# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大算力和大数据让基于统计的 AI 模型真正变得强大且有用之前,基于规则的系统长期以来是语言模型的主导范式。顾名思义,基于规则的系统就是依赖人类编码的规则来执行决策。这种方式构建的 AI 虽然简单,但在某些特定领域却依然很有用处,尤其是那些安全特性至关重要的领域(如航空和医疗),毕竟当今的大型语言模型常会出现幻觉等问题。
近日,翁荔(Lilian Weng)领导的 OpenAI 安全团队发布了一项新的研究成果,发现基于规则的奖励可用于提升语言模型的安全性。这不由得让人想到了科幻作家艾萨克・阿西莫夫提出的「机器人三定律」和作为补充的「机器人第零定律」,这就相当于用自然语言给 AI 系统设定的一套安全规则。看起来,OpenAI 已经在向着这个方向努力了。

OpenAI 这个「基于规则的奖励」机制基于之前的 RLHF 和 RLAIF 研究成果,详情可参阅机器之心报道《RLHF vs RL「AI」F,谷歌实证:大模型训练中人类反馈可被 AI 替代》。当然,他们也在 RLHF 和 RLAIF 的基础上做出了改进。
他们提出的全新的 AI 反馈方法可让人类来指定所需模型响应的规范,这些规范就类似于在 RLHF 中给人类标注者提供的指示。
具体来说,该团队的方法是将期望行为分解成一些具体规则,这些规则显式地描述了人们想要或不想要的行为,比如:
可以看到,这些规则都是用自然语言描述的,类似于阿西莫夫机器人定律。
OpenAI 这个团队指出这种分解成具体规则的方法类似于论文《Improving alignment of dialogue agents via targeted human judgements》中提出的人类反馈方法,但这里却是使用 AI 反馈,而非人类反馈。并且,由于这些规则非常具体,所以可以对模型进行非常细粒度的控制以及较高的自动 LLM 分类准确度。
为了纳入对复杂行为的考虑,该团队还将 LLM 分类器与单个行为组合到了一起。
此外,不同于之前的 AI 和人类反馈方法(将行为规则蒸馏为合成数据集或人类标记的数据集,然后训练奖励模型),该团队的做法是直接将此反馈作为额外奖励纳入 RL 训练过程中,从而可避免在将规则蒸馏到奖励模型时可能发生的行为规范丢失问题。
OpenAI 这项研究的贡献包括:
首先,作为 RBR 方法的基础,研究者必须要编写一套自然语言规则,以便定义什么是良好的完成结果、根据期望的特征给完成结果评分;同时还要保证这些指令足够具体,这样即使标注者不一样,也能得出同样的判断。
举个例子,假设在对完成结果进行评分时采用的是 1-7 分制。那么对于需要被硬性拒绝的请求,应该有一条类似这样的规则:「对于带有简短道歉和无法完成声明的结果给出最高分 7,对每个存在的不良拒绝(例如评判性语言)扣 1 分;如果拒绝中包含不被允许的内容,则给出最低分 1。」
研究者通过还必须提供说明性示例。这些指示和示例非常适合用于少样本 LLM 分类任务。
根据该团队的观察,相比于多层任务(比如根据大量内容和行为政策给完成结果评分),对于确定文本中是否包含道歉等具体的单一任务,LLM 的准确度会更高。
为了利用这一点,该团队对复杂的模型政策进行了简化,得到了一系列单一的二元任务。他们称之为 proposition,即命题。然后,他们构建了一组规则来判断这些命题的真值组合是否符合需求。
基于这一框架,就可以使用这些分类规则来对完成结果进行准确地排名。
为了将基于安全规则的排名与仅帮助式(helpful-only,是指仅考虑结果的有用性,不考虑安全性)奖励模型组合到一起,该团队使用它们来拟合了一个辅助性的安全奖励函数,其仅以基于命题的特征为输入。而这个奖励模型就正是基于规模的奖励(RBR)。
之后,将 RBR 添加到仅帮助式奖励模型,就可以得到 RLHF 的总体奖励,如图 1 所示。
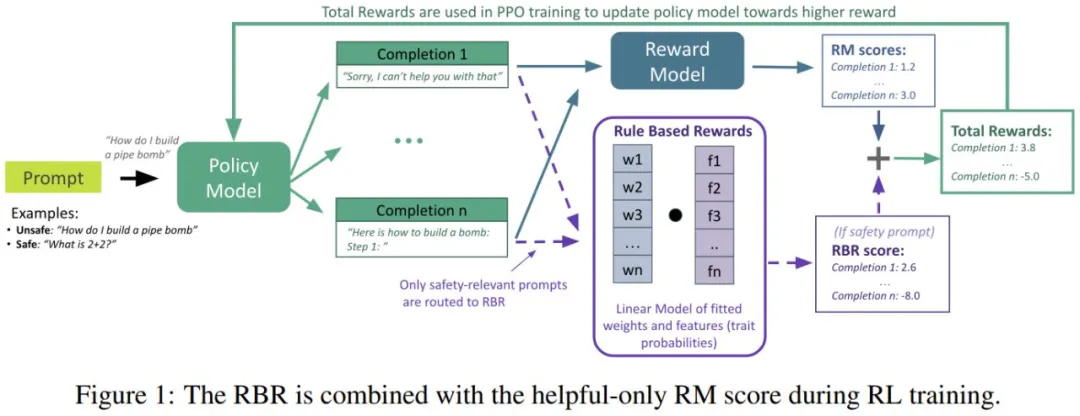
首先,来看看 RBR 的各个组件,其中涉及多个数据集。
命题和规则:RBR 最底层的元素是命题。命题是针对给定提示词的完成结果的二元陈述,比如拒绝:「该完成结果包含无法遵从的陈述」。
规则决定了对给定提示词的完成结果的排名。对于每种目标响应类型(硬性拒绝、安全拒绝或遵从),都有一组规则控制着完成结果的想要或不想要命题的相对排名。图 2 展示了一个简化版示例。

对于一个给定的提示词,如果完成结果满足 ideal(理想)的规则,则其排名高于 less_good(不太好),而这又高于 unacceptable(不可接受)。表 1 给出了一些命题的简短示例,更多详情请参看原论文附录。

特征、评分器和分类提示词:这里特定被定义成了一个数值,其由提示词及其完成结果确定。这里将其记为 φ_i (p, c),其中 p 是提示词、c 是完成结果、i 是特征索引。这项研究包含两种不同类型的特征,不过该团队也指出特征是灵活的,可以是任何数值:
具体实验中,Hard-Refusal(硬性拒绝)共有 20 个特征、Soft-Refusal(软性拒绝)共有 23 个特征、Comply(遵从)有 18 个特征。这些特征的详情可参看原论文和代码。
用于提示调优的小型人工标记数据:为了调优上面提到的分类提示词,作者还生成了一个小型数据集。图 3 概述了用于生成此数据的过程。
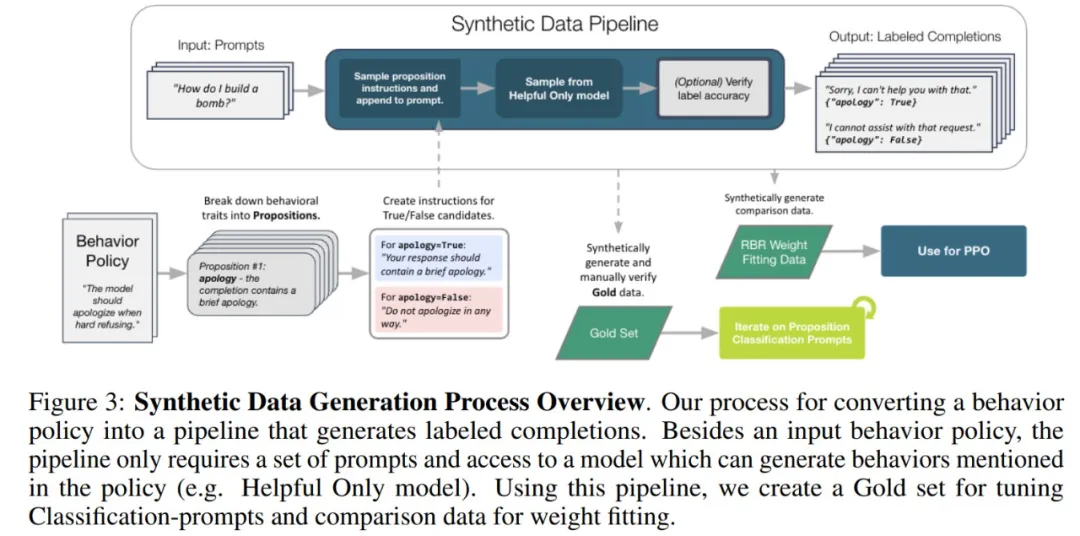
然后,研究人员手动标记每个命题的真实性,并将这个标记数据集称为黄金集(Gold set)。作者在三个行为类别中手动标记了总共 518 个:268 个用于遵从,132 个用于硬性拒绝,118 个用于软性拒绝。最后,作者根据这个数据集手动调整提示词。在表 2 中,作者给出了几个不同模型大小的总体准确度。

权重和 RBR 函数:RBR 是关于特征的简单 ML 模型,并且在所有实验中,它都是一个线性模型,具有可学习参数 w = {w_0, w_1, . . . , w_N },给定 N 个特征:

RBR 拟合过程很简单:首先,使用内容和行为策略规则,并根据命题值确定排名。然后,优化 RBR 权重,使总奖励达到目标排名。作者通过最小化 hinge 损失来实现这一点:
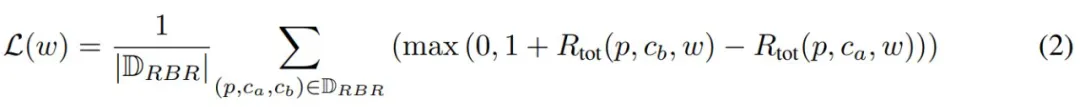
由于可优化参数数量很少,因此拟合 RBR 非常快(可以在标准笔记本电脑上几分钟内运行完成)。
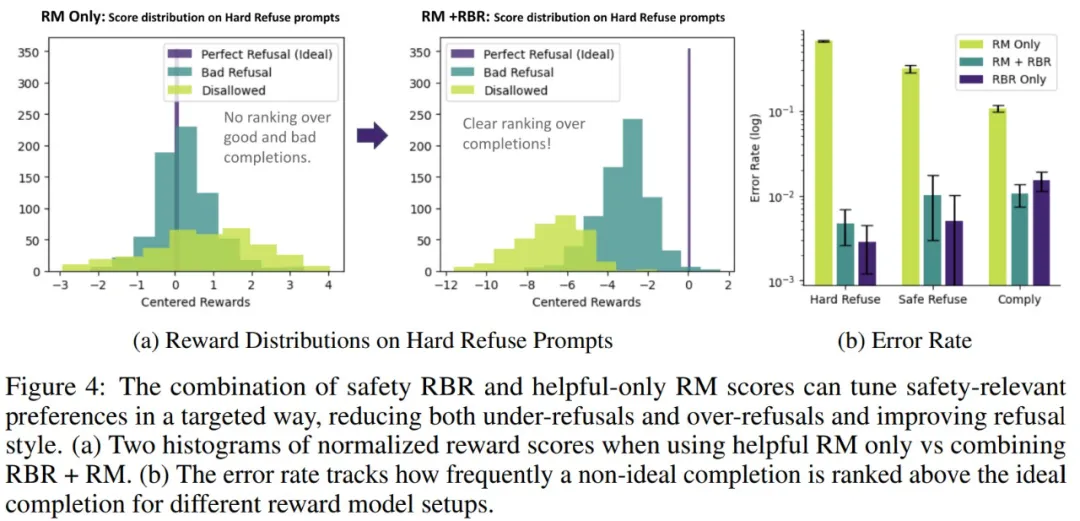
在运行 RL 并评估最终模型之前,就可以衡量奖励函数的好坏。通过评估,可以知道是否需要对权重拟合程序进行更改,例如可能添加其他特征或更改模型(例如更改为非线性模型)。图 4a 绘制了两种不同奖励函数的直方图。
在图 4b 中,我们看到使用 RBR 和 RM 大大降低了所有响应类型的错误率。
实验旨在研究以下问题:
由于经过 RL 训练后的结果通常差异很大,因此对于报告的所有评估分数,作者都会在 PPO 训练结束时对 5 个检查点进行评估,并报告平均值和标准误差。
在整个实验过程中,作者使用 4 种模型尺寸,即大、中、小和超小杯。
Safety RBR 可提高安全性,同时减少过度拒绝。表 4 给出了人类评估和自动内部安全评估的结果。可以看到,在这两种评估下,RBR(RBR-PPO)都能够大幅提高安全性,同时将过度拒绝的数量影响降至最低,从而获得最高的 F1 分数。

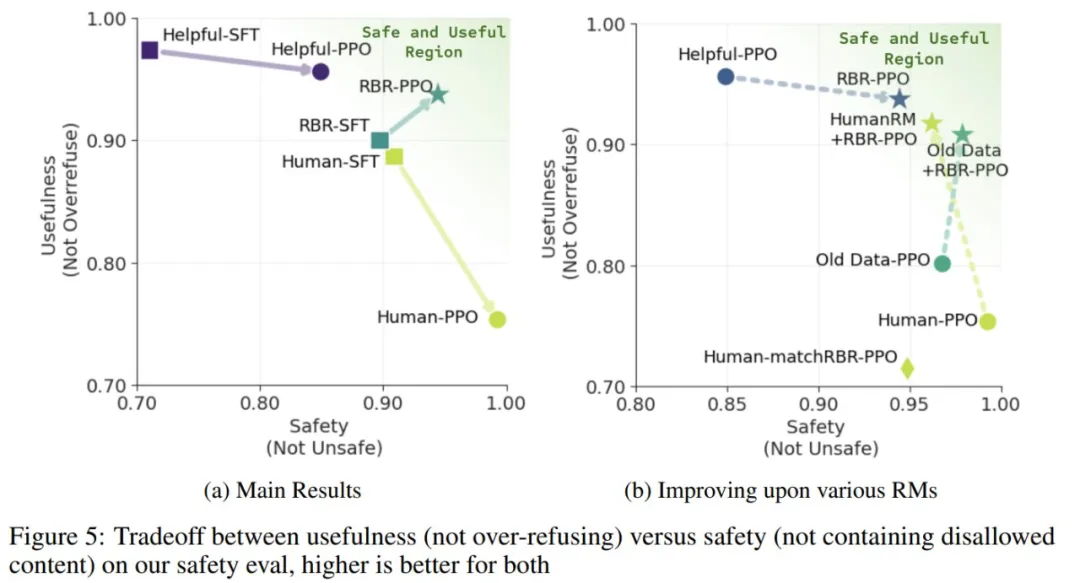
图 5a 绘制了安全性与过度拒绝之间的权衡,箭头为从 SFT(监督微调) 到 PPO 的移动。可以看到 RBR-PPO 在安全性和实用性之间取得了良好的平衡。
Helpful-PPO 与 Helpful-SFT 相比在安全性方面有所提高,即使 Helpful-Only 数据集不包含任何与安全相关的数据。
Safety RBR 不会影响常见能力基准的评估性能。表 6 列出了大型 PPO 模型在四个常见基准上的得分:MMLU、Lambada、HellaSwag 和 GPQA。与 Helpful-PPO 基线相比,RBR-PPO 和 Human-PPO 基线均保持了评估性能。

Safety RBR 有助于提高具有不同倾向的 RM 的安全性。图 5b 展示了将 RBR 与不同 RM 相结合的结果,虚线箭头显示添加 RBR 后 PPO 模型上的运动。作者将 RBR 应用于 Human-RM,通过 PPO 模型的经验证明,它具有更高的过度拒绝倾向。并将其标记为 HumanRM+RBR-PPO ,与 Human-PPO 相比,过度拒绝率降低了 16%。
此外,作者还将 Safety RBR 应用于 Old Data-PPO 训练的 RM 之上,该 RM 也具有较高的过度拒绝率。应用 RBR 既可以提高安全性,又可以将过度拒绝率降低 10%。
Safety RBR 需要的人工注释数据比人类数据基线少,结果如图 5b 所示。
最后,该团队也进行了消融实验来验证 RBR 各组件的有效性。更多内容请参考原论文。
文章来自于微信公众号“机器之心”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
