# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
性能优于规模更大的模型。
多模态学习面临的主要挑战之一是需要融合文本、音频、视频等异构的模态,多模态模型需要组合不同来源的信号。然而,这些模态具有不同的特征,很难通过单一模型来组合。例如,视频和文本具有不同的采样率。
最近,来自 Google DeepMind 的研究团队将多模态模型解耦成多个独立的、专门的自回归模型,根据各种模态的特征来处理输入。
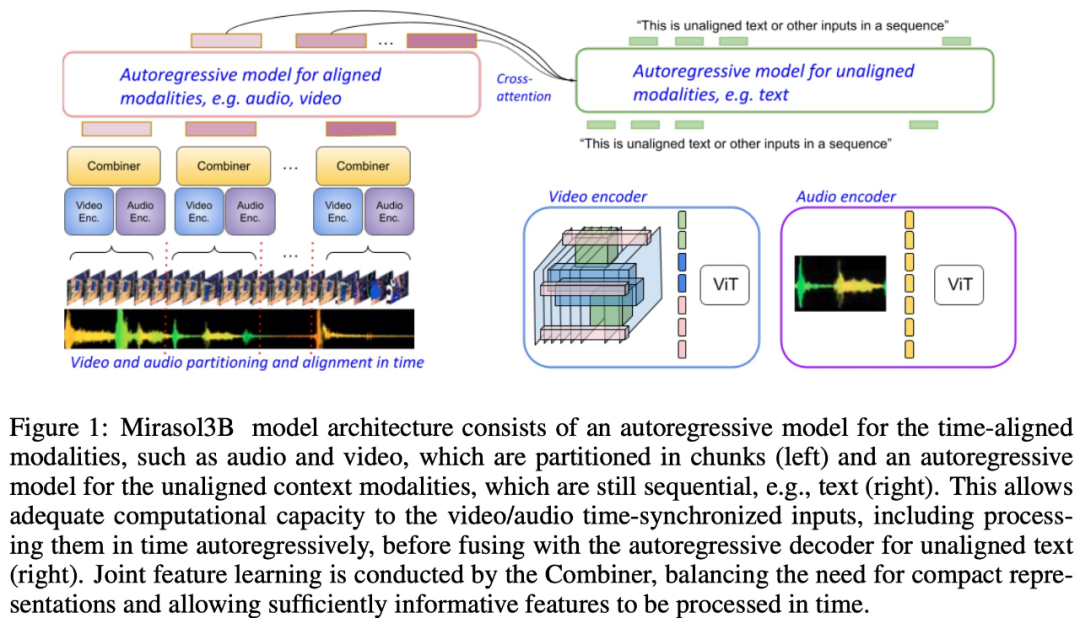
具体来说,该研究提出了多模态模型 Mirasol3B。Mirasol3B 由时间同步模态(音频和视频)自回归组件,以及用于上下文模态的自回归组件组成。这些模态不一定在时间上对齐,但是按顺序排列的。

论文地址:https://arxiv.org/abs/2311.05698
Mirasol3B 在多模态基准测试中达到了 SOTA 水平,优于规模更大的模型。通过学习更紧凑的表征,控制音频 - 视频特征表征的序列长度,并根据时间对应关系进行建模,Mirasol3B 能够有效满足多模态输入的高计算要求。
Mirasol3B 是一个音频 - 视频 - 文本多模态模型,其中将自回归建模解耦成时间对齐模态(例如音频、视频)的自回归组件,以及针对非时间对齐的上下文模态(例如文本)的自回归组件。Mirasol3B 使用交叉注意力权重来协调这些组件的学习进程。这种解耦使得模型内部的参数分布更合理,也为模态(视频和音频)分配了足够的容量,并使得整体模型更加轻量。
如下图 1 所示,Mirasol3B 主要由两个学习组件组成:自回归组件,旨在处理(几乎)同步的多模态输入,例如视频 + 音频,并及时组合输入。
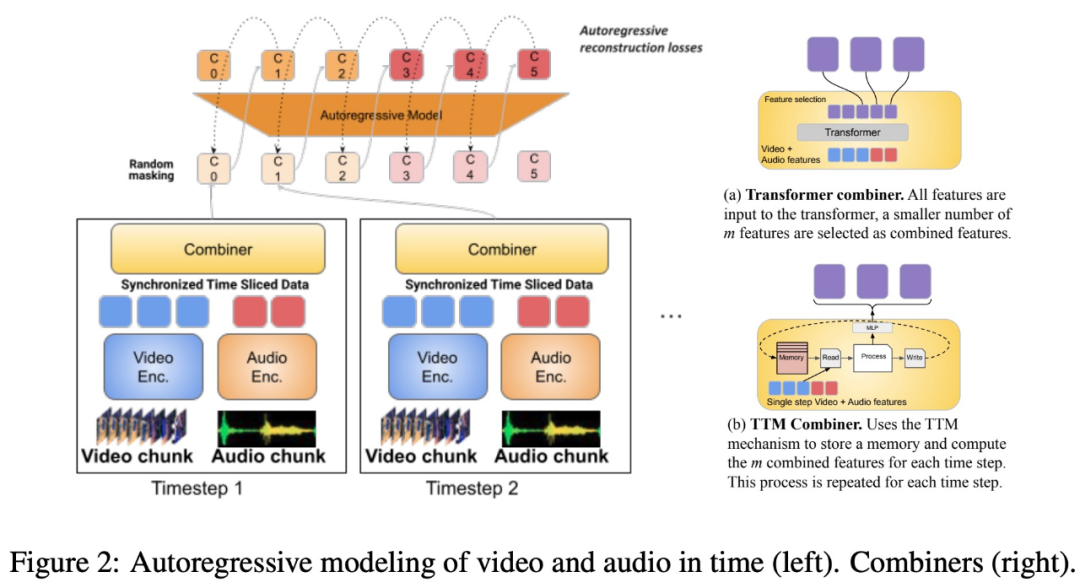
该研究还提出将时间对齐的模态分割成时间段,在时间段中学习音频 - 视频联合表征。具体来说,该研究提出了一种名为「Combiner」的模态联合特征学习机制。「Combiner」融合了同一时间段中的模态特征,产生了更紧凑的表征。
「Combiner」从原始的模态输入中提取初级的时空表示,捕捉视频的动态特性,并结合与其共时的音频特征,模型可以在不同的速率接收多模态输入,在处理较长的视频时表现良好。
「Combiner」有效地满足了模态表征既要高效又要信息量丰富的需求。它可以充分涵盖视频与其他同时发生的模态中的事件和活动,并能够用于后续的自回归模型,学习长期依赖关系。

为了处理视频和音频信号,并适应更长的视频 / 音频输入,它们被分割成(在时间上大致同步)的小块,再通过「Combiner」学习联合视听表示。第二个组件处理上下文,或时间上未对齐的信号,如全局文本信息,这些信息通常仍然是连续的。它也是自回归的,并使用组合的潜在空间作为交叉注意力输入。
视频 + 音频学习组件有 3B 参数;没有音频的组件是 2.9B。多半参数用于音频 + 视频自回归模型。Mirasol3B 通常处理 128 帧的视频,也可以处理更长(例如 512 帧)的视频。
由于设计了分区和「Combiner」的模型架构,增加更多帧,或增加块的大小、数目等,只会使参数略有增加,解决了更长视频需要更多参数、更大的内存的问题。
该研究在标准 VideoQA 基准、长视频 VideoQA 基准和音频 + 视频基准上对 Mirasol3B 进行了测试评估。
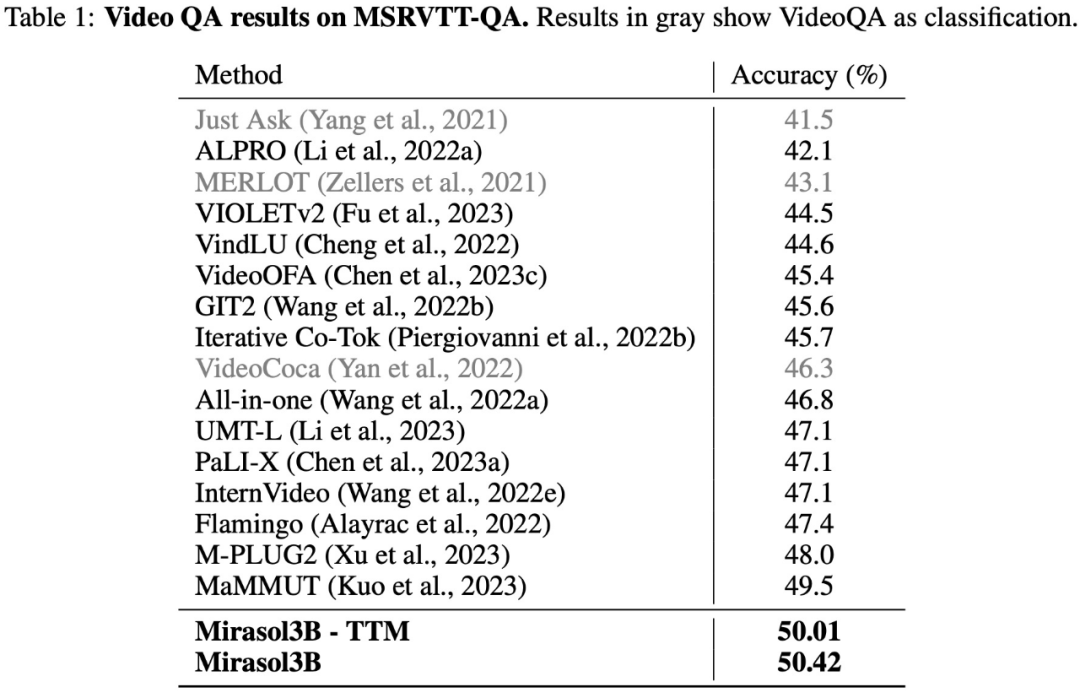
在 VideoQA 数据集 MSRVTTQA 上的测试结果如下表 1 所示,Mirasol3B 超越了目前的 SOTA 模型,以及规模更大的模型,如 PaLI-X、Flamingo。
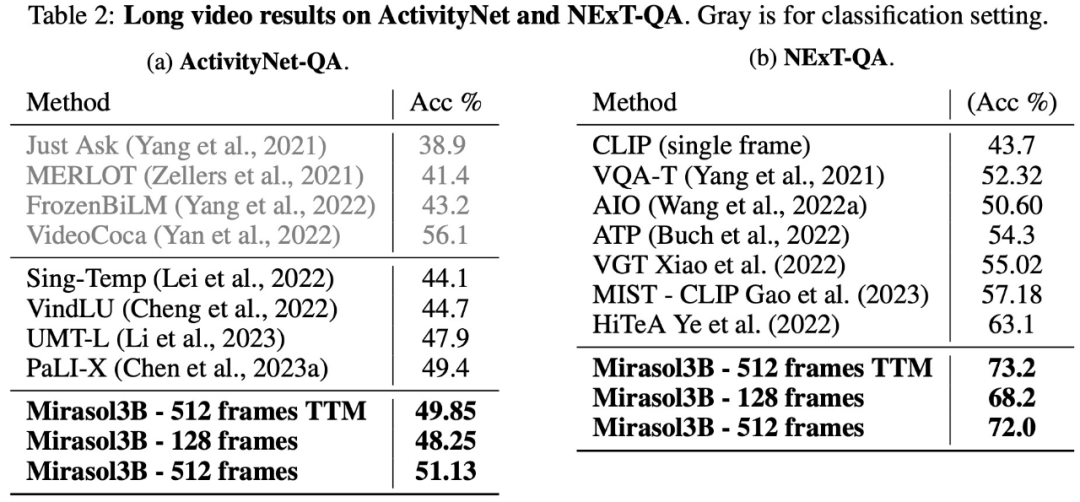
在长视频问答方面,该研究在 ActivityNet-QA、NExTQA 数据集上对 Mirasol3B 进行了测试评估,结果如下表 2 所示:
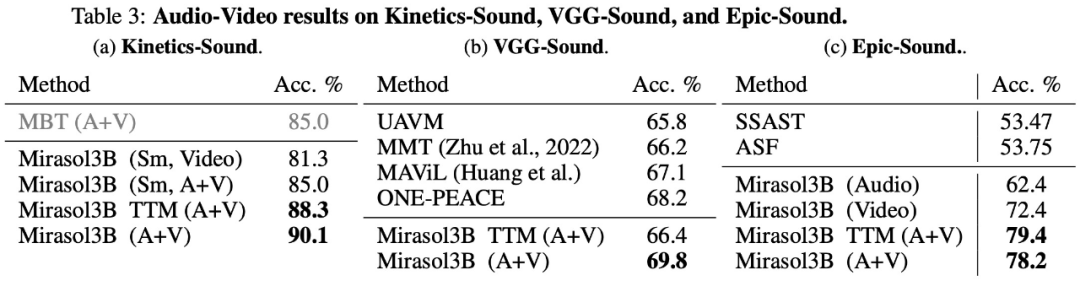
最后,该研究选择使用 KineticsSound、VGG-Sound、Epic-Sound 进行音频 - 视频基准测试,采用开放式生成评估,实验结果如下表 3 所示:
感兴趣的读者可以阅读论文原文,了解更多研究内容。
文章来自于微信公众号 “机器之心”,作者 “机器之心编辑部”



