# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI视频生成赛道最强搅局者,来了!
何谓搅局?下面这些是模型直出的效果,开源免费送给你!

这也让一些网友直呼:「赛博菩萨」!

虽然很想把标题写成「剑指Sora」,但可惜这个标题小编我用过了~
而蓦然回首,那惊世骇俗的Sora也已经是很久之前的事情了。
今天,我们已经可以通过亲自与开源模型交互,来体验当初的震撼。
先来个高仿版世界名画:

是不是直接梦回当年?

这算是小编目前体验过的最强开源文生视频模型了。

开放权重:https://huggingface.co/genmo/mochi-1-preview
源代码:https://github.com/genmoai/models
这个「赛博菩萨」名叫Mochi 1,来自Genmo,模型的研究预览版已经在hugging face开源(或通过磁力链接下载),Apache 2.0许可证,可免费用于个人和商业用途。
作为Genmo家最新的开源视频生成模型,Mochi 1在运动质量方面表现出色,并且具有极强的提示依从性。
除了开放权重之外,Genmo还在官网提供了免费试用Mochi 1的平台:https://www.genmo.ai/play,完全免费,只不过限制每6小时生成2个视频。
神奇的魔法世界:

海上战争:

星际穿越:

月下美人:

这些都是来自discover页面的作品,有可能是网友做的,效果包不包真咱不知道,所以小编只好下场一试:

A Chinese female college student with fair skin, slim figure, and wearing a school uniform stood next to the bookshelf in the library, smiling and looking at the camera attentively. High resolution 4k.
直出的效果小编是比较满意的,这里的动图质量有限,而且截图工具过来有点偏色,还是推荐大家亲自体验,会有惊喜。
在上面的基础上加一点细节:

A Chinese female college student with fair skin, slender figure, and wearing a school uniform is standing next to the bookshelf in the library. She has shoulder-length black short hair, a high nose bridge, and a pointed chin. She is smiling and looking at the camera attentively. High resolution 4k.
虽然但是......还行吧,可能小编的提示词功力还需修炼。
下面这张的效果最令小编惊喜,尽管有些瑕疵,但基本能上官图了吧。

A young woman wearing a white shirt and navy blue dress on the beach at sunset. She was holding high heels in her hands and walking barefoot on the beach, her long silver hair fluttering in the sea breeze. The waves gently lap on the shore, creating a fresh and elegant atmosphere. 4K ultra-high definition, delicate and realistic style.
来看一下刻板印象(doge):

In the summer, a cute Japanese high school student is on campus. She was wearing a school uniform, a short skirt, white stockings and black leather shoes. She was carrying a black schoolbag, with her hands behind her back, smiling at the camera, with the University of Tokyo building behind her.
当然肯定也有翻车的时候:

A cute girl walks on campus in summer. She was wearing her school uniform, short skirt, black stockings and boots, and was carrying a black school bag. She walks confidently and casually
翻车了吗?微翻,翻的不多,也就40%
目前Genmo只发布了生成480p视频的基础版本,而更高级的Mochi 1 HD将于今年晚些时候推出。
另外模型的相关API也已经发布,开发者可以将其无缝集成到自己的应用程序中。
hugging face上的模型权重大小为40多G,根据官方的说法,需要4个H100才能运行。
——不过别担心,既然敢开源,那么总有大神帮你解决问题:

地址:https://github.com/kijai/ComfyUI-MochiWrapper
Mochi 1已经进入ComfyUI了,可以使用flash attention、pytorch attention(sdpa)或sage attention进行加速。

根据设置的帧数,可以把生成过程限制在20GB内存以下,作者还尝试了CogVideoX -diffusers来挑战更高的帧数,目前做到了97帧。
Genmo表示自己要搞一个「人工智能的右脑」,而Mochi 1就是构建可以想象任何东西的世界模拟器的第一步。
Mochi 1是基于新型的非对称扩散Transformer(Asymmetric Diffusion Transformer,AsymmDiT) 架构构建的扩散模型。
参数量为100亿,是有史以来开源的最大视频生成模型。
Mochi 1是完全从头开始训练的,同时提供了简单、可以自由修改的架构。
计算效率对于模型的发展至关重要。与Mochi一起开源的还有它的VAE编码器。
VAE将视频压缩了128倍(包括空间压缩和时间压缩),转化到12通道的潜在空间。

AsymmDiT通过简化文本处理,并将神经网络能力集中在视觉推理上,有效地处理用户提示和压缩的视频token。
AsymmDiT通过多模态自我注意共同关注文本和视觉token,并为每种模态学习单独的MLP层,这类似于Stable Diffusion 3,所不同的是,这里的视觉流通过更大的隐藏维度(拥有几乎是文本流的 4 倍的参数)。

为了统一自我注意的模态,研究人员使用非方形QKV和输出投影层。这种非对称设计降低了推理内存要求。
许多现代扩散模型使用多个预训练语言模型来表示用户提示。相比之下,Mochi 1只使用单个T5-XXL对提示进行编码。
Mochi 1的上下文窗口高达44,520个视频token,并具有完整的3D attention。
为了定位每个token,研究人员将可学习的旋转位置嵌入(RoPE)扩展到3维,网络端到端学习空间轴和时间轴的混合频率。
其他的设计包括SwiGLU前馈层、用于增强稳定性的query-key normalization,以及用于控制内部激活的sandwich normalization。
详细的技术论文将在不久之后发布。
当前的视频生成模型与现实之间存在巨大差距。运动质量和提示遵循是视频生成模型中仍然缺少的两个最关键的功能。
Mochi 1为开源视频生成设定了新的标准,对比领先的封闭模型也表现出很强的竞争力:
提示依从性衡量生成的视频遵循提供的文本说明的准确性,从而确保对用户意图的高度保真度。模型应该允许用户对字符、设置和操作进行详细控制。
研究人员使用视觉语言模型作为裁判,遵循OpenAI DALL-E 3协议,使用自动指标对提示依从性进行基准测试。这里使用 Gemini-1.5-Pro-002评估生成的视频。
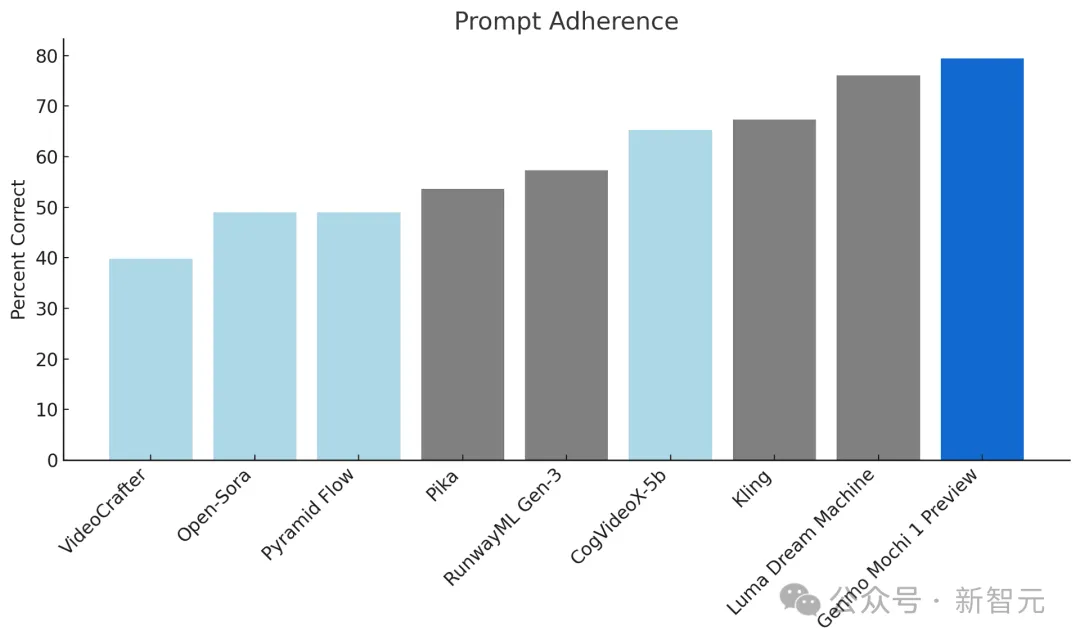
运动质量评估运动平滑度和空间真实感,确保生成的视频流畅且具有视觉吸引力。
Mochi 1 以每秒30帧的速度生成流畅的视频,持续时间长达5.4秒,具有高度的时间连贯性和逼真的运动动态。
Mochi模拟流体动力学、毛皮和头发等物理特性,以及一致、流畅的人类动作,不存在恐怖谷问题。
评分者根据运动而不是帧级美学(标准包括运动的趣味性、物理合理性和流动性)来进行打分。Elo分数是按照LMSYS Chatbot Arena协议计算的。
Mochi 1目前仍处于不断发展的状态,存在一些已知的限制。
比如初始版本只能生成480p的视频,比如在某些极端运动的边缘情况下,可能会出现轻微的扭曲。
由于Mochi 1针对照片级真实感样式进行了优化,因此在动画内容中表现不佳。
此外,模型实施了强大的安全审核协议,以确保所有视频都保持安全并符合道德准则。
Mochi 1的开源在各个领域开辟了新的可能性:
研发:推进视频生成领域并探索新方法。
产品开发:在娱乐、广告、教育等领域构建创新应用程序。
创意表达:使艺术家和创作者能够通过AI生成的视频将他们的愿景变为现实。
机器人:生成合成数据,用于在机器人、自动驾驶汽车和虚拟环境中训练AI模型。
Genmo近日宣布已经成功筹集了2840万美元的A轮融资,该轮融资由Rick Yang、NEA领投,The House Fund、Gold House Ventures、WndrCo、Eastlink Capital Partners和Essence VC,以及天使投资人Abhay Parasnis(Typespace 首席执行官)、Amjad Masad(Replit 首席执行官)、Sabrina Hahn、Bonita Stewart和Michele Catasta等参投。
Genmo团队包括DDPM(去噪扩散概率模型)、DreamFusion和Emu Video等项目的核心成员,由领先的技术专家提供咨询,包括 Ion Stoica(Databricks和Anyscale的执行主席兼联合创始人)、Pieter Abbeel(Covariant的联合创始人、OpenAI的早期团队成员)和 Joey Gonzalez(语言模型系统的先驱、Turi的联合创始人)。
Genmo表示将在今年年底之前,发布Mochi 1的完整版,其中包括 Mochi 1 HD。
Mochi 1 HD将支持720p视频生成,具有更高的保真度和更流畅的运动,可解决复杂场景中的翘曲等边缘情况。
除此之外,团队还在开发图像到视频功能,并专注于提高模型的可控性和可操控性,以便用户能够更精确地控制自己的输出。
展望未来,高分辨率、长视频生成将触手可及。
参考资料:
文章来自于微信公众号“新智元”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
