# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
腾讯在AI上信什么?
一个是开源,一个是MoE (混合专家模型)。
开源好理解,在大模型火热之后,加入战局的腾讯已经按照它自己的节奏开源了一系列模型,包括混元文生图模型等。
某种程度上,ChatGPT是一个意外的发布,意味着所有人在大模型上都“落后”了,开源是追赶的一种方式,也是快速建立存在感吸引更多社区参与者来共建的方式。
而腾讯对MoE的笃信,此前则并没太被外界意识到。事实上,这家从广告业务到推荐功能等,一直在生产环境里大规模使用着AI算法的公司,在技术上对MoE的笃信到了某种“信仰”的程度。
许多细节此前并不太为人所知。比如,在生成式AI大模型火热之前,腾讯的许多模型就在使用MoE架构,包括2021年腾讯训练的T5模型,整个模型参数已经很大,不过与今天的MoE相比,每个专家的参数量较小。而2024年11月5日,腾讯再次开源了最新的MoE模型Hunyuan-Large(混元Large),一个至今全行业公开发布出来的最大参数的MoE架构的模型。

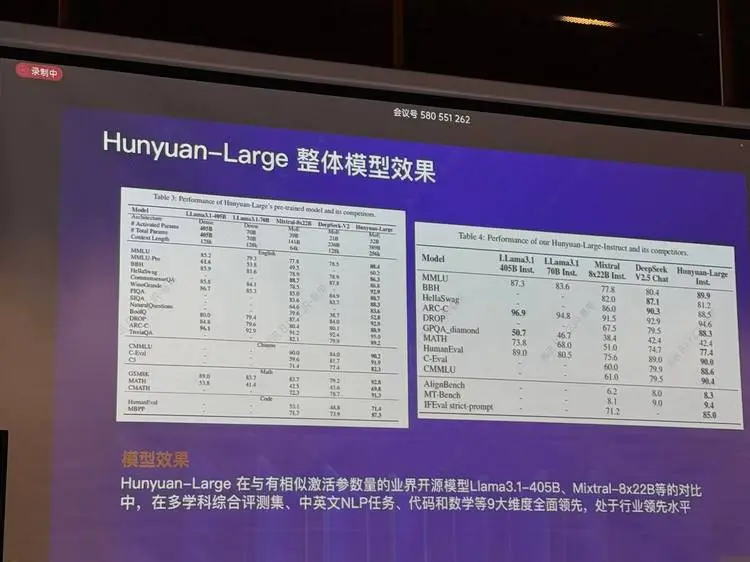
据腾讯介绍,腾讯混元Large模型总参数量 389B,激活参数量 52B ,上下文长度高达256K,公开测评结果显示,腾讯混元Large 在CMMLU、MMLU、CEval、MATH等多学科综合评测集以及中英文NLP任务、代码和数学等9个领域取得领先,超过Llama3.1、Mixtral等一流的开源大模型。同时,它已经在腾讯业务场景中落地应用,经过实践的检验,是面向实用场景的应用级大模型。
MoE是一种相对于稠密(dense)模型架构的设计。简单理解,稠密模型就是通过大力出奇迹训练出一个全知全能的神,来解决所有问题,它也是今天大模型火热背后,大家对大模型机制的朴素直觉的理解。而MoE放弃了造一个单独唯一的神,转而由多个各有所长分工明确的专家组来解决问题,也就是所谓的专家们的混合(Mixture of Experts)。
从这个简单的描述可以看出,MoE似乎更符合今天训练遇到规模化瓶颈时的技术选择。不过,在今天的开源模型领域,最强模型Llama 3在当时发布时最让业内惊讶的技术选择之一,就是没有使用MoE模型架构。这也让很多跟随llama体系的开源模型也继续坚持着稠密模型的路线。而现在腾讯显然不想跟着llama跑了。
在MoE架构的开源模型里,最吸引开源社区注意的是Mistral。这家公司成立于2023年5月,之后开始训练MoE架构的模型并提供给开源社区。据腾讯介绍,MoE架构的模型在2021年已经成为腾讯训练大模型的选择。
在大模型因ChatGPT火热之后,腾讯并没有第一时间公布它的技术路线和模型,而之后,在2024年3月发布财报的电话会上,腾讯高管第一次透露了混元已经是一个万亿级别参数的MOE架构模型,而在那个时间点前后,业内也开始广泛达成共识,认为OpenAI使用的也是MoE架构。
在混元Large的发布会上,腾讯机器学习平台总监,腾讯混元大语言模型算法负责人康战辉表示,如果scaling law的本质是追求模型更大的规模以实现更强的能力,那么MoE是必定会走向的路线。他形容腾讯这么多年已经在MoE路线上摸索了很久。与过往大家围绕稠密模型建立的scaling law不同,因为模型架构上的改变,MoE模型也有自己的Scaling Law。
“如果你只是想把模型撑的非常大,那么专家你可以8个,16个,32个甚至64个都可以。”康战辉说。“但如何找到最好的平衡配方,是需要很多的理解和积累的过程。我们从21年一路走来花了很多精力就是在理解这件事情。”
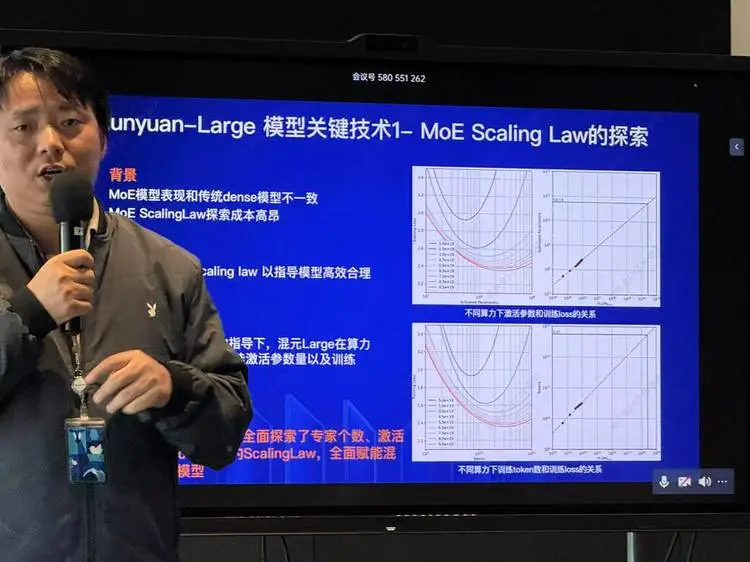
“MoE模型的变量更多,我们需要找到MoE自己的Scaling Law。”他说。
腾讯为此做了大量的实验,具体方法是,设置了一套自己的中小模型簇,做大量的各种模型组的实验,而不是几个模型的实验。“我们坚持用一种实验机制来保障它。”
而这次开源的过程,腾讯也把技术“秘方”做了总结。
它包括几个方面:
共享专家路由策略:混元Large有一个共享专家,也就是负责处理共享的通用能力和知识的专家模型,和16个特殊专家,负责处理任务相关的特殊能力,这些专家模型动态激活,利用稀疏的神经网络来高效率的进行推理。而训练这些不同的专家时,会遇到数据负载的挑战,在回收路由策略上,混元通过大量实验找到有效激活每个专家的方式,使其保持相对均衡的负载,根据Batch size 缩放原则,匹配不同的学习率,充分利用训练数据,保证模型的训练稳定性和收敛速度。
高质量合成数据:今天自然数据开始出现瓶颈,根据Gartner报告预测,到2030年,合成数据在AI模型中的使用将完全超过真实数据。但合成数据目前的问题是,它的质量参差不齐,缺乏多样性,部分能力/任务相关数据稀缺。腾讯的方法是在天然文本语料库的基础上,利用混元内部系列大语言模型构建大量的高质量、多样性、高难度合成数据,并通过模型驱动的自动化方法评价、筛选和持续维护数据质量,形成一条完整数据辣取、筛选、优化、质检和合成的自动化数据链路。目前,它在数学和代码领域获得了超过10%的提升。
长上下文处理能力:预训练模型支持高达256K的文本序列,Instruct模型支持128K的文本序列,显著提升了长上下文任务的处理能力。腾讯还为此做了一个更接近真实世界的评测集,名字叫做“企鹅卷轴”,也即将开源。
此外,在推理加速上,腾讯也使用了KV缓存压缩的技术:使用 Grouped-Query Attention (GQA)和 Cross-Layer Attention (CLA) 两种KV Cache 压缩策略,从head/layer两个维度联合压缩KV cache。同时再搭配上量化技术,提升压缩比。据腾讯数据,通过GQA+CLA的引入,最终将模型的KVCache压缩为MHA的5%,大幅提升推理性能。
同时,在预训练之外,后训练阶段,腾讯在对齐上也做了很多技术优化。
据腾讯介绍,今天SFT通用领域繁多,数学、代码高质量指令数据获取困难,业界广泛采用的离线DPO,强化策略效果上限不高,泛化性弱等挑战,腾讯混元Large模型分门别类提升数学、逻辑推理、代码等能力,另外在一阶段离线DPO的基础上引入了二阶段在线强化策略。
目前混元large已经在HuggingFace上线,也同步上架了腾讯云 TI平台。
Llama3 系列当初之所以没有采用MoE,在它的技术报告里给出的理由,主要指向了模型训练的稳定性。而这种稳定性不仅与模型训练的方法成熟度相关,也和整个训练生态对MoE架构的支持有关。比如,在Llama背后,支持它训练的Meta的计算集群里,像是基于RoCE的集群其实对MoE这类架构的运作方式有一定的适配问题,会带来控制上的问题从而导致效率的降低。
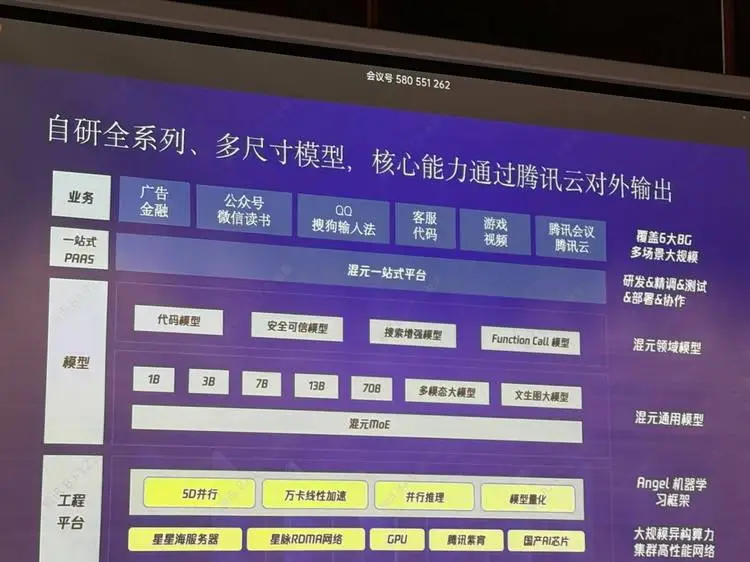
而据腾讯介绍,它自己的底层训练架构就是为支持MoE设计的。而且,这一次开源过程里,腾讯不只开源了模型,还把配套设施也提供了出来。
据腾讯介绍,本次开源提供了配套Hunyuan-Large模型的 vLLM-backend 推理框架。“我们在vLLM开源框架的基础上适配了Hunyuan-Large模型,新增的CLA结构可以很大程度节约显存(KV-Cache部分节省50%),保障超长文本场景。此外通过FP8的量化优化,相比FP16/BF16常规量化,在最大限度保障精度的条件下,节省50%显存,吞吐提升70%。”
此外,Hunyuan-Large也已经支持huggingface格式,支持用户采用hf-deepspeed框架进行模型精调。“我们也支持利用flash-attn进行训练加速,为此,我们把相关的训练脚本和模型实现也开放给到社区,方便研发者在此基础上进行后续的模型训练和精调的操作。”
在此次混元Large背后,它的训练和推理均基于腾讯Angel机器学习平台。为了使得混元大模型具备更好的训练和推理性能,腾讯也将陆续开源混元AnglePTM和AngeIHCF等大模型工程框架。
这是要通过全套的服务来壮大MoE的朋友圈。
其实,这次混元large的开源,最有意思的并不只是模型本身,而是对于一向低调的腾讯,难得展示了它在大模型这个技术发展上内部所确定的理念和方向。
首先在技术路线选择上,面对MoE尚未有充分的生态支持,Llama路线依然占据主流,并且追随它是“出成绩”更直接的选择时,它依然认定一直坚持的路线是对的。如果相信有一天大家都要走向MoE,那么更早的通过开源和生态建设来让开发者聚拢在它这里就是个正确的决定。
这让它看起来有点像坚持MoE版的Meta——实打实的把大量资源用在了最强的开源模型上。甚至它比Meta更笃信它所开源的技术方案——Meta的Llama在它的AI掌舵人Yann LeCun 眼里,看起来是个“过渡方案”,他领导的研究部门FAIR要追求的世界模型,甚至被形容为是和开源Llama完全不同的方向。而腾讯正在开源的,自己业务里使用的,以及长期投入的方案都是一套。
“我们内部说,我们不急于为了开源而开源,在内部业务打磨好后再开源。”康战辉说。同一天,腾讯还开源了混元3D生成大模型,这是业界首个同时支持文字、图像生成3D的开源大模型。
“要开就要有诚意,它必须是与我们自己用的模型同宗同源的。接下来我们还会继续基于MoE架构发布更多的模型。”
文章来自于微信公众号“硅星人Pro”,作者“王兆洋”



