# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
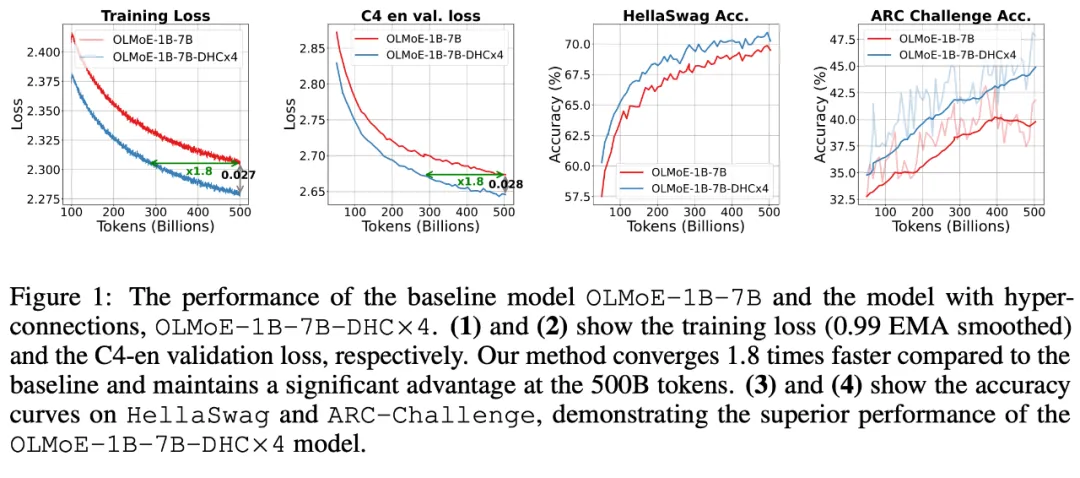
字节跳动豆包大模型团队于近日提出超连接(Hyper-Connections),一种简单有效的残差连接替代方案。面向残差连接的主要变体的局限问题,超连接可通过动态调整不同层之间的连接权重,解决梯度消失和表示崩溃(Representation Collapse)之间的权衡困境。在 Dense 模型和 MoE 模型预训练中,超连接方案展示出显著的性能提升效果,使收敛速度最高可加速 80%。
自从 ResNet 提出后,残差连接已成为深度学习模型的基础组成部分。其主要作用是 —— 缓解梯度消失问题,使得网络的训练更加稳定。
但是,现有残差连接变体在梯度消失和表示崩溃之间存在一种 “跷跷板式” 的权衡,无法同时解决。
为此,字节豆包大模型 Foundation 团队于近日提出超连接(Hyper-Connections),针对上述 “跷跷板式” 困境,实现了显著提升。
该方法适用于大规模语言模型(LLMs)的预训练,在面向 Dense 模型和 MoE 模型的实验中,展示了显著性能提升效果,使预训练收敛速度最高可加速 80%。
研究团队还发现,超连接在两个小型的视觉任务中表现同样优异,这表明,该方法在多个领域有广泛的应用前景。

前文提及,残差连接的两种主要变体 Pre-Norm 和 Post-Norm 各自都有其局限性,具体体现如下:
超连接的核心思路在于 —— 引入可学习的深度连接(Depth-connections)和宽度连接(Width-connections)。
从理论上,这使得模型不仅能够动态调整不同层之间的连接强度,甚至能重新排列网络层次结构,弥补了残差连接在梯度消失和表示崩溃(Representation Collapse)之间的权衡困境。
深度连接与宽度连接
起初,该方法会将网络输入扩展为 n 个隐向量(n 称作 Expansion rate)。之后每一层的输入都会是 n 个隐向量,超连接会对这些隐向量建立以下两类连接:
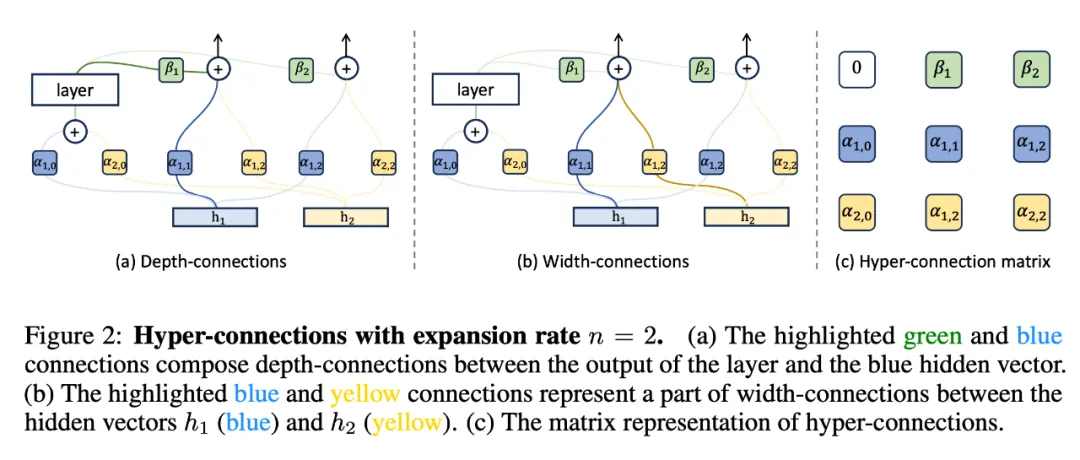
静态与动态超连接
超连接可以是静态的,也可以是动态的。
其中,静态超连接(Static Hyper-Connections, SHC)意味着连接权重在训练结束后固定不变。而动态超连接(Dynamic Hyper-Connections, DHC)则对应连接权重可根据输入动态调整。实验表明,动态超连接效果更好。
超连接(Hyper-connections)


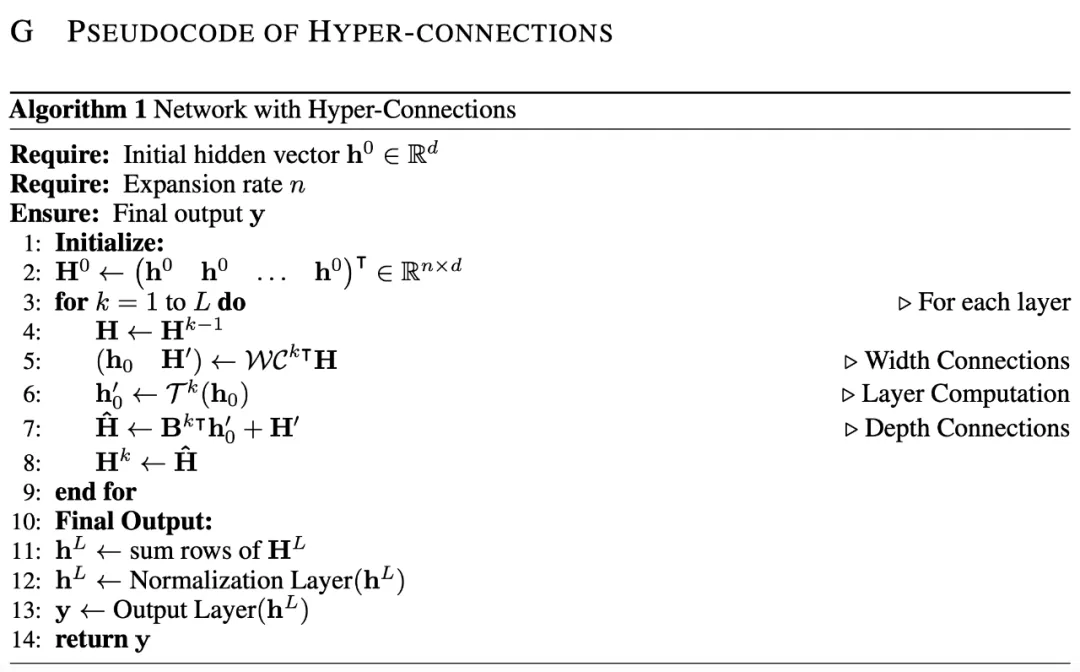
动态超连接的实现


顺序 - 并行二象性
给定一系列神经网络模块,我们可以将它们顺序排列或并行排列。作者认为,超连接可以学习如何将这些层重新排列,形成顺序和并行配置的混合。
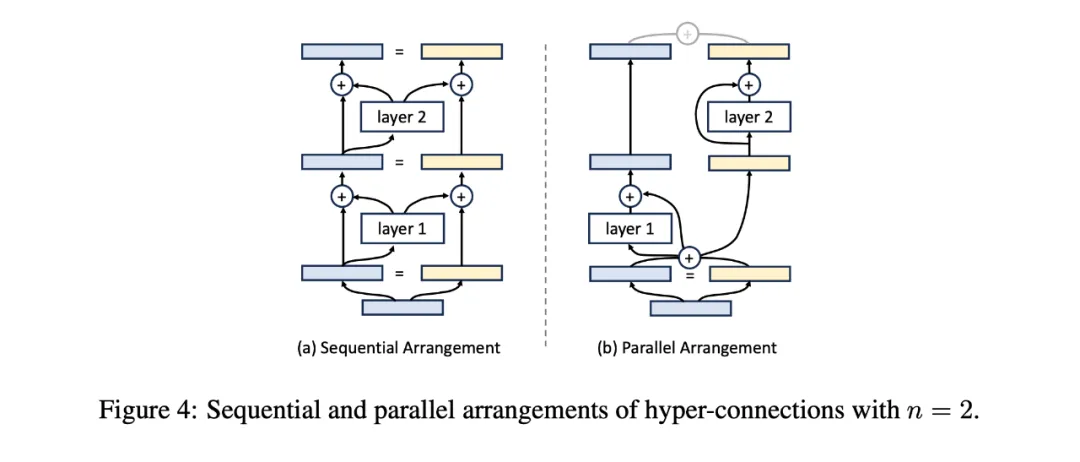
在不失一般性的情况下,可以将扩展率设置为 n=2。如果超连接以如下矩阵形式学习,神经网络将被顺序排列:
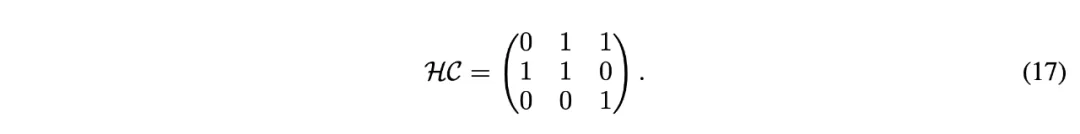
在这种情况下,深度连接退化为残差连接,如图 (a) 所示。
当奇数层和偶数层的超连接矩阵分别定义为以下形式时,神经网络每两层将被并行排列,类似于 Transformer 中的 parallel transformer block 的排列方式,如图 (b) 所示。

因此,通过学习不同形式的超连接矩阵,网络层的排列可以超越传统的顺序和并行配置,形成软混合甚至动态排列。对于静态超连接,网络中的层排列在训练后保持固定;而对于动态超连接,排列可以根据每个输入动态调整。
实验主要集中在大规模语言模型的预训练上,涵盖了 Dense 模型和 MoE 模型。
实验结果表明,使用超连接的模型显著优于使用残差连接的模型。
1B Dense 模型实验
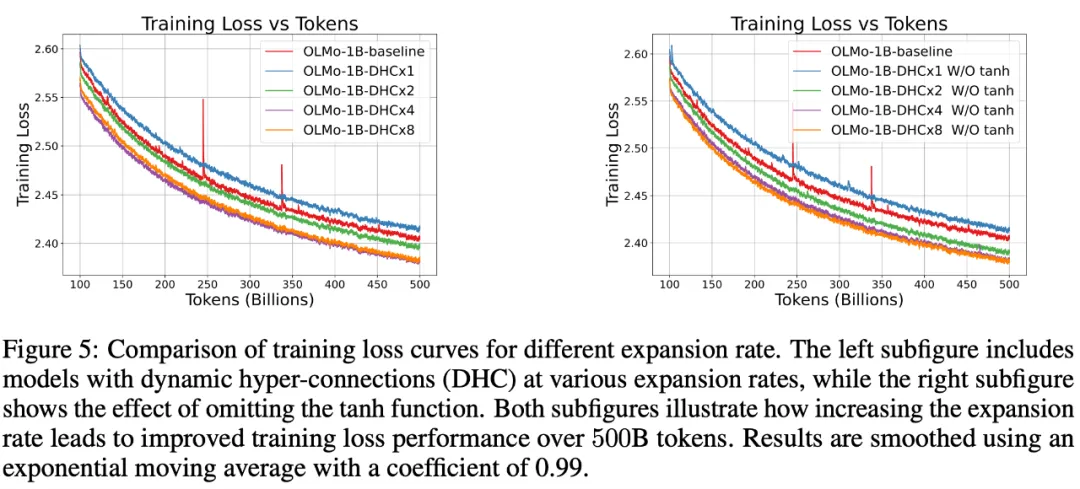
只要扩展率 > 1,效果就十分显著,且训练更稳定,消掉了训练 loss 的 spikes。
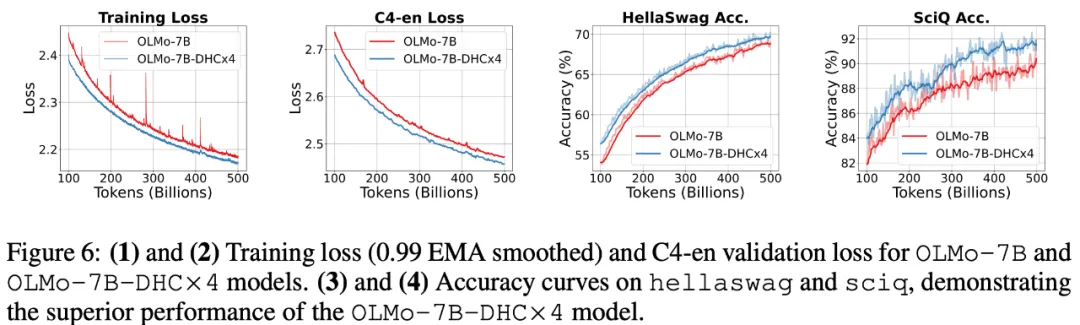
7B Dense 模型实验
团队甚至 Scale 到了 7B 模型,效果也十分亮眼,同时可以看到有超连接的网络训练更稳定。
7B 候选激活 1.3B 的 MoE 模型实验
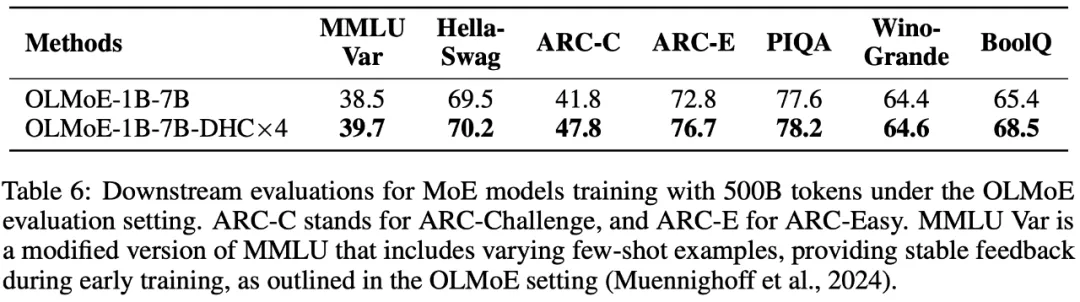
可以看到,下游指标全涨,在 ARC-Challenge 上甚至涨了 6 个百分点。
综上,研究团队介绍了超连接(Hyper-Connections),它解决了残差连接在梯度消失和表示崩溃之间的权衡问题。实验结果表明,超连接在大规模语言模型的预训练以及视觉任务中都表现出显著的性能提升。
值得注意的是,超连接的引入几乎不增加额外的计算开销或参数量,团队认为,该成果具有广泛的应用潜力,可以推广到文音视图模态的不同任务上,包括多模态理解、生成基座模型等。
团队关注底层问题,尤其在 LLMs 和多模态方面,期望实现更多突破。
更多团队技术研究进展,可以进入「豆包大模型团队」技术解读栏目了解。
文章来自于微信公众号“机器之心”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
