
美团 LongCat-2.0:第一个在纯国产芯片训练的万亿参数大模型
美团 LongCat-2.0:第一个在纯国产芯片训练的万亿参数大模型如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?
来自主题: AI资讯
10057 点击 2026-06-30 21:04
 搜索
搜索
如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?

离谱了。 这两天,AI 圈都在疯传一个叫 Le Chaton Fat 的新模型。 30T MoE、256 个专家、100 万上下文窗口、多模态多语言,跑分全面碾压 Claude Fable 5、Claude Opus 4.8 和 GPT-5.5。

今天一早,谷歌又发新模型了!

今天,“港股AGI第一股”云知声发布其最新通用大语言模型U2,该模型是由云知声自研的、基于快慢思考融合的MoE(混合专家)范式构建的通用大语言模型。U2跳出了传统大模型盲目堆参数、堆Token的内卷路径,实现了“小参数强能力、少Token高产出、低算力低成本”的进化。

刚刚,谷歌DeepMind发布了Gemma 4 12B。一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。

继 Step 3.5 Flash 后,阶跃星辰最近又推出新一代高效率 Flash 开源模型 ——Step 3.7 Flash。该模型最大特点就是多(模)、快(速)、好(用)、省(钱)。总参数 196B,采用稀疏 MoE 架构,推理激活参数仅 11B,配备 1.88B ViT 视觉编码器,推理速度最高 400 TPS,支持 256K 上下文。

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。
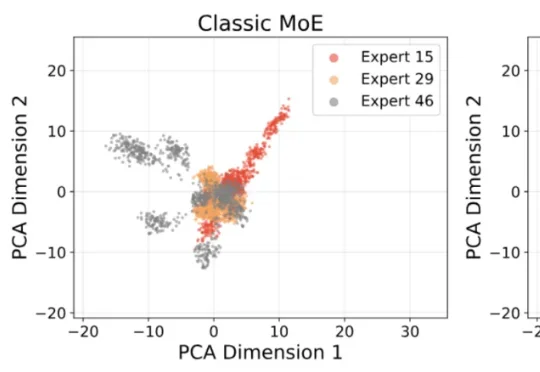
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。

刚刚,Cohere放出2180亿参数的MoE大模型Command A+,单张B200可跑,支持48种语言,还带原生引用能力。但这次发布最炸的,不在参数表上,而在那一个许可证:Apache 2.0。