# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。
注意力机制会计算一定跨度内输入文本(令牌,Token)之间的交互,从而实现对上下文的理解。随着应用的发展,高效处理更长输入的需求也随之增长 [1][2],这带来了计算代价的挑战:注意力高昂的计算成本和不断增长的键值缓存(KV-Cache)代价。稀疏注意力机制可以有效缓解内存和吞吐量的挑战。
然而,现有稀疏注意力通常采用统一的稀疏注意力模式,即对不同的注意力头和输入长度应用相同的稀疏模式。这种统一的方法难以捕捉到大语言模型中多样的注意力模式,导致不同注意力头的不同的精度 - 代价权衡被忽略。
最近,来自清华大学、无问芯穹和上海交通大学的研究团队发表了《MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression》,提出通过混合不同稀疏度的注意力头,使用 25% 的注意力稠密度,就可以记忆几乎 100% 的上下文。
本工作现已开源,欢迎交流讨论。

在大语言模型中,不同的注意力头表现出各异的注意力模式和扩展规则:有的关注全局信息,有的则聚焦局部;有的注意力范围随输入长度增加而扩展,有的则保持不变。然而,现有的统一稀疏注意力机制破坏了这些固有的特性。
为应对这一挑战,研究团队提出了混合稀疏注意力(Mixture of Sparse Attention, MoA)方法,它能够为不同的头和层定制独特的稀疏注意力配置。MoA 构建了一个包含多种注意力模式及其扩展规则的搜索空间。通过分析模型,评估潜在配置,MoA 可以为每个注意力头找到最优的稀疏注意力模式和扩展规则。
实验结果显示,无需任何训练,MoA 就可以在保持平均注意力跨度不变的情况下,将有效上下文长度提升约 3.9 倍。模型效果上,在 Vicuna-7B、Vicuna-13B 和 Llama3-8B 模型上,MoA 将长文本信息检索准确率提高了 1.5-7.1 倍,优于统一注意力基线方法 StreamingLLM。
此外,MoA 缩小了稀疏与稠密模型之间的能力差距,在 50% 平均注意力跨度下,长上下文理解基准测试集的最大相对性能下降从基线方法的 9%-36% 降低至 5% 以内。
在运行效率上,MoA 的稀疏注意力使得生成过程中 KV-Cache 长度不扩大便于内存管理,减少了注意力计算量,降低了存储量从而可增大批大小。结合 CUDA GPU 算子优化,MoA 相比于 FlashAttention2 和 vLLM 将 7B 和 13B 稠密模型的生成吞吐量分别可提升 6.6-8.2 以及 1.7-1.9 倍。方法在 12K 以内的输入长度上搜索压缩方案,压缩后模型可以在长达 256K 的输入长度上高效且精准地检索信息。
多头自注意力(MHA)机制是大型语言模型的核心功能之一 [3]。该机制从输入序列出发,通过线性变换将其转换成查询(Q)、键(K)和值(V)三个矩阵。这些矩阵与之前序列的键值缓存(KV-Cache)相结合,共同计算出注意力矩阵(A)。为了保持自回归特性,这一计算过程会通过因果掩膜(M)进行调整,最终得到输出(O)。具体公式如下:
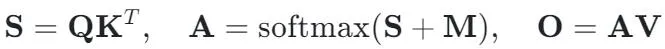
在大语言模型的自回归推理过程中,分为两个阶段:预填充和解码。在预填充阶段,模型会处理整个输入序列,以生成初始的响应令牌。随后进入解码阶段,模型利用新产生的令牌以及之前缓存的 K 和 V 矩阵,逐步生成后续令牌,直至完成整个序列的生成。虽然这种迭代方法效果显著,但随着 KV-Cache 的不断扩展,它也带来了内存和计算资源的需求增加。
现有方法
之前的研究通过引入稀疏注意力方法来应对大型语言模型处理长上下文时的效率挑战。对于生成式的大型语言模型,主流的稀疏模式是采用统一跨度滑窗:即不论注意力头还是输入长度如何,都使用固定、均匀跨度的滑动窗口掩膜,这样每个文本仅关注其邻近的上下文区域。
此外,还会对最初的几个文本施加全局注意力,以便它们能够关注到所有其他文本。这种局部注意模式通过丢弃当前注意跨度之外的 KV-Cache,显著降低了长序列场景下的内存需求 [4][5]。原则上,尽管单个模型层的注意力是局部的,但通过多层模型的逐步传递,每个词最终都能获取全局信息,从而在理论上可以实现比平均注意力跨度更长的有效上下文长度 [6]。
然而,这种统一跨度的滑动窗口方法并未考虑到模型本身的特性,导致大型模型在处理长文本时的有效上下文长度受到限制,进而影响了其在长文本场景下的表现。
根据之前的研究定义,本工作将有效上下文长度定义为在内容检索任务上能够达到 90% 以上精度的最大输入长度 [1][2]。研究表明,像 StreamingLLM [4] 这样的统一跨度滑窗方法,其有效上下文长度往往难以超出平均注意力跨度。如下图所示,当使用输入长度 50% 的跨度进行稀疏注意力时,统一跨度滑窗无法有效地从窗口外的内容中检索信息,而且这一问题随着输入长度的增加而愈发严重。
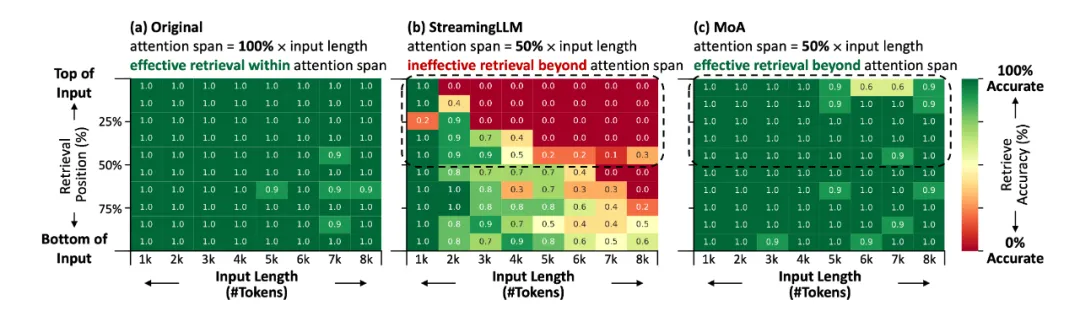
在LongEval数据集上[7],使用不同注意力方法的Vicuna-7B模型在不同输入长度和检索位置的检索精度。大海捞针实验[8]将大量的键值对作为输入,并在不同位置测试给键检索值时的精度。(a) 原始稠密注意力模型;(b)统一跨度滑窗StreamingLLM,注意力跨度减半,超出跨度时检索效果降低;(c) MoA,平均注意力跨度减半,超出跨度时检索效果依然优秀。
下图揭示了这个现象的一个可能解释:虽然部分注意力头专注于局部上下文,但另一些注意力头则关注了整个输入序列。因此,采用统一跨度的方法限制了那些关注全局上下文的头的注意力跨度,并且给关注局部上下文的头分配了过多的计算和内存资源。
此外,随着输入长度的增加,某些注意力头需要比其他头更快地扩展其注意力跨度,以防止性能显著下降。遗憾的是,统一跨度的方法没有考虑到这种异质性,未能针对不同注意力头的需求分别调整其注意力范围。另外,现有的模型压缩技术在制定压缩策略时通常基于通用语料库和人工撰写的输出结果,这并不能精确地反映稀疏化对处理长上下文任务的具体影响。
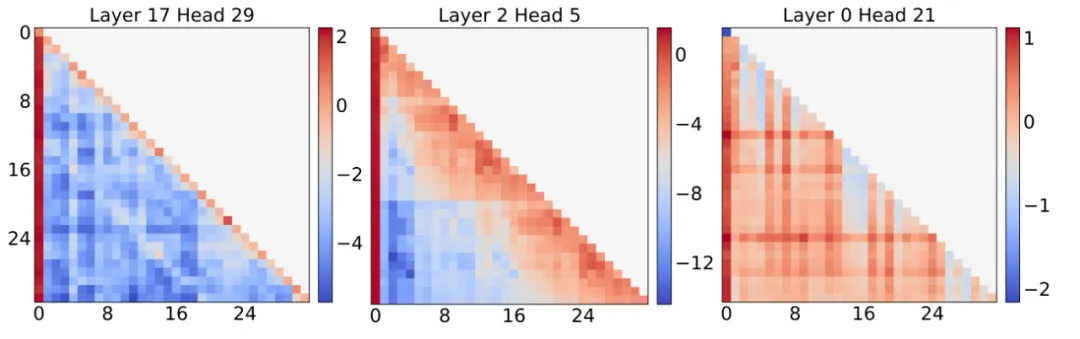
来自Vicuna-7B模型不同注意力头的注意力矩阵示例。每个注意力矩阵是从LongEval数据集的256个输入上取平均得到的。
本文方法
本文提出了一种名为混合注意力(MoA)的方法,它是一种无需训练或微调的异质稀疏注意力机制。如下图所示,MoA 建立了一套异质弹性规则,作为注意力跨度的搜索空间。对于每个注意力头,MoA 将自动分析不同注意力跨度的效果,并最优化不同注意力头的跨度。同时,MoA 精心设计了校准数据集,以确保它能精确地反映出稀疏注意力对处理长上下文任务的具体影响。
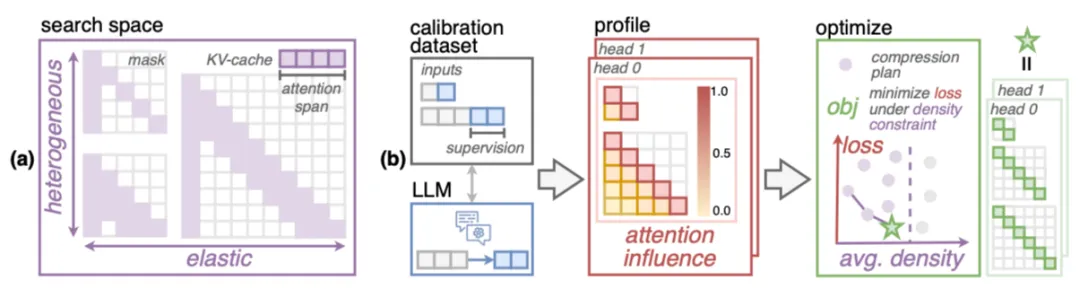
MoA的概览:(a) 稀疏注意力的搜索空间涵盖了滑窗跨度的异构弹性规则;(b) 自动压缩过程始于精心设计的校准数据集。MoA通过分析这个数据集中每个注意力值对模型预测的影响,揭示了不同候选弹性规则在不同输入长度下的准确性损失。在优化阶段,MoA为每个注意力头挑选出最合适的弹性规则,使得其在满足平均跨度约束的同时,尽可能减少模型的性能损失。
异质弹性规则的搜索空间

自动注意力跨度规则搜索

分析
给定大语言模型,MoA 首先会在校准数据集的一系列文本上进行分析,以评估移除每个注意力值对模型最终预测结果的具体影响。具体而言,本工作采用了一阶泰勒展开的方法进行影响评估:
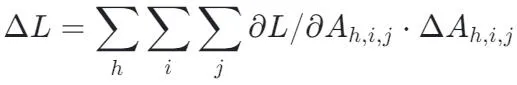
通过分析每个注意力值对预测结果的贡献,我们可以计算出在当前输入下,不同跨度滑窗对最终预测结果的影响,也就是该窗口所移除的所有注意力值影响的总和。
在实际操作中,本工作推导了注意力影响的形式化表达,并利用深度学习框架的反向传播机制高效地计算所需的偏导数值。在校准数据集的不同输入长度上,MoA 对滑动窗口的影响分别取平均值,以体现同一种异质弹性规则在不同长度输入下的影响。
在分析阶段完成后,MoA 能够明确每种异质弹性规则在精度和效率之间的平衡。基于此,MoA 可以将较长的注意力跨度分配给那些对压缩更为敏感的注意力头,而将较短的注意力跨度分配给那些对此不太敏感的注意力头。
优化
根据分析结果,MoA 会为每个注意力头挑选出最佳弹性规则。在优化过程中,用户可以设定不同输入长度下的注意力密度(即平均注意力跨度与输入长度的比值)作为限制条件,而 MoA 则会在满足这一条件的同时,力求最小化各长度下的预测误差。
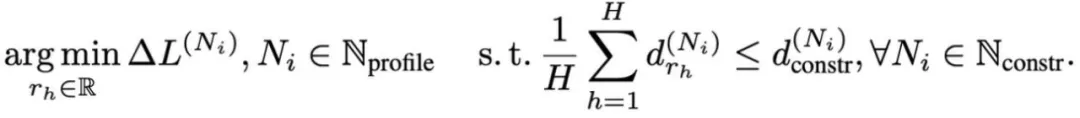
具体而言,MoA 构建了一个多目标优化问题:最小化不同输入长度下的预测损失,同时确保平均注意力密度不超过用户设定的限制。MoA 采用混合整数优化方法求解这一多目标优化问题。求解得到的所有压缩方案均达到了帕累托最优,意味着在没有增加其他长度预测损失的前提下,无法进一步降低任何特定长度的预测损失。
为了确保模型能够有效泛化至未曾见过的输入长度,MoA 会从所有帕累托最优压缩方案中,选择在未见过的验证长度上损失最小的方案作为最终采用的压缩策略。
通过自动注意力跨度规则搜索,MoA 在遵守用户定义的密度约束的同时,找到合适的异质弹性规则来最小化由注意力稀疏化引起的准确性损失。
校准数据集的设计与选择
同时,MoA 也强调了数据工程在大语言模型压缩中的重要性。本工作发现,使用具有长距离依赖性的数据集并参考原始大语言模型的响应对于准确分析压缩的影响至关重要。
本工作指出了常用的通用语言建模数据集的主要问题。这类数据集,例如人类编写的文本语料库,通过在整个语料库上进行下一个词预测作为监督信号。但是这主要捕获的是临近上下文之间的注意力模式,而忽略了长期上下文依赖性,无法解决像长距离检索这样的全局注意力任务。
同时,模型响应和人类编写的监督之间存在显著的不对齐。例如,对于同一个问题,人类可能会回答 'Blue',而模型可能会回答 'The blue color'。使用人类的答案进行监督,注意力影响是基于预测 'Blue' 的概率转移量化的,这与最终目标背道而驰,即难以保持原始模型预测 'The' 的关键注意力。
因此,本工作构建长距离依赖并通过与原始模型对齐来增强校准数据集。通过下表可以发现,这种数据集构建方式可以准确反映注意力影响,显著提高压缩后的模型的性能。

精度
MoA 实验在多种模型(Vicuna-{7B, 13B) 和 Llama-3-{8B, 70B})和多种基准测试(长上下文检索,长上下文理解)上和之前的静态和动态稀疏注意力方法(StreamingLLM [4],H2O [9] 和 InfLLM [12])进行了比较。
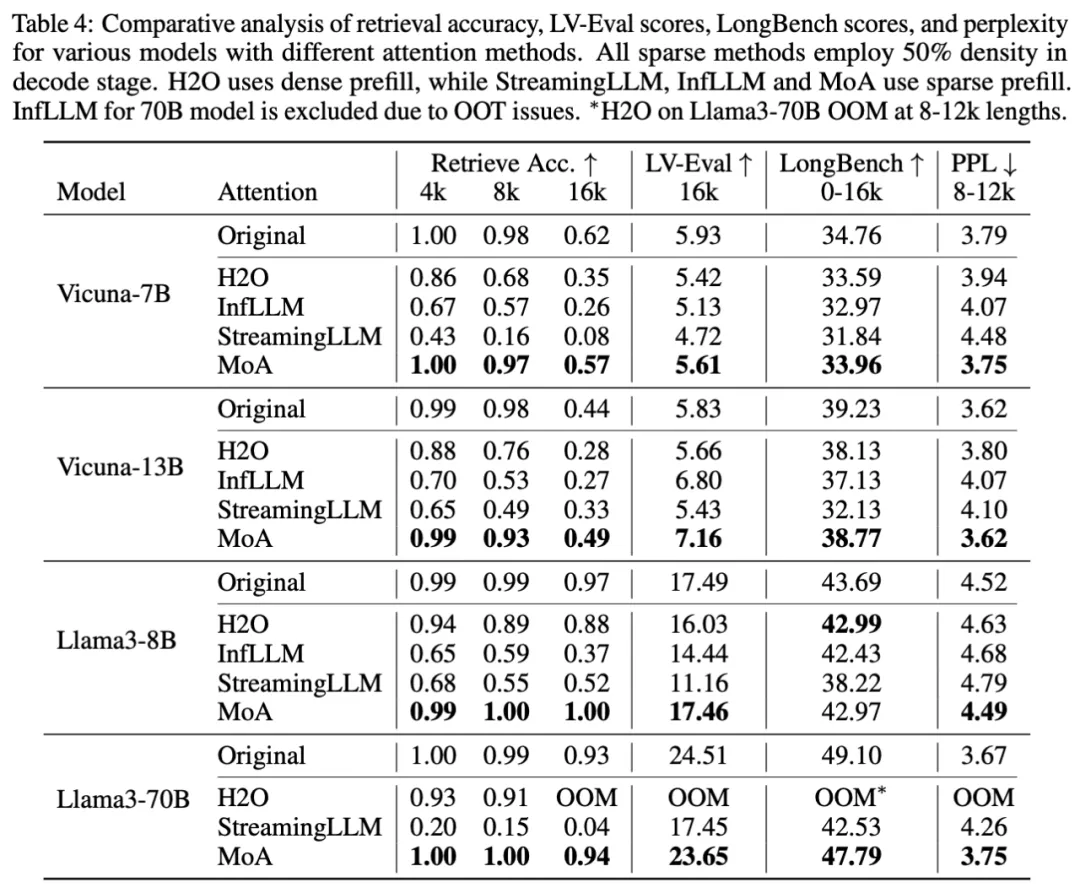
MoA 超越基线稀疏注意力方法,并在 50% 的平均注意力密度下达到了与原始稠密模型相当的性能。我们计算了稀疏模型相对于原始模型的性能下降。
对于长上下文检索检索任务,MoA 最大相对准确性下降为 8%,远小于 StreamingLLM、InfLLM 和 H2O 的 87%、58% 和 44%。平均来说,MoA 的相对准确性下降在 1% 以下,而 StreamingLLM、InfLLM 和 H2O 的 51%、41% 和 20%。
如下图 (a) 所示,MoA 将其有效上下文长度扩展到注意力跨度的大约 3.9 倍。图 (b) 显示,在固定的 8k 输入长度下,MoA 只需要 25% 注意力就可以达到 90% 以上的检索准确性。图 (c) 显示 MoA 在 12k 长度内压缩后,可以保持和原稠密模型一致的有效上下文长度。
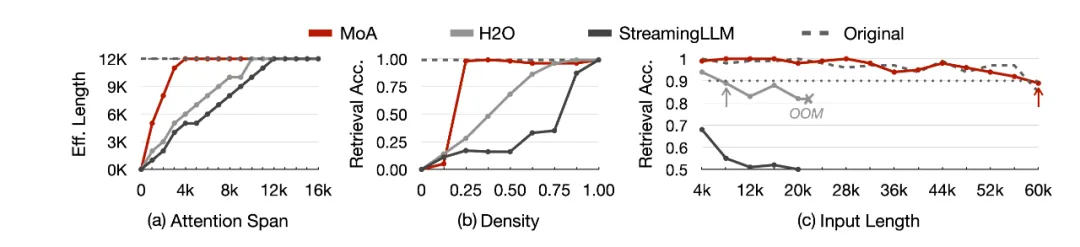
在LongEval上进行上下文检索准确性测试。使用Vicuna-7B模型:(a)改变注意力跨度,比较有效上下文长度,(b)将输入长度设定为8k,比较不同注意力密度下的检索准确性。使用Llama3-8B模型:(c)将密度设定为50%,比较输入长度增加时的检索准确性。
对于长上下文理解任务,在使用 LV-Eval 和 LongBench 的基准测试中,MoA 只显示了最大 5% 和 3% 的相对分数下降,而 StreamingLLM 则分别最大下降了 36% 和 27%;InfLLM 最大下降了 17% 和 5%;H2O 最大下降了 9% 和 4%

不同注意力方法在 50% 密度下进行 (a) LV-Eval和(b) LongBench 长上下文理解基准测试。测试使用 Vicuna-7B和13B模型,以及 Llama3-70B 模型。分数相对于原始稠密模型进行归一化。
长上下文泛化。通过在 12k 长度内进行压缩,MoA 能够有效泛化到 32k-256k 的长度。如下表所示,在范化的长度上,MoA 的检索精度比 InfLLM 和 StreamingLLM 高 1.9-3.3 倍,LV-Eval 评分高 1.2-1.4 倍,展现出与原始稠密模型相当的性能。如下表所示,
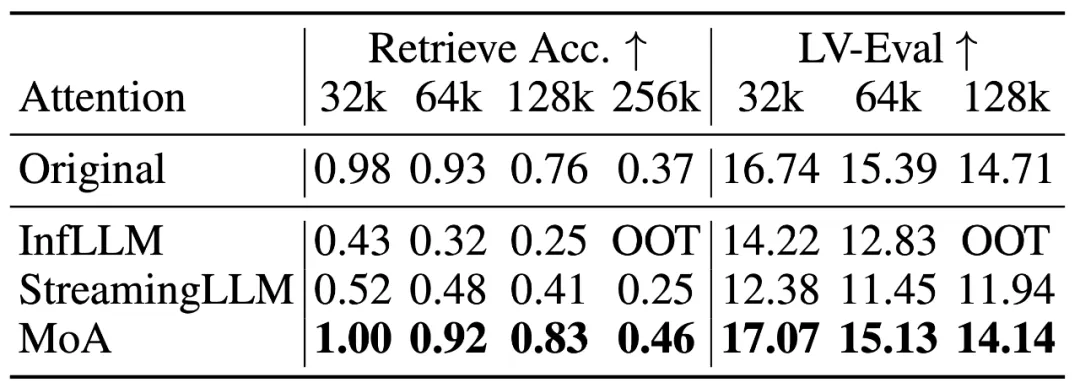
消融实验进一步评估了不同程度的稀疏注意力混合对于最终性能的影响。从基本的统一跨度滑窗开始,通过依次引入不同程度的异质性(层间,注意力头间,输入长度间),最终模型性能在不断提升。
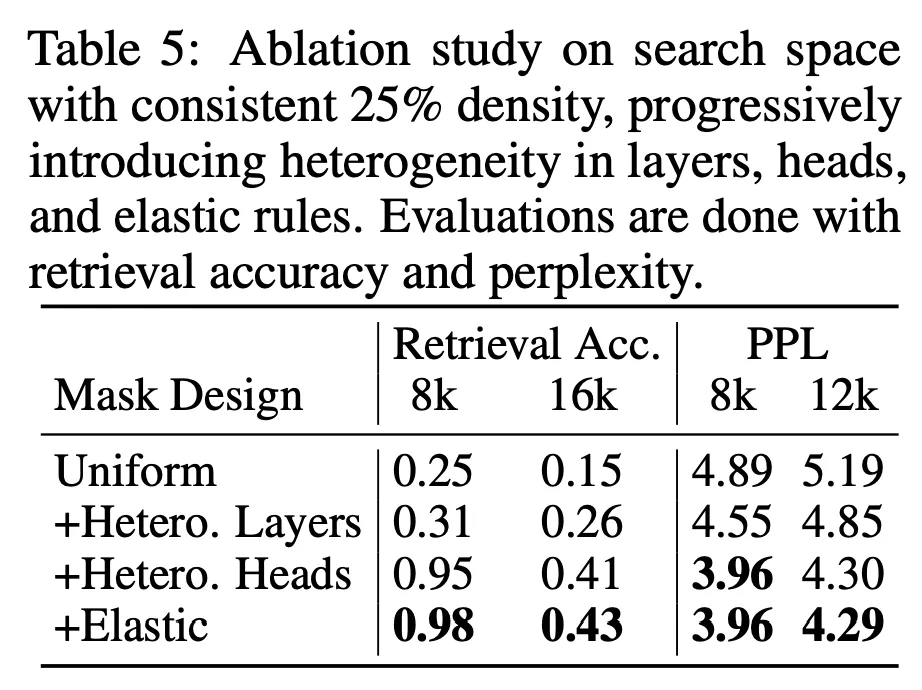
在 25% 注意力密度下对搜索空间进行消融实验。
效率
我们使用 Huggingface 框架支持的 FlashAttention [10] 和 vLLM 框架作为基线,对比 MoA 的效率。
下表比较了 MoA 相对于各种注意力机制和 LLM 框架的运行效率,并对 MoA 的每个设计带来的效率提升进行了消融分析。在 50% 注意力密度下,MoA 相比 FlashAttention2 将解码吞吐量提升了 6.6-8.2 倍。相比 H2O 和 InfLLM,解码吞吐量提升了 1.2-4.0 倍。与包含高度系统级优化的 vLLM 框架 [11] 相比,MoA 仍实现了 1.7-1.9 倍的吞吐量提升。MoA 还将 GPU 总内存减少 1.2 到 1.4 倍。
这些吞吐量的提升来源于四个主要因素:生成过程中的静态 KV-Cache(约 3.0 倍);由于稀疏性减少了注意力计算(约 1.5 倍);较小的 KV-Cache 内存支持了更大的批大小(约 1.4 倍);以及我们针对 MoA 异构注意力所实现的 CUDA GPU 算子优化(约 1.2 倍)。
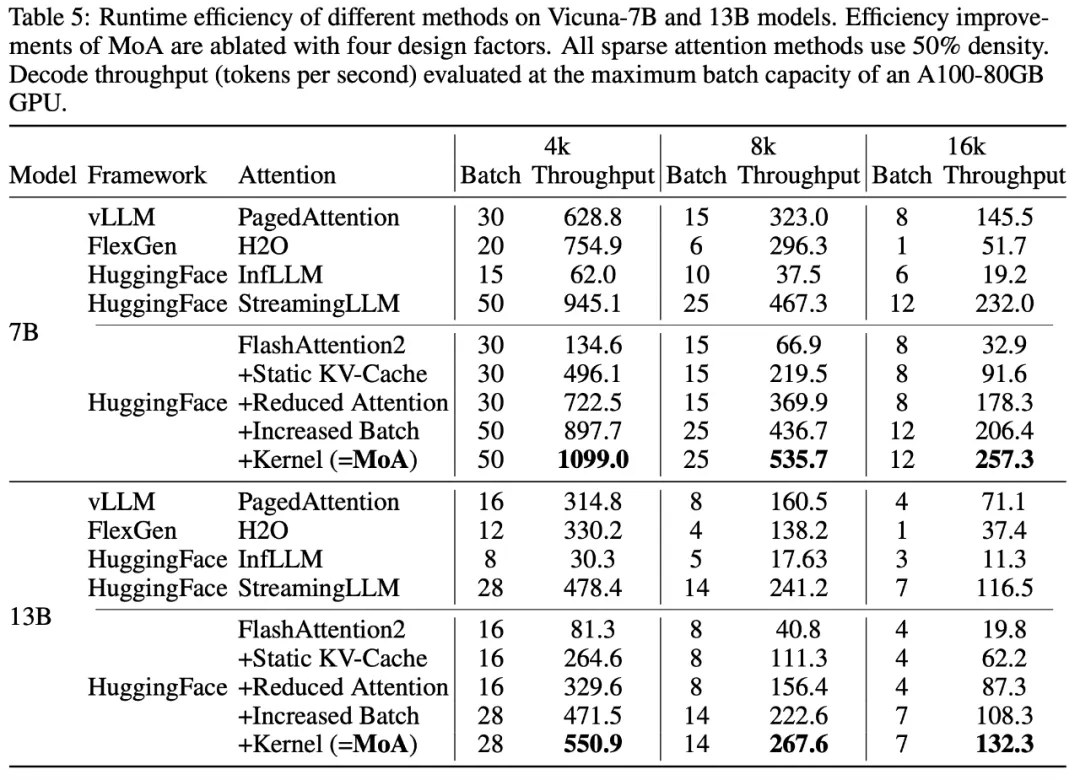
不同框架在7B和13B模型上的效率分析。MoA 每个设计带来的效率提升通过消融分析分为四个部分。所有稀疏注意力方法都使用50%的注意力密度。解码吞吐量在A100-80GB GPU 显存能容纳的最大批大小下进行评估。
本论文的共同一作是清华大学电子工程系 NICS-EFC 实验室的傅天予、黄浩峰和宁雪妃,他们来自 NICS-EFC 实验室的 EffAlg 团队和无问芯穹(Infinigence AI)。NICS-EFC 实验室由汪玉教授带领,实验室的高效算法团队(Efficient Algorithm Team,EffAlg)由宁雪妃助理研究员带领。EffAlg 团队的主要研究方向为高效深度学习技术,团队网站为 https://nics-effalg.com/
[1] Chen, Shouyuan, et al. "Extending Context Window of Large Language Models via Positional Interpolation." ArXiv, 2023, abs/2306.15595, https://api.semanticscholar.org/CorpusID:259262376.
[2] Tworkowski, Szymon, et al. "Focused Transformer: Contrastive Training for Context Scaling." ArXiv, 2023, abs/2307.03170, https://api.semanticscholar.org/CorpusID:259360592.
[3] Vaswani, Ashish, et al. "Attention is all you need." Advances in Neural Information Processing Systems, vol. 30, 2017.
[4] Xiao, Guangxuan, et al. "Efficient Streaming Language Models with Attention Sinks." The Twelfth International Conference on Learning Representations, 2024.
[5] Han, Chi, et al. "Lm-infinite: Simple on-the-fly length generalization for large language models." arXiv preprint arXiv:2308.16137, 2023.
[6] Zaheer, Manzil, et al. "Big bird: Transformers for longer sequences." Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 17283-17297.
[7] Li, Dacheng, et al. "How Long Can Open-Source LLMs Truly Promise on Context Length?" lmsys.org, June 2023, https://lmsys.org/blog/2023-06-29-longchat.
[8] Fu, Yao, et al. "Data Engineering for Scaling Language Models to 128K Context." ArXiv, 2024, abs/2402.10171, https://api.semanticscholar.org/CorpusID:267682361.
[9] Zhang, Zhenyu (Allen), et al. "H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models." ArXiv, 2023, abs/2306.14048, https://api.semanticscholar.org/CorpusID:259263947.
[10] Dao, Tri, et al. "FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness." Advances in Neural Information Processing Systems, 2022.
[11] Kwon, Woosuk, et al. "Efficient Memory Management for Large Language Model Serving with PagedAttention." Proceedings of the 29th Symposium on Operating Systems Principles, 2023, https://api.semanticscholar.org/CorpusID:261697361.
[12] Xiao, Chaojun et al. “InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory.” (2024).
文章来自于微信公众号 “机器之心”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
