# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天分享两份英伟达关于GB200的技术文章,我将PPT原文分别贴在文章解读下方供大家学习。
1.NVIDIA DGX GB200 超级计算集群数据中心部署指南解读
2.NVIDIA AI 工厂部署与 Broadcom AI 计算 ASIC 光学连接技术
NVIDIA DGX GB200 超级计算集群数据中心部署指南解读这份 NVIDIA 文件主要介绍了如何为 DGX GB200 超级计算集群设计和部署数据中心设施 (DCF),着重强调了高性能计算对数据中心供电、冷却和空间规划带来的挑战,并提出了基于开放计算项目 (OCP) ORv3 标准机架的解决方案。
以下是主要内容解读:
1. 高性能计算带来的挑战加速计算对数据中心的功耗要求越来越高。以 Blackwell 集群为例,高性能方案也意味着更高的能源效率和可持续性。DGX GB200 系统每机架功耗高达 130kW,需要特殊的散热解决方案,例如液冷技术。传统数据中心布局难以满足高密度机架的电力和冷却需求。"Attendees will learn how to design and implement a typical data center to optimally house, power and cool a DGX SuperPOD for GB200."
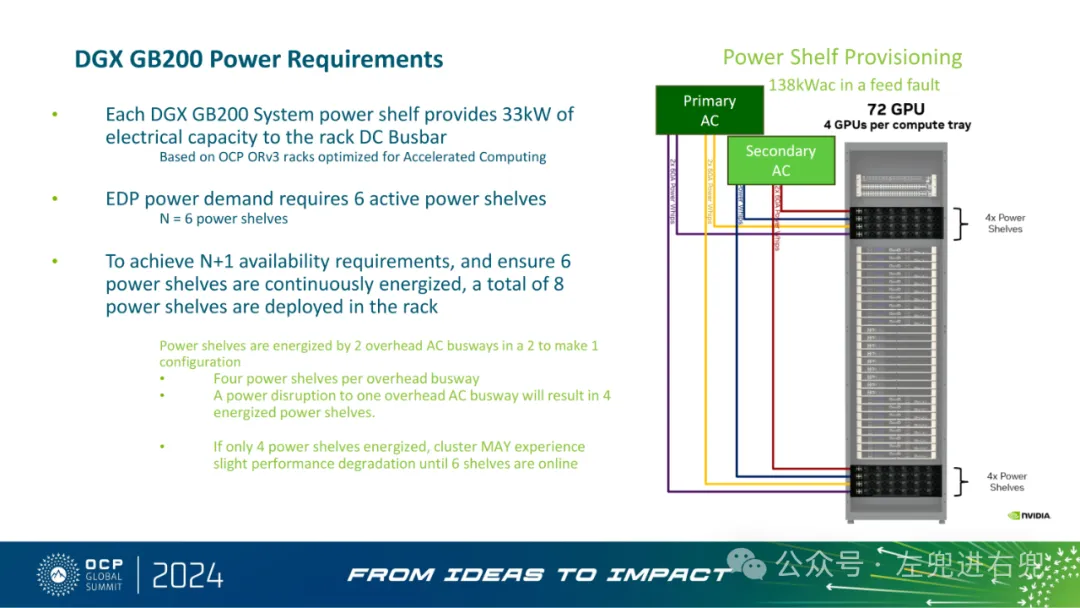
2. DGX GB200 超级计算集群规模和基础设施DGX GB200 超级计算集群的规模以 GPU 数量为基准,典型的规模包括 288、576 和 1152 个 GPU。除了 DGX GB200 系统,每个超级计算集群还需要网络和管理机架。例如,一个 288 GPU 的超级计算集群包含一个管理服务器机架、三个网络机架和一个线缆管理机架。每个 DGX GB200 系统的电源架为机架直流母线提供 33kW 的电力容量。为了实现 N+1 可用性,每个机架需要部署 8 个电源架。"DGX GB200 SuperPODs are sized based on the number of GPUs they contain"
3. 基于 OCP ORv3 标准机架的解决方案OCP ORv3 机架针对加速计算进行了优化,可以支持高密度机架的电力和冷却需求。电源架通过 4 个架空交流母线供电,采用 4 选 3 的冗余配置,即使一个母线断电,仍然可以保证 6 个电源架正常工作。机架内部采用液冷技术,冷却液分配单元 (CDU) 由独立的机械动力模块供电,可以隔离泵电机引起的电能质量问题和谐波。机架间和机架内的铜缆和光缆通过架空线缆桥架进行管理,确保线缆桥架不会与电力和管道路径冲突。"Based on OCP ORv3 racks optimized for Accelerated Computing"
4. 行级电源系统配置示例采用 4 选 3 母线配置,不包括 CDU。网络线缆桥架位于机架前方。网络和管理机架的负载均衡分配在 4 个母线上。
5. 行动呼吁了解 DGX GB200 NVL72 对数据中心供水、送风和供电的多方面需求。将这些需求与传统数据中心布局进行比较。在现有电力限制范围内,为更高的每机架功率做好数据中心电力、空间和冷却方面的准备,以实现更高的每瓦性能和每美元性能加速计算。
总结:部署 DGX GB200 超级计算集群需要对数据中心进行全面规划和设计,以满足其高性能计算带来的电力、冷却和空间需求。基于 OCP ORv3 标准机架的解决方案可以有效解决这些挑战,并实现高性能、高效率和高可靠性的目标。
一、NVIDIA AI 工厂部署
1. 背景加速计算已成为功率受限数据中心的最佳解决方案。NVIDIA Blackwell 集群的部署体现了这一方法,其中性能最高的解决方案也是最节能和可持续的。
2. 目标指导与会者如何设计和实施典型数据中心,以最佳方式容纳、供电和冷却 DGX SuperPOD (GB200)。分享 NVIDIA DGX SuperPOD (DGX GB200 系统) 的数据中心初步设计指南。展示基于 OCP ORv3 和 NVIDIA MGX 贡献的机架,以展示其可扩展性。
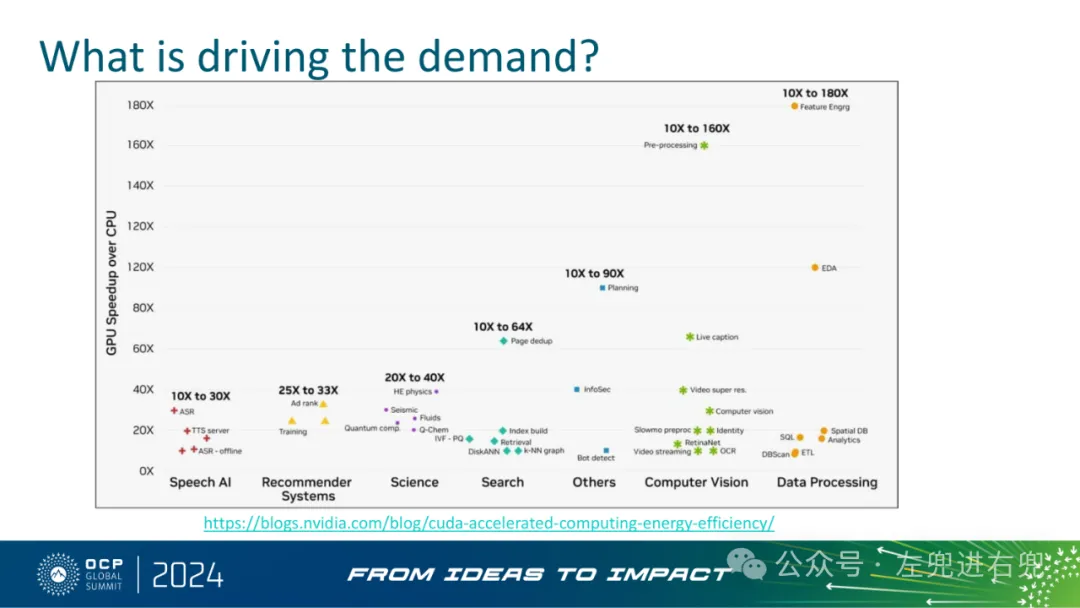
3. 需求驱动因素对更高性能计算的需求推动了对加速计算解决方案的需求。
4. 关键技术细节DGX GB200 SuperPOD 规模: 基于 GPU 数量确定规模,支持 288、576、1152 个 GPU 等规模,以及更大规模部署。DGX GB200 电源要求: 单机架功耗高达 130kW,需要特殊的电源和冷却解决方案。机架设计: 基于 OCP ORv3 标准,采用 NVIDIA MGX 贡献,优化了加速计算。电源冗余: 采用 N+1 冗余设计,确保高可用性。冷却系统: 采用液冷方案,并与机架电源系统隔离,以减少谐波干扰。线缆管理: 采用顶部线缆槽,方便线缆管理。
5. 挑战与解决方案了解 GB200 NVL72 的多设施水源、气源和电源需求。将这些需求与传统数据中心布局进行比较。在现有功率限制内,为机架更高的功率密度做好数据中心的电源、空间和冷却准备,以实现更高的每瓦性能和每美元性能。
6. 行动呼吁参加 NVIDIA 关于 MGX 对 ORv3 贡献的服务器会议,以支持加速计算。
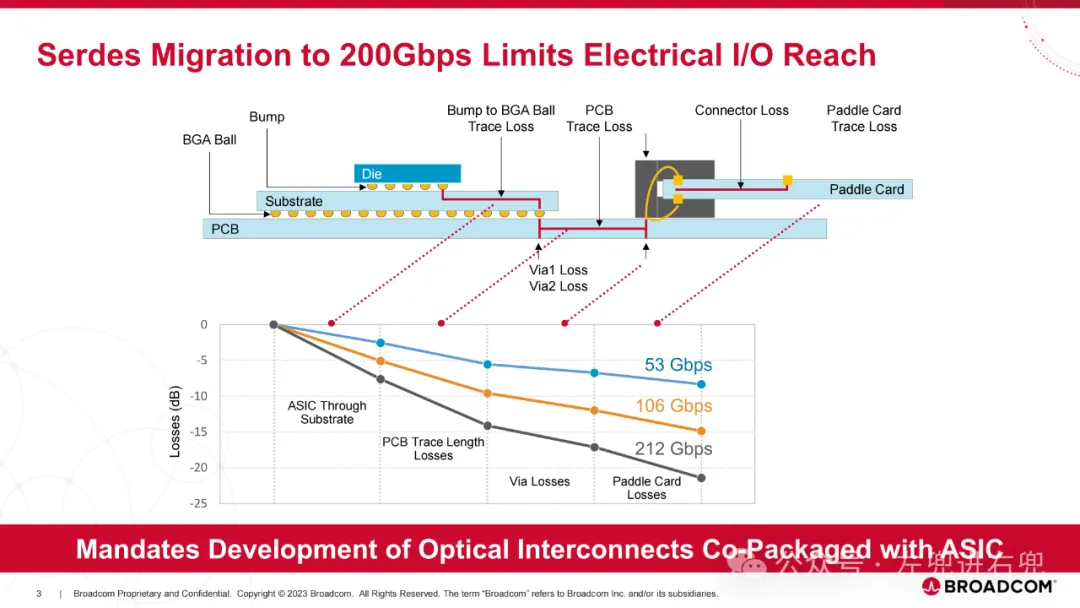
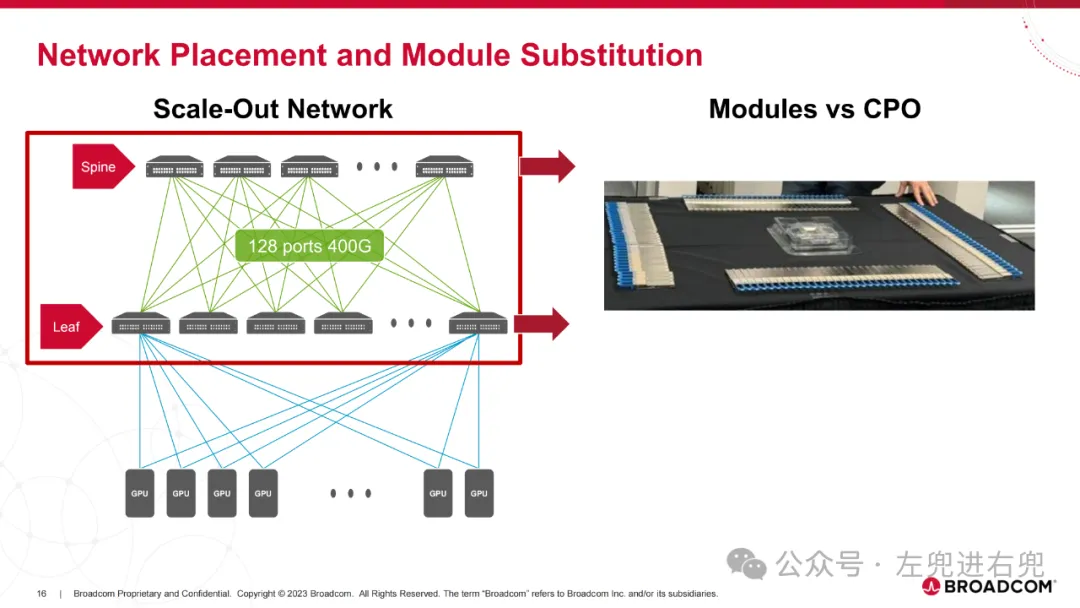
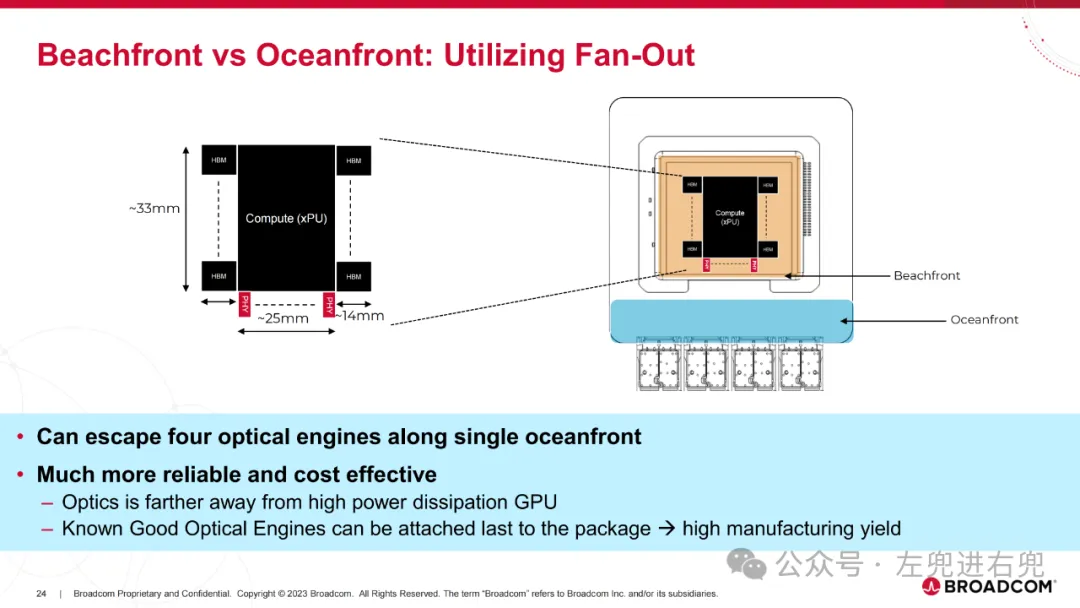
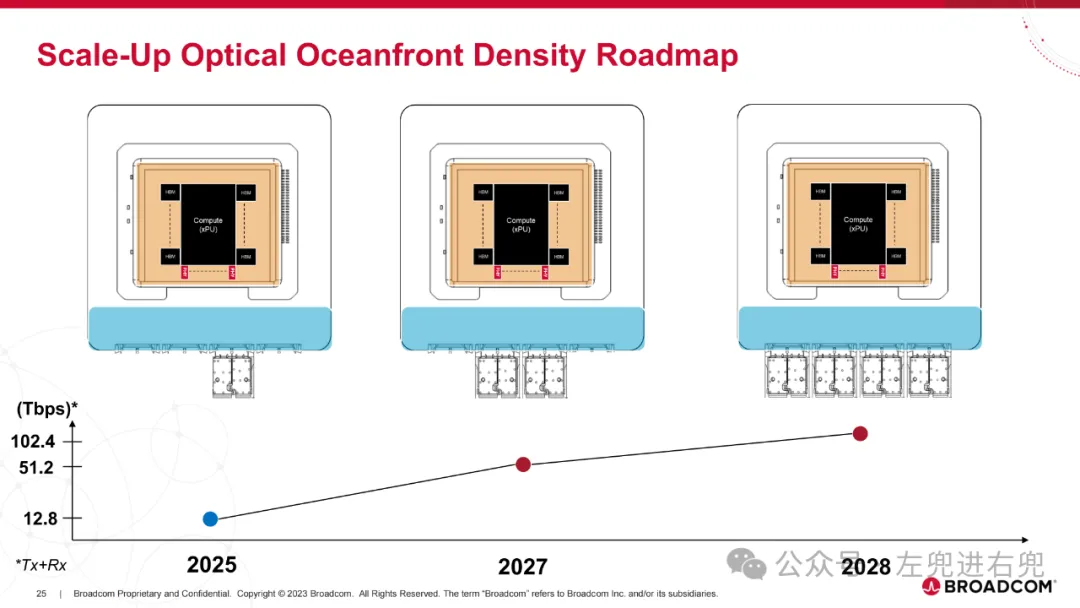
1. 目标构建光学互连,在成本、功耗、可靠性和延迟方面比当前光模块有实质性改进。构建高密度光学互连,支持高达 1 Tb/s/mm 的双工连接,以支持当前和下一代纵向扩展和横向扩展光带宽密度。
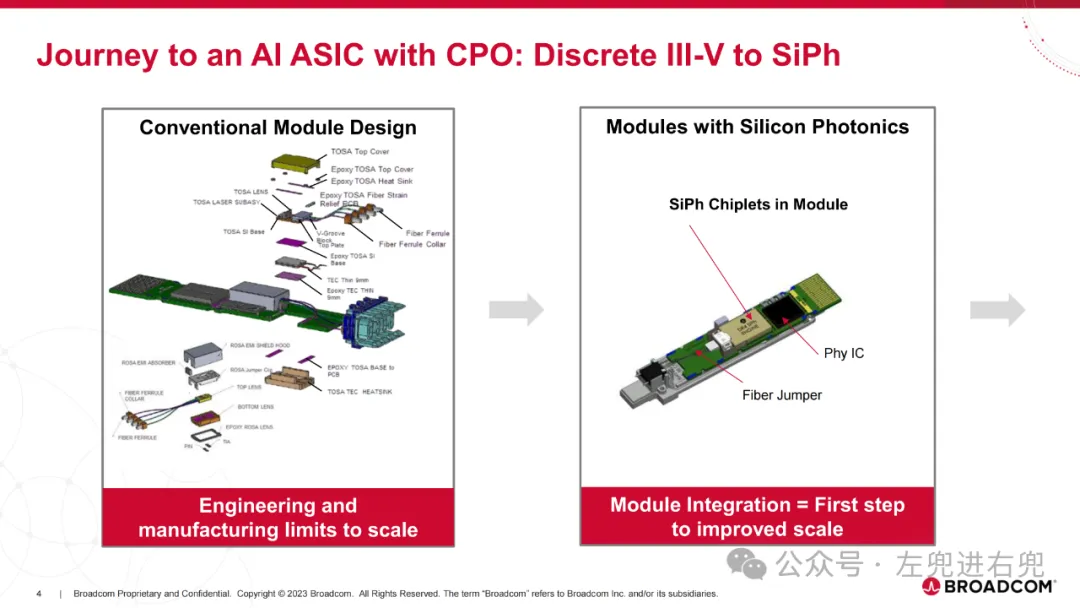
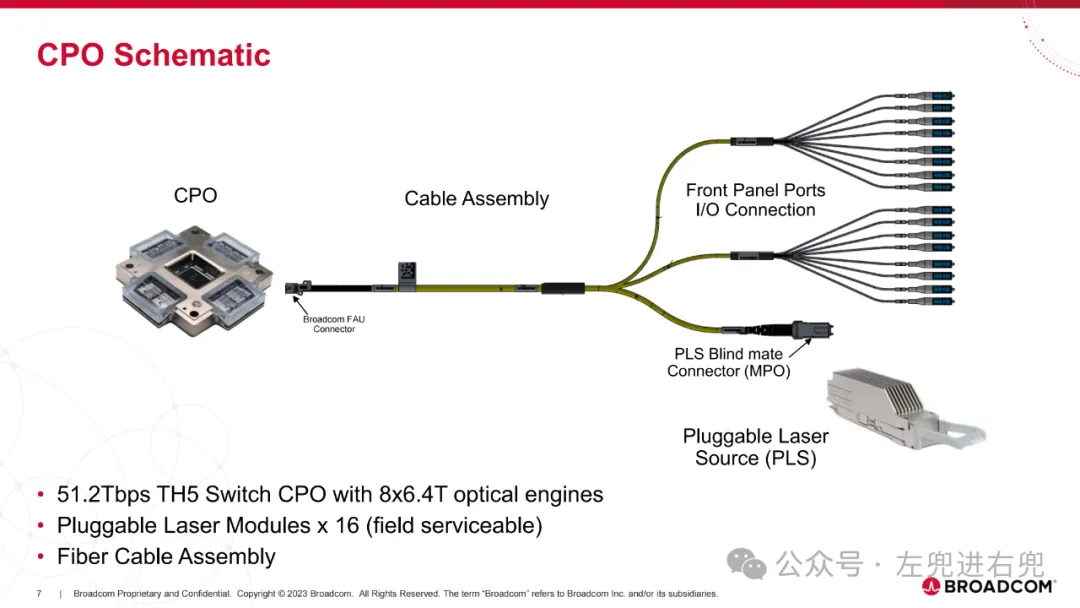
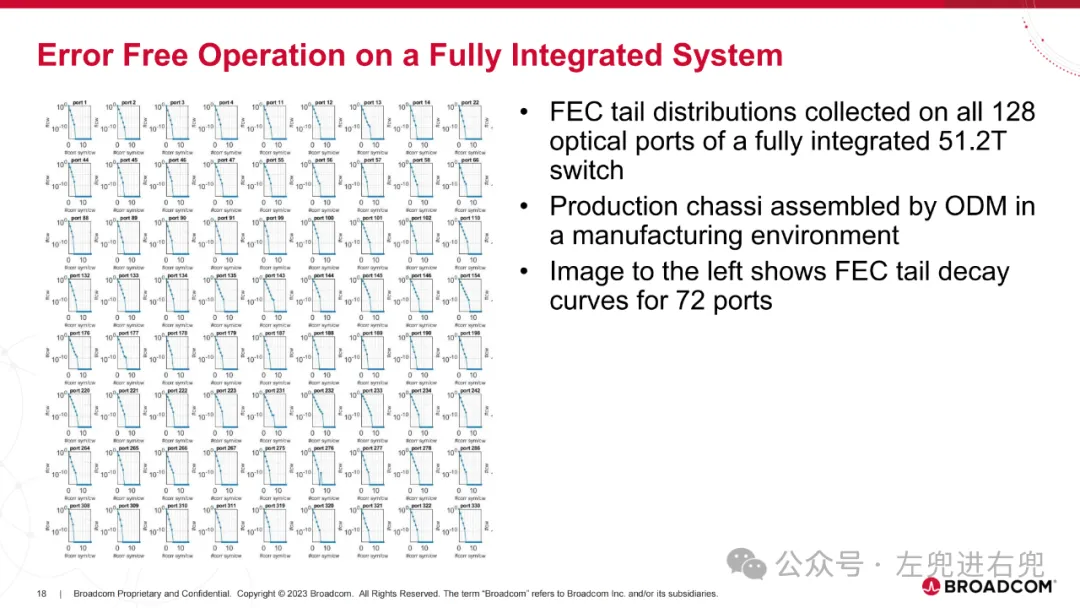
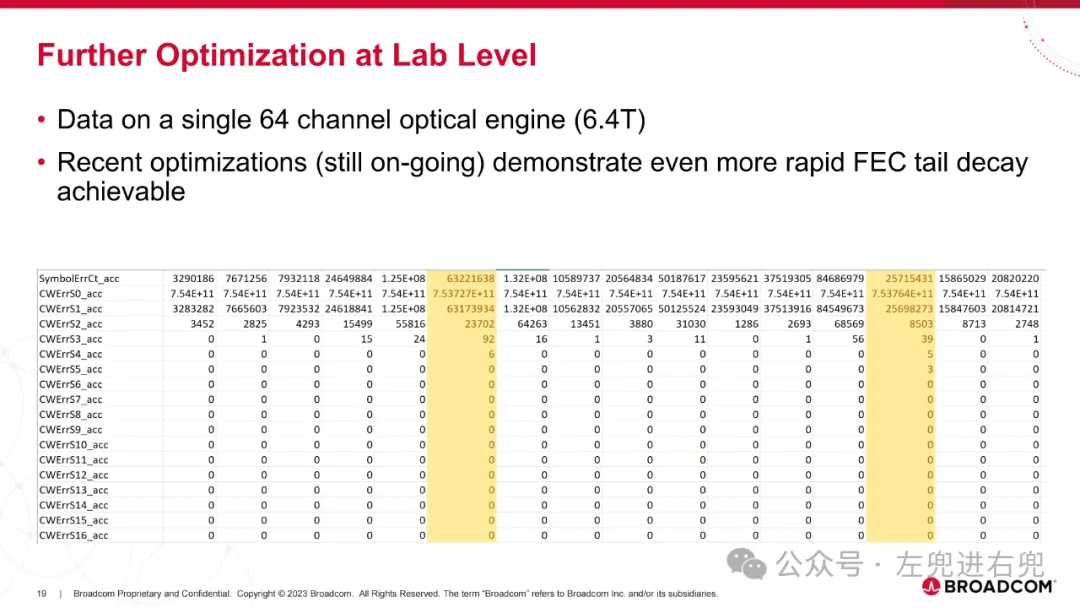
2. 进展已交付第一代概念验证 25.6T CPO 交换机产品。目前正在认证和量产第二代 51.2T CPO 交换机产品。展示了 AI ASIC + CPO 功能:CPO + 2.5D 封装。
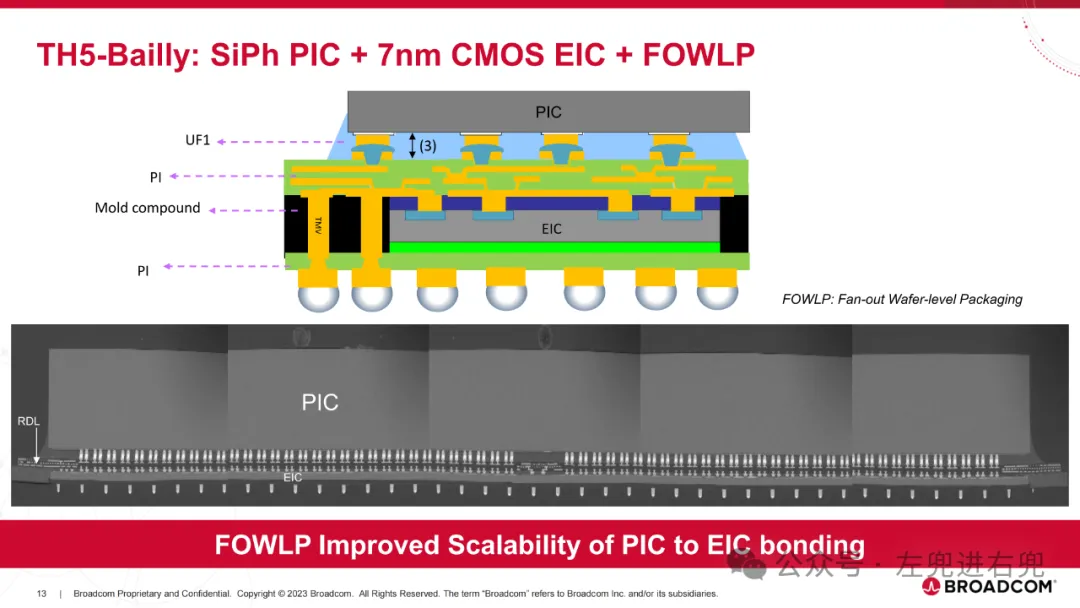
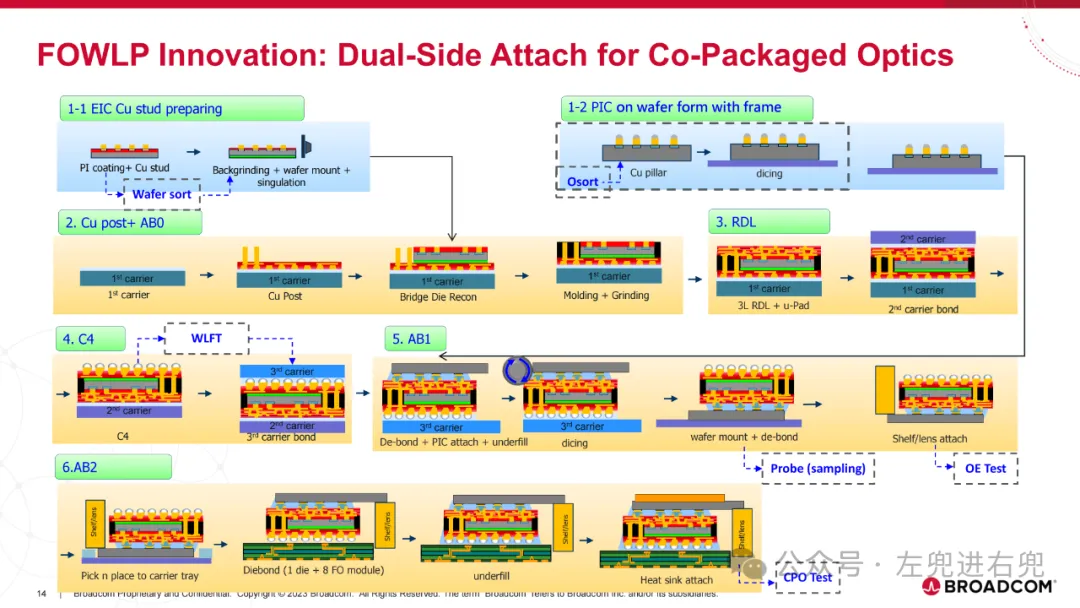
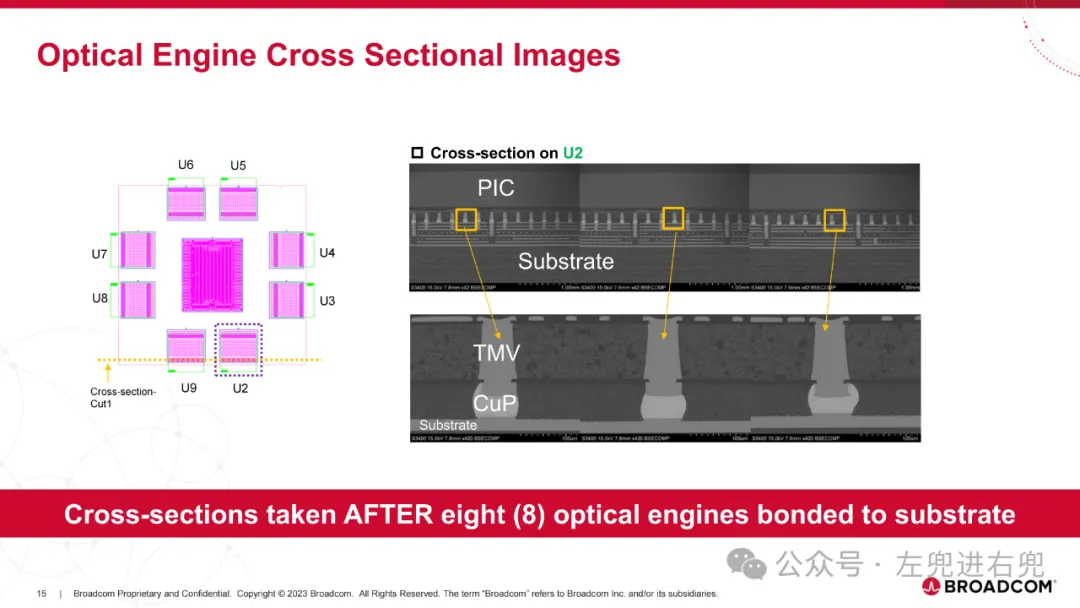
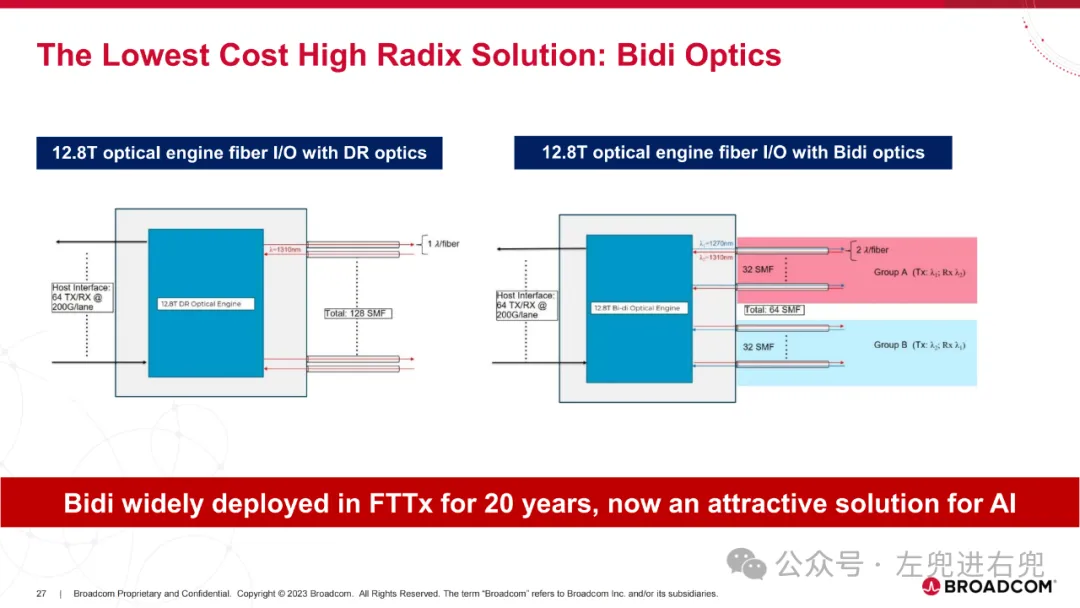
3. 关键技术共封装光学 (CPO): 将光学组件直接封装在 ASIC 芯片上,提高性能、降低功耗。硅光子学 (SiPh): 使用硅基光学器件,降低成本,提高集成度。高密度光纤连接器: 支持更高的带宽密度。先进封装技术: 实现高密度集成。
4. 应用场景纵向扩展网络: 用于数据中心 Spine 和 Leaf 交换机之间的高带宽连接。纵向扩展计算: 用于连接多个 GPU,实现高性能计算。
5. 优势降低功耗: 相比传统光模块,CPO 可以显著降低功耗。提高带宽密度: CPO 支持更高的带宽密度,满足未来 AI 计算需求。降低成本: SiPh 技术和先进封装技术可以降低成本。
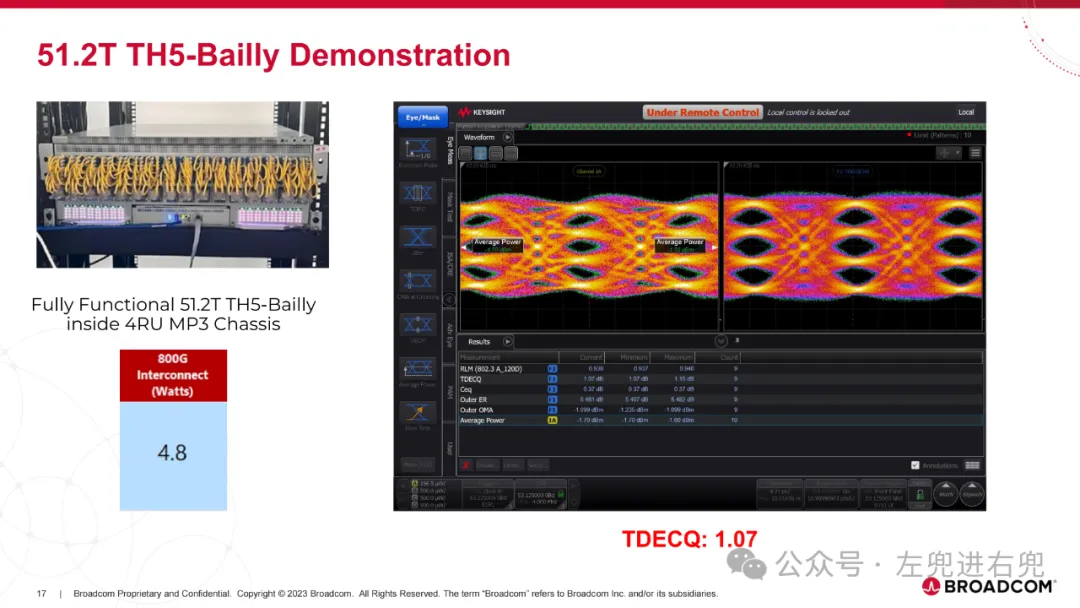
6. 案例分析TH4-Humboldt: 第一代 CPO 交换机,采用 SiGe EIC,功耗较高。TH5-Bailly: 第二代 CPO 交换机,采用 7nm CMOS EIC,功耗更低,性能更高。
7. 未来展望CPO 技术将继续发展,支持更高的带宽密度和更低的功耗。CPO 将成为未来 AI 计算的关键技术之一。
NVIDIA 的 AI 工厂部署方案和 Broadcom 的 AI 计算 ASIC 光学连接技术为构建高性能、低功耗、可扩展的 AI 基础设施提供了重要支撑。
引用"加速计算已成为功率受限数据中心的最佳解决方案。我们的 Blackwell 集群部署例证了这种方法。"
"我们的目标是构建光学互连,在成本、功耗、可靠性和延迟方面比当前光模块有实质性改进。" (摘自 "61_HC2024.Broadcom.ManishMehta.v2-NO-VIDEO.pdf")
"对于一个 32k GPU 集群,可以实现超过 1MW 的功耗节省。"




































文章来自于“左兜进右兜”,作者“右兜”。




