
除此之外,DexMimicGen还展现了跨任务的泛化能力,使训练出的策略在各种不同任务上表现良好。
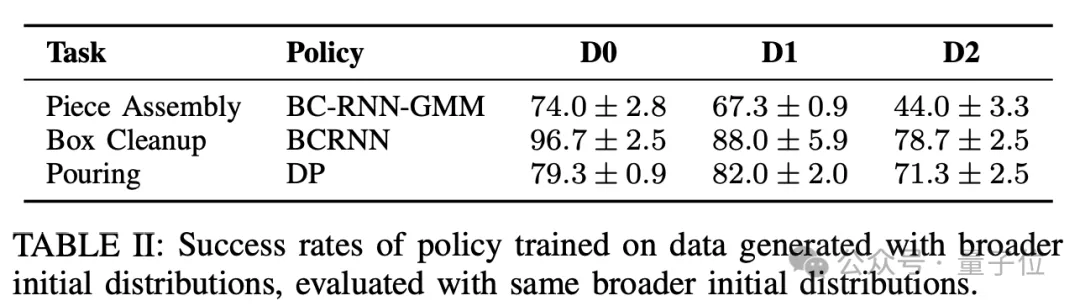
针对初始状态分布变化,DexMimicGen也体现出了较强的鲁棒性,在更广泛的初始状态分布D1和D2上测试时,仍然能够拥有一定的成功率。
DexMimicGen是由MimicGen改造而成,MimicGen也出自英伟达和UT奥斯汀的联合团队。
朱玉可和范麟熙都参与过MimicGen的工作,该成果发表于CoRL 2023。
MimicGen的核心思想,是将人类示范数据分割成以目标物体为中心的片段,然后通过变换物体相对位置和姿态,在新环境中复现人类示范轨迹,从而实现自动化数据生成。
DexMimicGen则在MimicGen系统的基础上,针对双臂机器人灵巧操作任务做了改进和扩展,具体包括几个方面:

工作流程上,DexMimicGen会首先对人类示范进行采集和分割。
研究人员通过佩戴XR头显,远程控制机器人完成目标任务,在这一过程中就会产生一小批示范数据,作者针对每个任务采集了5~10个人类示范样本。
这些人类示范样本会按照并行、协调、顺序三种子任务定义被切分成片段——
总之,在示范数据被切分后,机器人的每个手臂会得到自己对应的片段集合。

在数据生成开始时,DexMimicGen随机化模拟环境中物体的位置、姿态等数据,并随机选择一个人类示范作为参考。
对于当前子任务,DexMimicGen会计算示范片段与当前环境中关键物体位置和姿态的变换。
之后用该变换对参考片段中的机器人动作轨迹进行处理,以使执行这一变换后的轨迹能够与新环境中物体位置匹配。
生成变换后,DexMimicGen会维护每个手臂的动作队列,手指关节的运动则直接重放示范数据中的动作。
在整个过程中,系统不断检查任务是否成功完成,如果一次执行成功完成了任务,则将执行过程记录下来作为有效的演示数据,失败则将数据丢弃。
之后就是将生成过程不断迭代,直到获得足够量的演示数据。
收集好数据后,作者用DexMimicGen生成的演示数据训练模仿学习策略,策略的输入为RGB相机图像,输出为机器人动作。
最后是模拟到现实的迁移,同样地,作者使用DexMimicGen在数字孪生环境中生成的大规模演示数据,训练模仿学习策略。
之后作者对在数字孪生环境中评估训练得到的策略进行调优,以提高其泛化性能和鲁棒性,并迁移到实际机器人系统中。

DexMimicGen的共同一作有三人,都是UT奥斯汀的华人学生。
并且三人均出自李飞飞的学生、浙大校友朱玉可(Yuke Zhu)助理教授门下,他们分别是:
博士生Zhenyu Jiang,本科就读于清华,2020年进入UT奥斯汀,预计将于明年毕业;
硕士生Yuqi Xie(谢雨齐),本科是上海交大和美国密歇根大学联培,预计毕业时间也是明年;
博士生Kevin Lin,本科和硕士分别就读于UC伯克利和斯坦福,今年加入朱玉可课题组读博。
朱玉可的另一重身份是英伟达的研究科学家,团队的另外两名负责人也都在英伟达。
他们分别是Ajay Mandlekar和范麟熙(Jim Fan),也都是李飞飞的学生,Mandlekar是整个DexMimicGen项目组中唯一的非华人。
另外,Zhenjia Xu和Weikang Wan两名华人学者对此项目亦有贡献,整个团队的分工如下:

项目主页:
https://dexmimicgen.github.io/
论文地址:
https://arxiv.org/abs/2410.24185
参考链接:
[1]https://x.com/SteveTod1998/status/1852365700372832707
[2]https://x.com/DrJimFan/status/1852383627738239324
文章来自微信公众号 “ 量子位 ”,作者 克雷西



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
