# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本篇论文已被 NeurIPS 2024 Dataset & Benchmark Track 接收,作者来自上海交通大学 IWIN 计算智能团队和上海人工智能实验室。其中,第一作者王骥泽是上海交通大学自动化系一年级博士生,研究方向涉及大模型智能体、自然语言处理。
利用语言模型调用工具,是实现通用目标智能体(general-purpose agents)的重要途径,对语言模型的工具调用能力提出了挑战。然而,现有的工具评测和真实世界场景存在很大差距,局限性主要体现在以下几个方面:
为了突破这些局限,来自上海交通大学与上海人工智能实验室的研究团队提出了 GTA(a benchmark for General Tool Agents),一个用于评估通用工具智能体的全新基准,主要特性包括:
GTA 通过设计真实世界场景的用户问题、真实部署的工具和多模态输入,建立了一个全面、细粒度的评估框架,能够有效评估大语言模型在复杂真实场景下的工具使用能力。


GTA 中的用户问题与现有工具评测的用户问题对比如下表所示。ToolBench 和 m&m's 中的问题明显地包含了需要调用的工具(蓝色字)以及步骤(红色字)。APIBench 中的问题较为简单,仅包含单个步骤。相较而言,GTA 的问题既是步骤隐含的,也是工具隐含的,并且是基于现实世界场景的、对人类有帮助的任务。

GTA 的评估结果表明,GPT-4 在面对真实世界问题时仅完成不到 50% 的任务,而大多数模型完成率低于 25%。揭示了现有模型在处理真实世界问题时面临的工具使用瓶颈,为未来的通用工具智能体提供了改进方向。
GTA 主要有三个核心特性,来评估大语言模型在真实世界场景下的工具使用能力:
数据集构建流程包含两个步骤:
1. 问题构建。专家设计问题样例和标注文档,标注人员按照标注文档中的指示,进行头脑风暴,基于问题样例设计更多的问题,最终得到问题集。
2. 答案构建。标注人员手动调用部署好的工具,确保每个问题都可以用提供的工具解决。然后,标注人员根据工具调用过程和工具返回结果,对每个问题的工具调用链进行标注。
为了让评测集更全面地覆盖真实场景,研究团队采用了多样化的扩展策略,包括场景多样化、工具组合多样化等。最终得到的评测集包含多图推理、图表分析、编程、视觉交互、网页浏览、数学、创意艺术等多种场景,确保了评估任务的全面性和多样性。

最终共得到 229 个真实场景下的任务,所有问题都隐含工具和步骤,并且包含多模态上下文输入。这些任务基于现实世界场景,目标明确且易于理解,完成任务对人类有帮助,但对于 AI 助手来说较为复杂。JSON 格式的数据示例可以在 Hugging Face 上找到。

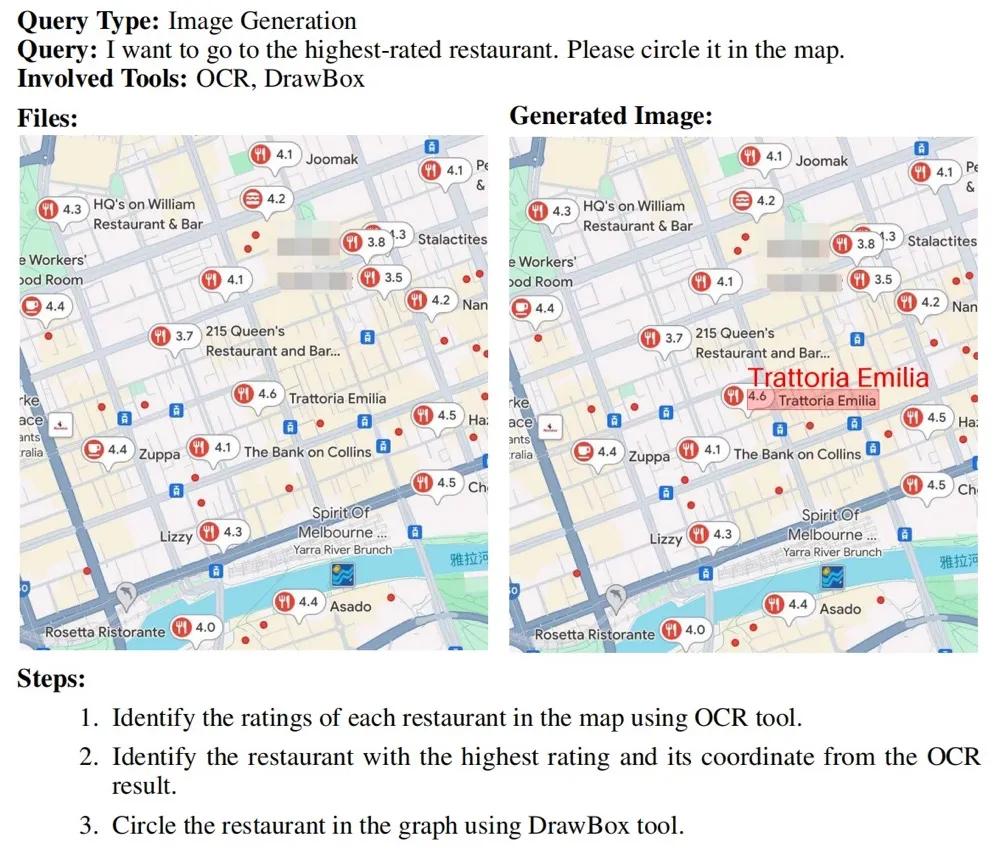


GTA 在两种模式下评估语言模型:
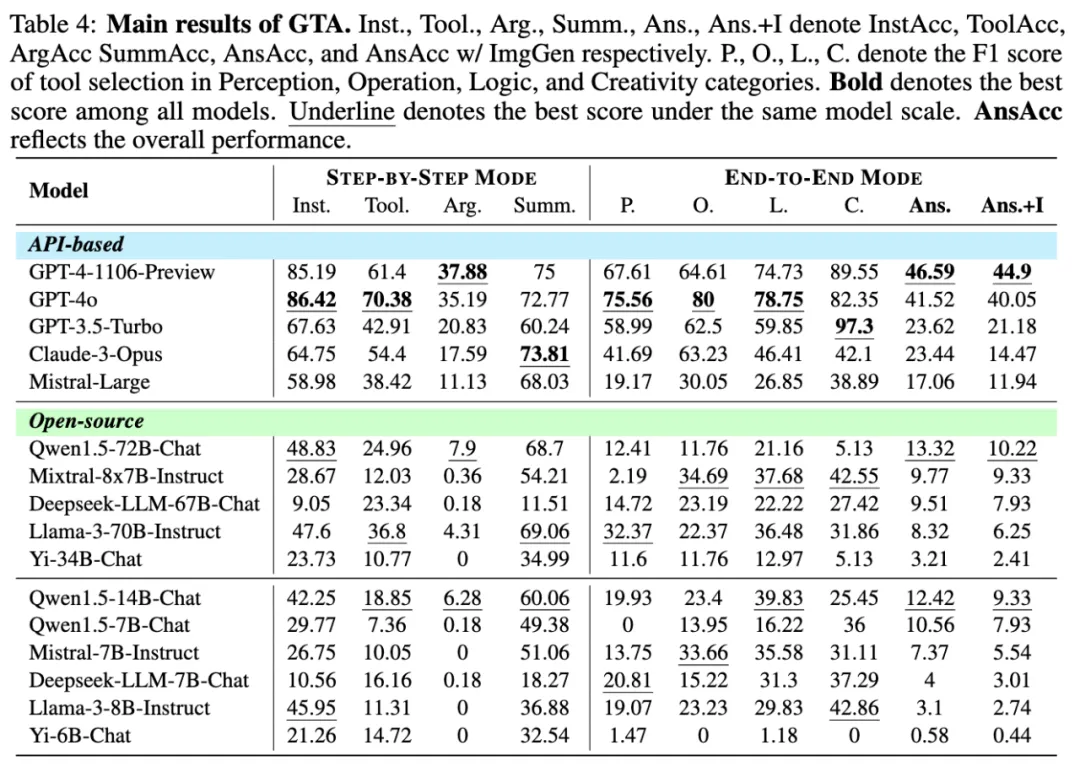
评测结果表明,目前的大语言模型在复杂真实场景任务的工具调用上仍存在明显的局限性。GPT-4 在 GTA 上仅能完成 46.59% 的任务,而大多数模型仅能完成不到 25% 的任务。
研究团队发现,目前语言模型在完成 GTA 任务的关键瓶颈是参数传递准确率。研究人员计算了各指标与最终结果准确率 AnsAcc 之间的皮尔森相关系数,发现 ArgAcc 的相关系数最高,说明参数传递是目前大多数模型的瓶颈。例如,Llama-3-70B-Chat 的 InstAcc,ToolAcc,SummAcc 都比 Qwen1.5-14B-Chat 高,但 ArgAcc 比 Qwen1.5-14B-Chat 低,导致最终结果准确率更低。
为了进一步理解模型在参数传递上的失误原因,研究团队选择两个典型模型 GPT-4-1106-Preview 和 Llama-3-8B-Instruct,对它们进行了深入的错误原因分析,如下表所示。

分析显示,GPT-4 与 Llama-3 的错误分布存在显著差异。GPT-4 模型倾向于生成 “无动作”(No Action)的响应,在 38.7% 的错误中,GPT-4 尝试与用户互动,错误地认为问题表述不够明确,要求提供额外信息。而在 50% 的错误中,模型仅生成内部思考过程,而未采取实际行动。
而 Llama-3 的大部分错误来自于格式错误,特别是调用工具或生成最终答案时。45.4% 的错误是由于参数未能遵循合法的 JSON 格式。此外,在 16.5% 的情况下,Llama-3 试图同时调用多个工具,这并不被智能体系统支持。19.6% 的错误则源于生成冗余信息,导致参数解析不正确。
本文构建了面向复杂真实场景的通用工具智能体(General Tool Agents)评测基准:
文章来自于微信公众号“机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
