# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Segment Anything Model 2(SAM 2)在传统视频目标分割任务大放异彩,引起了众多关注。然而,港中文和上海 AI Lab 的研究团队发现 SAM 2 的贪婪选择策略容易陷入「错误累积」的问题,即一次错误的分割掩码选择将影响后续帧的分割结果,导致整个视频分割性能的下降。这个问题在长视频分割任务中显得更加严重。
针对这些挑战,该研究团队近日推出了全新的 SAM2Long。在 Segment Anything Model 2(SAM 2)的基础上,提出了创新的记忆结构设计,打造了专为复杂长视频的分割模型。


SAM2Long 采用了一种全新的多路径记忆树结构,使得模型可以在每一帧处理时探索多种可能的分割路径,并根据综合得分选择最佳路径进行后续帧的分割。这种设计避免了单一错误掩码对整个视频的影响,使得 SAM2Long 在处理遮挡、目标重现等长视频常见问题时表现得更加稳健。
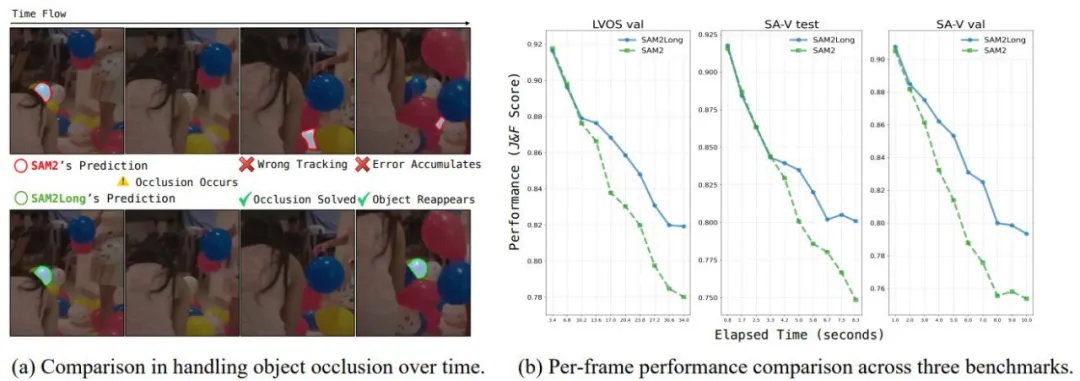
定性和定量对比 SAM 2 和 SAM2Long 处理遮挡和长时间的性能。
SAM 2 是一种用于图像和视频对象分割的基础模型。与 SAM 不同,SAM 2 引入了一个内存模块,该模块利用先前帧的信息和提示帧特征来帮助当前帧的分割。在视频对象分割任务中,SAM 2 会在每个时间步 t 上维护一个内存库,存储最近 N 帧的特征。每个内存条目包含空间嵌入和对象指针,通过这些信息,SAM 2 能够生成当前帧的分割掩码,并预测掩码的 IoU 分数和遮挡分数。SAM 2 采用贪婪选择策略,选择最高 IoU 的掩码作为最终预测,并存储其对应的内存指针。
为了提高 SAM 2 在长视频中的鲁棒性,SAM2Long 引入了多路径记忆树结构。该结构允许模型在每个时间步上保留多个分割路径假设,每条路径都有独立的内存库和累积得分。每个时间步上,SAM2 的掩码解码器在每条路径会生成三个掩码候选。
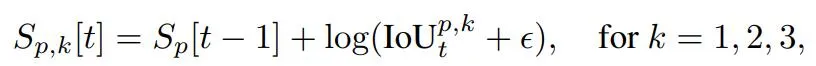
为了防止路径数量过多引起计算和内存开销过高,SAM2Long 实施了剪枝策略。我们计算每个掩码累积 IoU 得分,只保留得分最高的 P 条路径。
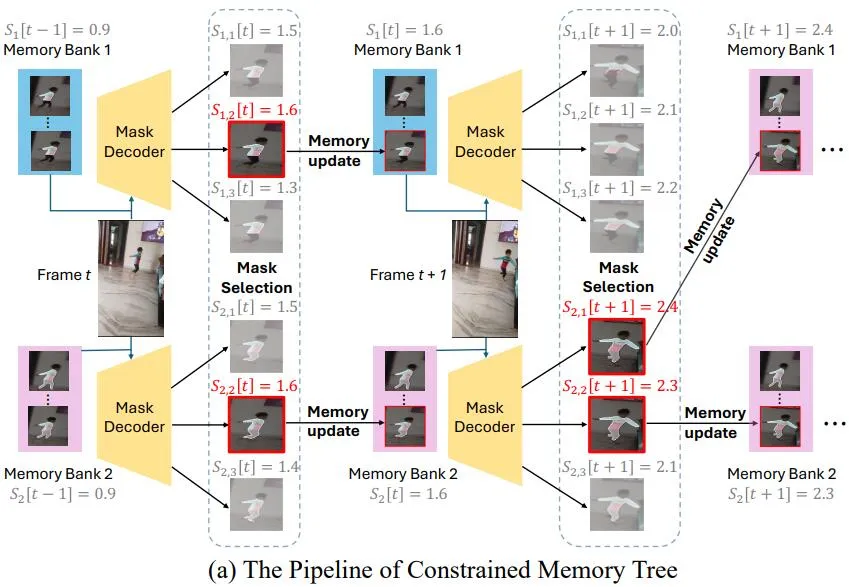
此外,SAM2Long 在处理不确定场景时,利用遮挡分数进行不确定性处理。当所有路径的遮挡分数都较低时,意味着模型对输出的结果不确定。在这种情况下,SAM2Long 会强制选择不同 IoU 值的掩码路径,以避免错误路径的过早收敛。
相比 SAM 2,SAM2Long 增加了额外的计算需求,主要体现在掩码解码器和内存模块的多次处理上。然而,这些模块相较于图像编码器来说非常轻量。例如,SAM 2-Large 的图像编码器包含 212M 个参数,而模型其余的参数只有 12M,大约仅占模型的 5%。
因为 SAM2Long 也只需要处理一次图像编码器,所以内存树结构的引入几乎不会增加显著的计算成本,但却显著提高了模型在长时间视频场景中的鲁棒性和对错误的恢复能力。
在每条路径中,SAM2Long 使用物体感知的内存选择策略,通过筛选出具有较高 IoU 分数和没有遮挡的帧,只将高质量的有物体的帧加入记忆内存库。
此外,SAM2Long 对每个内存帧的遮挡分数进行排序,遮挡分数越高,表示该帧中的目标对象越清晰、遮挡越少。为了充分利用这些高质量的帧,SAM2Long 通过以下几个步骤来调整每个内存帧在注意力计算中的权重。
首先,定义一组线性分布的标准权重,用于对内存中的帧进行加权。这些权重在一个预定义的范围 [w_low, w_high] 之间线性分布,较高的权重将分配给那些重要的内存帧。
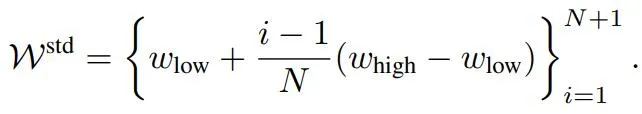
然后,对每个内存帧的遮挡分数进行排序,得到一个按遮挡分数从低到高排列的帧索引序列。根据遮挡分数的排序结果,将标准权重分配给对应的内存帧,遮挡分数越高的帧用越大的权重线性缩放该帧的特征表示。
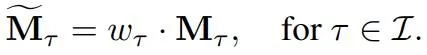
最后,使用经过加权调整的内存帧作为输入,进行跨帧的注意力计算。这样,遮挡分数高的帧(表示对象存在且分割质量高)会对当前帧的分割结果产生更大的影响。
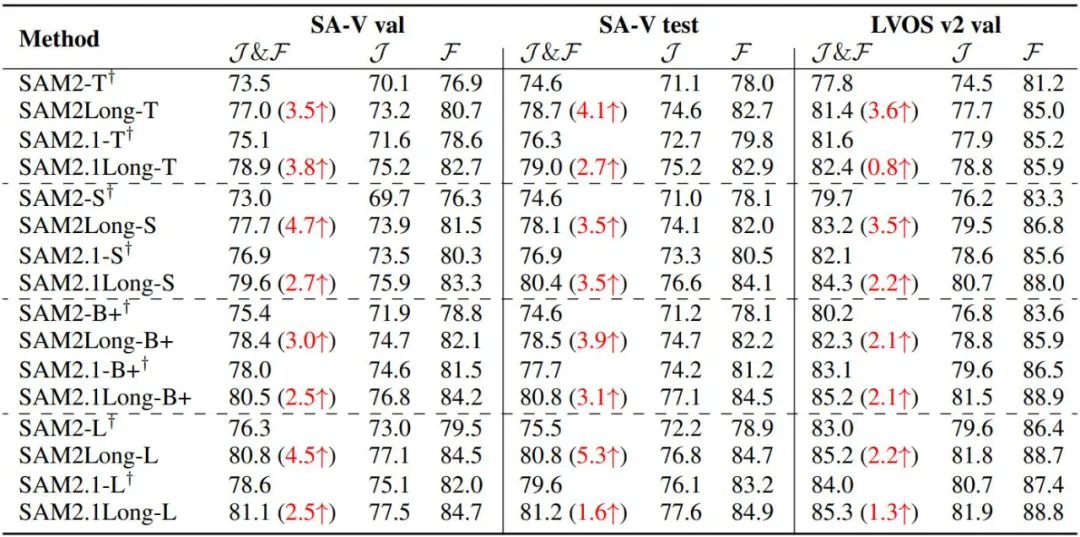
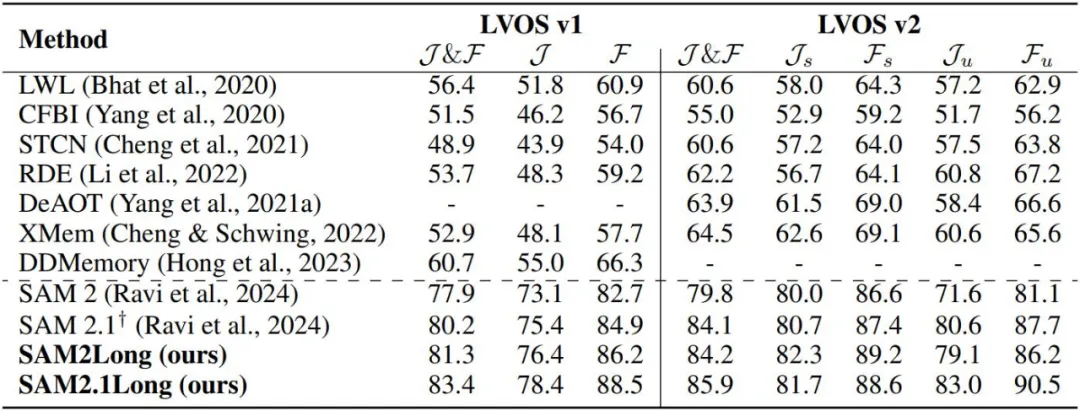
我们对 SAM 2 和 SAM2Long 在不同模型规模和多个数据集上的表现进行了详细对比。在 SA-V 验证集和测试集以及 LVOS v2 验证集上的实验结果显示,SAM2Long 无论在何种模型规模下,均显著超越了 SAM 2。表中共包含了 8 种模型变体,涵盖了 SAM 2 和最新的 SAM 2.1 在四种模型规模下的表现。24 次实验的平均结果表明,SAM2Long 在 J&F 指标上平均提高了 3.0 分。
其中,SAM2Long-Large 在 SA-V 验证集和测试集上,分别比 SAM 2 提升了 4.5 和 5.3 分。在 LVOS 验证集上,各个模型规模下的 SAM2Long 也都展示了显著的性能提升。此结果证明了我们的无训练内存树策略在长时间视频分割中的高效性,大大提升了模型在长视频对象分割中的鲁棒性。
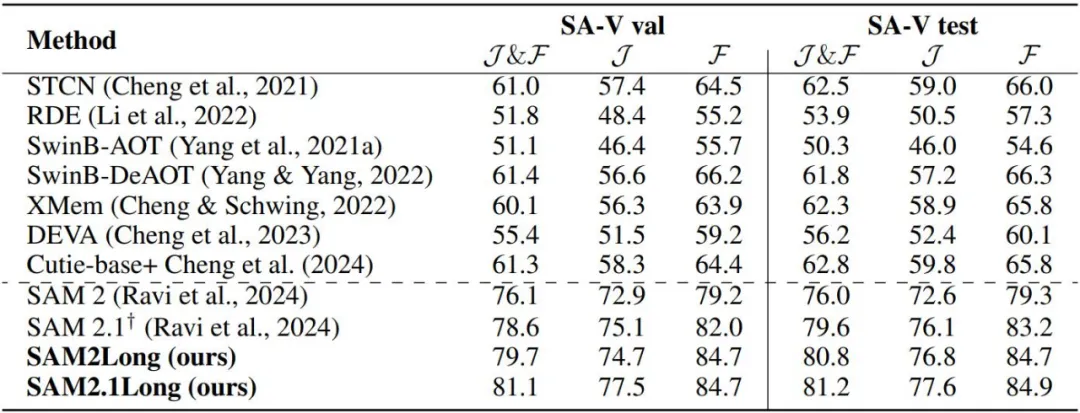
我们还将 SAM2Long 与当前最先进的视频对象分割方法进行了对比。尽管 SAM 2.1 已经在众多数据集上显著超越了现有方法,但 SAM2.1Long 将这一成绩推向了更高的水平。特别是在 SA-V 验证集上,SAM2.1Long 的 J&F 得分为 81.1,较 SAM 2.1 提升了 2.5 分。在 LVOS 数据集中,SAM2.1Long 在 v1 和 v2 子集上分别达到了 83.4 和 85.9 的 J&F 得分,分别比 SAM 2.1 提升了 3.2 和 1.8 分。
除了在 SA-V 和 LVOS 数据集上的出色表现外,我们还在其他视频对象分割基准测试上对 SAM2Long 进行了评估。在复杂的现实场景 MOSE 数据集上,SAM2.1Long 的 J&F 得分为 75.2,超越了 SAM 2.1 的 74.5 分。特别是在 MOSE 基准上,SAM 2.1-Large 并未相较 SAM 2-Large 带来性能提升,因此 SAM2.1Long 在该基准上取得的显著改进显得尤为突出。

同样,在关注对象变形的 VOST 数据集上,SAM2.1Long 的 J&F 得分为 54.0,较 SAM 2.1 提升了接近 1 分。而在 PUMaVOS 数据集上,SAM2.1Long 也以 82.4 分超越了 SAM 2.1 的 81.1 分,证明了其在处理复杂和模糊分割任务时的强大能力。
这些结果表明,SAM2Long 在保留 SAM 2 基础分割能力的同时,显著增强了其长时间视频场景下的表现,展现了其在不同 VOS 基准数据集上的鲁棒性和通用性。
SAM2Long 是基于 SAM 2 的一种针对长时间视频对象分割任务的全新方法。通过引入多路径记忆树结构和不确定性处理机制,SAM2Long 有效地解决了长视频中遮挡、对象重现和错误累积等挑战。
实验结果表明,SAM2Long 在多个主流数据集上显著提升了分割精度,尤其是在未见类别和复杂场景中的表现尤为突出。相比于 SAM 2,SAM2Long 不仅保持了较低的计算开销,还在泛化能力和鲁棒性上实现了突破。
未来,我们相信 SAM2Long 可以广泛应用于各种实际场景,如自动驾驶、视频编辑和智能监控,推动视频对象分割技术的进一步发展。
文章来自于“机器之心”,作者“机器之心”。



